Efficient Reinforcement Learning On Passive RRAM Crossbar Array

0
Sign in to get full access
Overview
- This paper explores an efficient reinforcement learning (RL) approach that can be implemented on passive resistive random-access memory (RRAM) crossbar arrays.
- RRAM crossbar arrays offer a promising hardware platform for RL due to their inherent computational and energy efficiency.
- The proposed method aims to overcome the challenges of implementing RL on passive RRAM crossbar arrays, such as the limited resolution and dynamic range of RRAM devices.
Plain English Explanation
Reinforcement learning (RL) is a powerful machine learning technique that allows systems to learn by interacting with their environment and receiving feedback. RL has many potential applications, such as energy-efficient knapsack optimization using probabilistic memristor and model-based deep reinforcement learning for accelerated learning.
However, implementing RL on traditional computer hardware can be computationally and energy-intensive. This is where resistive random-access memory (RRAM) crossbar arrays come in. RRAM crossbar arrays are a type of specialized hardware that can perform computations efficiently and with low power consumption.
The researchers in this paper have developed an efficient RL method that can be implemented on passive RRAM crossbar arrays. This means that the RL algorithm can run directly on the RRAM hardware, without the need for additional, power-hungry processing units. This could lead to significant improvements in the speed and energy efficiency of RL systems, especially for challenges in reinforcement learning for quantum circuit design and practical and efficient quantum circuit synthesis and transpiling.
Technical Explanation
The paper proposes an efficient RL algorithm for passive RRAM crossbar arrays. The key idea is to leverage the intrinsic characteristics of RRAM devices, such as their ability to perform matrix-vector multiplication in a single step, to perform RL computations efficiently.
The researchers develop a modified version of the Q-learning algorithm, a popular RL technique, that can be implemented on passive RRAM crossbar arrays. This involves designing a novel weight update rule that takes into account the limited resolution and dynamic range of RRAM devices, as well as a state representation scheme that can be efficiently mapped to the RRAM crossbar structure.
The proposed method is evaluated on several benchmark RL tasks, demonstrating significant improvements in energy efficiency and computational speed compared to traditional RL approaches running on general-purpose hardware.
Critical Analysis
The research presented in this paper is a promising step towards more efficient RL systems that can take advantage of specialized hardware like RRAM crossbar arrays. The authors have addressed important challenges in implementing RL on passive RRAM crossbar arrays, such as the limited resolution and dynamic range of RRAM devices.
However, the paper also acknowledges several limitations and areas for further research. For example, the proposed method may not be suitable for all types of RL problems, and the impact of hardware non-idealities on the algorithm's performance is not fully explored.
Additionally, the practical deployment of such RL systems on RRAM crossbar arrays may face other challenges, such as the integration of the RL algorithm with the underlying hardware and the management of system-level constraints.
Further research is needed to address these limitations and explore the broader implications of the proposed approach, such as its potential impact on applications that require energy-efficient and low-latency RL, such as swiftRL.
Conclusion
This paper presents an efficient RL algorithm that can be implemented on passive RRAM crossbar arrays, a type of specialized hardware that offers significant computational and energy efficiency advantages over traditional computer systems.
The proposed method addresses several key challenges in implementing RL on passive RRAM crossbar arrays, such as the limited resolution and dynamic range of RRAM devices. The authors demonstrate the performance and efficiency benefits of their approach through experiments on benchmark RL tasks.
While the research has promising implications for the development of more energy-efficient and high-performance RL systems, further work is needed to address the limitations and explore the broader applications of this approach, particularly in domains that require low-latency and energy-efficient RL.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Reinforcement Learning On Passive RRAM Crossbar Array
Arjun Tyagi, Shubham Sahay
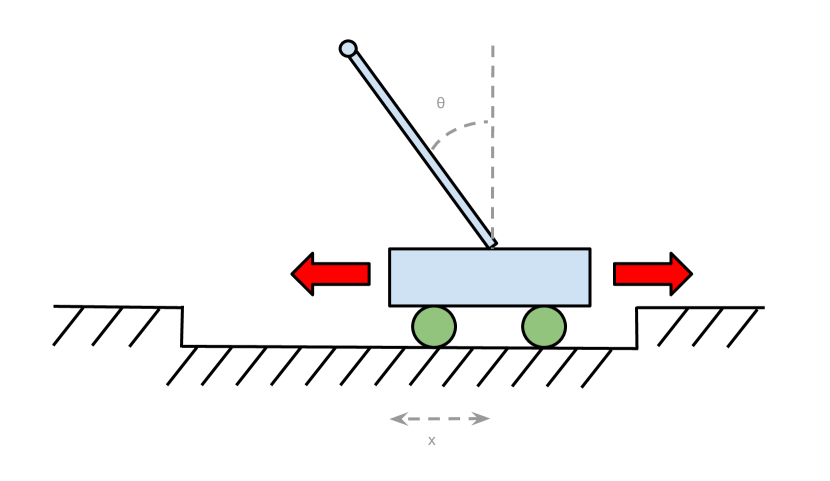
The unprecedented growth in the field of machine learning has led to the development of deep neuromorphic networks trained on labelled dataset with capability to mimic or even exceed human capabilities. However, for applications involving continuous decision making in unknown environments, such as rovers for space exploration, robots, unmanned aerial vehicles, etc., explicit supervision and generation of labelled data set is extremely difficult and expensive. Reinforcement learning (RL) allows the agents to take decisions without any (human/external) supervision or training on labelled dataset. However, the conventional implementations of RL on advanced digital CPUs/GPUs incur a significantly large power dissipation owing to their inherent von-Neumann architecture. Although crossbar arrays of emerging non-volatile memories such as resistive (R)RAMs with their innate capability to perform energy-efficient in situ multiply-accumulate operation appear promising for Q-learning-based RL implementations, their limited endurance restricts their application in practical RL systems with overwhelming weight updates. To address this issue and realize the true potential of RRAM-based RL implementations, in this work, for the first time, we perform an algorithm-hardware co-design and propose a novel implementation of Monte Carlo (MC) RL algorithm on passive RRAM crossbar array. We analyse the performance of the proposed MC RL implementation on the classical cart-pole problem and demonstrate that it not only outperforms the prior digital and active 1-Transistor-1-RRAM (1T1R)-based implementations by more than five orders of magnitude in terms of area but is also robust against the spatial and temporal variations and endurance failure of RRAMs.
Read more7/12/2024
🏅
0
SwiftRL: Towards Efficient Reinforcement Learning on Real Processing-In-Memory Systems
Kailash Gogineni, Sai Santosh Dayapule, Juan G'omez-Luna, Karthikeya Gogineni, Peng Wei, Tian Lan, Mohammad Sadrosadati, Onur Mutlu, Guru Venkataramani
Reinforcement Learning (RL) trains agents to learn optimal behavior by maximizing reward signals from experience datasets. However, RL training often faces memory limitations, leading to execution latencies and prolonged training times. To overcome this, SwiftRL explores Processing-In-Memory (PIM) architectures to accelerate RL workloads. We achieve near-linear performance scaling by implementing RL algorithms like Tabular Q-learning and SARSA on UPMEM PIM systems and optimizing for hardware. Our experiments on OpenAI GYM environments using UPMEM hardware demonstrate superior performance compared to CPU and GPU implementations.
Read more5/8/2024
🛠️
0
Energy Efficient Knapsack Optimization Using Probabilistic Memristor Crossbars
Jinzhan Li, Suhas Kumar, Su-in Yi
Constrained optimization underlies crucial societal problems (for instance, stock trading and bandwidth allocation), but is often computationally hard (complexity grows exponentially with problem size). The big-data era urgently demands low-latency and low-energy optimization at the edge, which cannot be handled by digital processors due to their non-parallel von Neumann architecture. Recent efforts using massively parallel hardware (such as memristor crossbars and quantum processors) employing annealing algorithms, while promising, have handled relatively easy and stable problems with sparse or binary representations (such as the max-cut or traveling salesman problems).However, most real-world applications embody three features, which are encoded in the knapsack problem, and cannot be handled by annealing algorithms - dense and non-binary representations, with destabilizing self-feedback. Here we demonstrate a post-digital-hardware-friendly randomized competitive Ising-inspired (RaCI) algorithm performing knapsack optimization, experimentally implemented on a foundry-manufactured CMOS-integrated probabilistic analog memristor crossbar. Our solution outperforms digital and quantum approaches by over 4 orders of magnitude in energy efficiency.
Read more7/8/2024
🎯
0
Comparative Evaluation of Memory Technologies for Synaptic Crossbar Arrays- Part 2: Design Knobs and DNN Accuracy Trends
Jeffry Victor, Chunguang Wang, Sumeet K. Gupta
Crossbar memory arrays have been touted as the workhorse of in-memory computing (IMC)-based acceleration of Deep Neural Networks (DNNs), but the associated hardware non-idealities limit their efficacy. To address this, cross-layer design solutions that reduce the impact of hardware non-idealities on DNN accuracy are needed. In Part 1 of this paper, we established the co-optimization strategies for various memory technologies and their crossbar arrays, and conducted a comparative technology evaluation in the context of IMC robustness. In this part, we analyze various design knobs such as array size and bit-slice (number of bits per device) and their impact on the performance of 8T SRAM, ferroelectric transistor (FeFET), Resistive RAM (ReRAM) and spin-orbit-torque magnetic RAM (SOT-MRAM) in the context of inference accuracy at 7nm technology node. Further, we study the effect of circuit design solutions such as Partial Wordline Activation (PWA) and custom ADC reference levels that reduce the hardware non-idealities and comparatively analyze the response of each technology to such accuracy enhancing techniques. Our results on ResNet-20 (with CIFAR-10) show that PWA increases accuracy by up to 32.56% while custom ADC reference levels yield up to 31.62% accuracy enhancement. We observe that compared to the other technologies, FeFET, by virtue of its small layout height and high distinguishability of its memory states, is best suited for large arrays. For higher bit-slices and a more complex dataset (ResNet-50 with Cifar-100) we found that ReRAM matches the performance of FeFET.
Read more8/13/2024