SwiftRL: Towards Efficient Reinforcement Learning on Real Processing-In-Memory Systems

0
🏅
Sign in to get full access
Overview
- Reinforcement Learning (RL) trains agents to learn optimal behavior by maximizing reward signals from experience datasets
- RL training often faces memory limitations, leading to execution latencies and prolonged training times
- The paper "SwiftRL" explores Processing-In-Memory (PIM) architectures to accelerate RL workloads
- The researchers achieve near-linear performance scaling by implementing RL algorithms like Tabular Q-learning and SARSA on UPMEM PIM systems and optimizing for hardware
- Experiments on OpenAI GYM environments using UPMEM hardware demonstrate superior performance compared to CPU and GPU implementations
Plain English Explanation
Reinforcement Learning (RL) is a way for computer systems to learn the best actions to take in different situations. The systems get rewards or penalties based on their actions, and over time, they learn to maximize the rewards. However, RL training often runs into memory limitations, which can slow down the training process and make it take a long time.
To overcome this, the researchers in the "SwiftRL" paper looked at using Processing-In-Memory (PIM) architectures to speed up RL workloads. PIM architectures allow for computation to happen right where the data is stored, rather than having to move the data to a separate processor. This can significantly improve performance.
The researchers implemented two popular RL algorithms, Tabular Q-learning and SARSA, on UPMEM PIM systems and optimized them for the hardware. Their experiments on OpenAI GYM environments, which are standard benchmarks for RL, showed that the PIM-based system performed much better than regular CPUs and GPUs.
Technical Explanation
The researchers in the "SwiftRL" paper explore the use of Processing-In-Memory (PIM) architectures to accelerate Reinforcement Learning (RL) workloads. RL training often faces memory limitations, leading to execution latencies and prolonged training times.
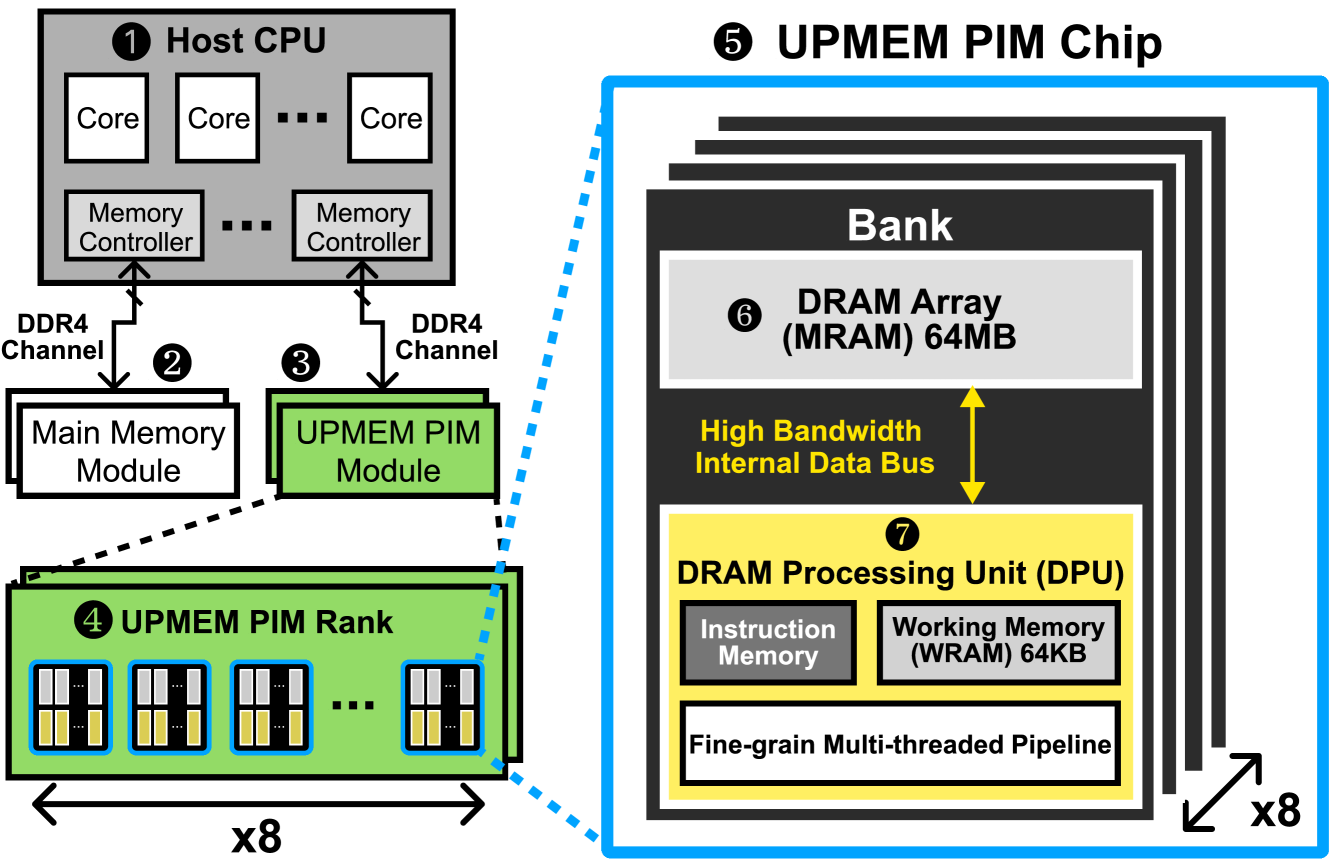
To address this, the researchers implement two popular RL algorithms, Tabular Q-learning and SARSA, on UPMEM PIM systems and optimize them for the hardware. UPMEM is a PIM architecture that allows for computation to be performed directly on the memory, reducing the need to move data between the processor and memory.
The researchers' experiments on OpenAI GYM environments, which are standard benchmarks for RL, demonstrate near-linear performance scaling and superior performance compared to CPU and GPU implementations. This is due to the researchers' careful optimization of the RL algorithms for the UPMEM PIM architecture, allowing them to take advantage of the reduced data movement and increased parallelism offered by PIM systems.
Critical Analysis
The "SwiftRL" paper presents a promising approach to accelerating Reinforcement Learning (RL) workloads using Processing-In-Memory (PIM) architectures. By implementing RL algorithms directly on UPMEM PIM systems and optimizing for the hardware, the researchers are able to achieve significant performance improvements over traditional CPU and GPU implementations.
However, the paper does not address some potential limitations or areas for further research. For example, the researchers only evaluate the performance on standard OpenAI GYM environments, which may not fully capture the complexities of real-world RL applications. Additionally, the paper does not discuss the energy efficiency or hardware costs of the UPMEM PIM system, which could be important factors for real-world deployment.
Furthermore, the researchers may want to explore how their PIM-based approach could be combined with other techniques, such as learning-based acceleration or GPU-accelerated RL, to further improve performance and efficiency.
Overall, the "SwiftRL" paper demonstrates the potential of PIM architectures to accelerate RL workloads, but there may be opportunities to build upon this research and address some of the potential limitations.
Conclusion
The "SwiftRL" paper presents a novel approach to accelerating Reinforcement Learning (RL) workloads using Processing-In-Memory (PIM) architectures. By implementing RL algorithms directly on UPMEM PIM systems and optimizing for the hardware, the researchers are able to achieve near-linear performance scaling and superior performance compared to traditional CPU and GPU implementations.
This work has important implications for the field of RL, as it suggests that PIM architectures could be a promising approach to overcoming the memory limitations that often hinder RL training. Additionally, the researchers' optimizations for the UPMEM hardware could serve as a model for how to effectively leverage model-based deep reinforcement learning to accelerate a wide range of RL applications.
Overall, the "SwiftRL" paper demonstrates the potential of PIM architectures to drive significant advancements in the field of Reinforcement Learning, and it will be interesting to see how this research evolves and is applied in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
SwiftRL: Towards Efficient Reinforcement Learning on Real Processing-In-Memory Systems
Kailash Gogineni, Sai Santosh Dayapule, Juan G'omez-Luna, Karthikeya Gogineni, Peng Wei, Tian Lan, Mohammad Sadrosadati, Onur Mutlu, Guru Venkataramani
Reinforcement Learning (RL) trains agents to learn optimal behavior by maximizing reward signals from experience datasets. However, RL training often faces memory limitations, leading to execution latencies and prolonged training times. To overcome this, SwiftRL explores Processing-In-Memory (PIM) architectures to accelerate RL workloads. We achieve near-linear performance scaling by implementing RL algorithms like Tabular Q-learning and SARSA on UPMEM PIM systems and optimizing for hardware. Our experiments on OpenAI GYM environments using UPMEM hardware demonstrate superior performance compared to CPU and GPU implementations.
Read more5/8/2024
0
Efficient Reinforcement Learning On Passive RRAM Crossbar Array
Arjun Tyagi, Shubham Sahay
The unprecedented growth in the field of machine learning has led to the development of deep neuromorphic networks trained on labelled dataset with capability to mimic or even exceed human capabilities. However, for applications involving continuous decision making in unknown environments, such as rovers for space exploration, robots, unmanned aerial vehicles, etc., explicit supervision and generation of labelled data set is extremely difficult and expensive. Reinforcement learning (RL) allows the agents to take decisions without any (human/external) supervision or training on labelled dataset. However, the conventional implementations of RL on advanced digital CPUs/GPUs incur a significantly large power dissipation owing to their inherent von-Neumann architecture. Although crossbar arrays of emerging non-volatile memories such as resistive (R)RAMs with their innate capability to perform energy-efficient in situ multiply-accumulate operation appear promising for Q-learning-based RL implementations, their limited endurance restricts their application in practical RL systems with overwhelming weight updates. To address this issue and realize the true potential of RRAM-based RL implementations, in this work, for the first time, we perform an algorithm-hardware co-design and propose a novel implementation of Monte Carlo (MC) RL algorithm on passive RRAM crossbar array. We analyse the performance of the proposed MC RL implementation on the classical cart-pole problem and demonstrate that it not only outperforms the prior digital and active 1-Transistor-1-RRAM (1T1R)-based implementations by more than five orders of magnitude in terms of area but is also robust against the spatial and temporal variations and endurance failure of RRAMs.
Read more7/12/2024
0
Analysis of Distributed Optimization Algorithms on a Real Processing-In-Memory System
Steve Rhyner, Haocong Luo, Juan G'omez-Luna, Mohammad Sadrosadati, Jiawei Jiang, Ataberk Olgun, Harshita Gupta, Ce Zhang, Onur Mutlu
Machine Learning (ML) training on large-scale datasets is a very expensive and time-consuming workload. Processor-centric architectures (e.g., CPU, GPU) commonly used for modern ML training workloads are limited by the data movement bottleneck, i.e., due to repeatedly accessing the training dataset. As a result, processor-centric systems suffer from performance degradation and high energy consumption. Processing-In-Memory (PIM) is a promising solution to alleviate the data movement bottleneck by placing the computation mechanisms inside or near memory. Our goal is to understand the capabilities and characteristics of popular distributed optimization algorithms on real-world PIM architectures to accelerate data-intensive ML training workloads. To this end, we 1) implement several representative centralized distributed optimization algorithms on UPMEM's real-world general-purpose PIM system, 2) rigorously evaluate these algorithms for ML training on large-scale datasets in terms of performance, accuracy, and scalability, 3) compare to conventional CPU and GPU baselines, and 4) discuss implications for future PIM hardware and the need to shift to an algorithm-hardware codesign perspective to accommodate decentralized distributed optimization algorithms. Our results demonstrate three major findings: 1) Modern general-purpose PIM architectures can be a viable alternative to state-of-the-art CPUs and GPUs for many memory-bound ML training workloads, when operations and datatypes are natively supported by PIM hardware, 2) the importance of carefully choosing the optimization algorithm that best fit PIM, and 3) contrary to popular belief, contemporary PIM architectures do not scale approximately linearly with the number of nodes for many data-intensive ML training workloads. To facilitate future research, we aim to open-source our complete codebase.
Read more4/11/2024

0
UpDLRM: Accelerating Personalized Recommendation using Real-World PIM Architecture
Sitian Chen, Haobin Tan, Amelie Chi Zhou, Yusen Li, Pavan Balaji
Deep Learning Recommendation Models (DLRMs) have gained popularity in recommendation systems due to their effectiveness in handling large-scale recommendation tasks. The embedding layers of DLRMs have become the performance bottleneck due to their intensive needs on memory capacity and memory bandwidth. In this paper, we propose UpDLRM, which utilizes real-world processingin-memory (PIM) hardware, UPMEM DPU, to boost the memory bandwidth and reduce recommendation latency. The parallel nature of the DPU memory can provide high aggregated bandwidth for the large number of irregular memory accesses in embedding lookups, thus offering great potential to reduce the inference latency. To fully utilize the DPU memory bandwidth, we further studied the embedding table partitioning problem to achieve good workload-balance and efficient data caching. Evaluations using real-world datasets show that, UpDLRM achieves much lower inference time for DLRM compared to both CPU-only and CPU-GPU hybrid counterparts.
Read more6/21/2024