Understanding Transferable Representation Learning and Zero-shot Transfer in CLIP

0
🤔
Sign in to get full access
Overview
- Multi-modal learning, which combines information from different data sources like text and images, has become popular for improving model performance.
- CLIP, a recent approach, uses vision-language contrastive pretraining to learn joint image and text representations, enabling impressive zero-shot learning and text-guided image generation.
- Despite CLIP's practical success, its underlying theoretical understanding remains unclear.
Plain English Explanation
Multi-modal learning refers to using different types of data, such as text and images, to train a single model. This can be more effective than using a single data type, as the model can learn from the complementary information in the various sources.
CLIP is a new approach that trains a model to understand the relationship between images and the text that describes them. It does this by showing the model many image-text pairs and having it learn to match the images and text. Once trained, the model can then be used for tasks like generating images based on text descriptions or classifying images without needing labeled training data.
While CLIP has been very successful in practical applications, researchers are still trying to fully understand how it works and why it performs so well. This paper aims to shed light on the underlying mechanisms behind CLIP's transferable representation learning and its zero-shot transfer capabilities.
Inspired by their analysis, the researchers also propose a new CLIP-like approach that outperforms CLIP and other state-of-the-art methods on benchmark datasets.
Technical Explanation
This paper provides a formal study of the transferrable representation learning underlying CLIP and demonstrates how features from different modalities (e.g., text and images) become aligned. The researchers also analyze CLIP's zero-shot transfer performance on downstream tasks.
The key insights from their analysis include:
- Modality Alignment: The paper shows how CLIP's contrastive pretraining aligns the representations of images and their corresponding text descriptions, allowing the model to effectively transfer knowledge between modalities.
- Zero-Shot Transfer: The researchers examine how CLIP's learned representations enable strong zero-shot performance on various tasks, where the model can make predictions without any labeled training data.
Inspired by these findings, the authors propose a new CLIP-type approach that outperforms CLIP and other state-of-the-art methods on benchmark datasets. This suggests that further research into the theoretical underpinnings of CLIP-like models could lead to even more capable and robust multi-modal learning systems.
Critical Analysis
The paper provides valuable insights into the inner workings of CLIP, which can help advance the theoretical understanding of this and similar multi-modal learning approaches. However, the analysis is limited to CLIP's representation learning and zero-shot transfer capabilities, and does not cover other aspects, such as the model's robustness or sample efficiency.
Additionally, while the proposed CLIP-type approach outperforms CLIP on the benchmarks examined, it is unclear how it would generalize to a wider range of tasks and datasets. Further research is needed to understand the broader implications and limitations of this new method.
It would also be interesting to see how CLIP-like models, including the proposed approach, handle content-style disentanglement or transductive zero-shot and few-shot learning scenarios, which are important capabilities for real-world applications.
Conclusion
This paper provides a detailed analysis of the transferrable representation learning underlying the CLIP model, shedding light on how it aligns features from different modalities and enables strong zero-shot transfer performance. The researchers also propose a new CLIP-type approach that outperforms CLIP and other state-of-the-art methods on benchmark datasets.
These insights contribute to a better theoretical understanding of multi-modal learning models like CLIP, which have shown remarkable practical success. Continued research in this direction could lead to even more capable and robust multi-modal learning systems that can better leverage information from diverse data sources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Understanding Transferable Representation Learning and Zero-shot Transfer in CLIP
Zixiang Chen, Yihe Deng, Yuanzhi Li, Quanquan Gu
Multi-modal learning has become increasingly popular due to its ability to leverage information from different data sources (e.g., text and images) to improve the model performance. Recently, CLIP has emerged as an effective approach that employs vision-language contrastive pretraining to learn joint image and text representations and exhibits remarkable performance in zero-shot learning and text-guided natural image generation. Despite the huge practical success of CLIP, its theoretical understanding remains elusive. In this paper, we formally study transferrable representation learning underlying CLIP and demonstrate how features from different modalities get aligned. We also analyze its zero-shot transfer performance on the downstream tasks. Inspired by our analysis, we propose a new CLIP-type approach, which achieves better performance than CLIP and other state-of-the-art methods on benchmark datasets.
Read more7/12/2024
0
CLIP-Decoder : ZeroShot Multilabel Classification using Multimodal CLIP Aligned Representation
Muhammad Ali, Salman Khan
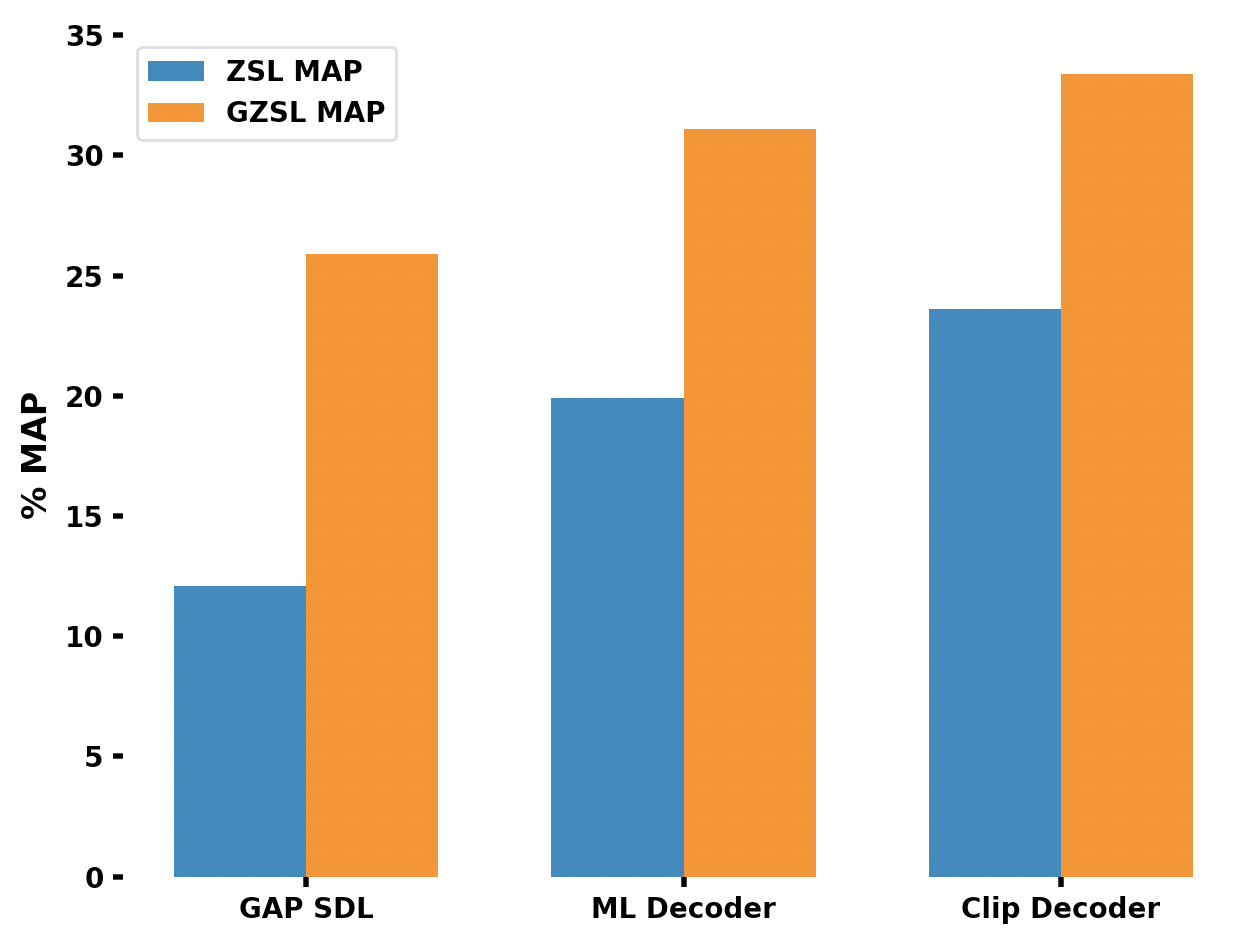
Multi-label classification is an essential task utilized in a wide variety of real-world applications. Multi-label zero-shot learning is a method for classifying images into multiple unseen categories for which no training data is available, while in general zero-shot situations, the test set may include observed classes. The CLIP-Decoder is a novel method based on the state-of-the-art ML-Decoder attention-based head. We introduce multi-modal representation learning in CLIP-Decoder, utilizing the text encoder to extract text features and the image encoder for image feature extraction. Furthermore, we minimize semantic mismatch by aligning image and word embeddings in the same dimension and comparing their respective representations using a combined loss, which comprises classification loss and CLIP loss. This strategy outperforms other methods and we achieve cutting-edge results on zero-shot multilabel classification tasks using CLIP-Decoder. Our method achieves an absolute increase of 3.9% in performance compared to existing methods for zero-shot learning multi-label classification tasks. Additionally, in the generalized zero-shot learning multi-label classification task, our method shows an impressive increase of almost 2.3%.
Read more6/24/2024

0
RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
Read more6/21/2024

0
Multi-Modal Adapter for Vision-Language Models
Dominykas Seputis, Serghei Mihailov, Soham Chatterjee, Zehao Xiao
Large pre-trained vision-language models, such as CLIP, have demonstrated state-of-the-art performance across a wide range of image classification tasks, without requiring retraining. Few-shot CLIP is competitive with existing specialized architectures that were trained on the downstream tasks. Recent research demonstrates that the performance of CLIP can be further improved using lightweight adaptation approaches. However, previous methods adapt different modalities of the CLIP model individually, ignoring the interactions and relationships between visual and textual representations. In this work, we propose Multi-Modal Adapter, an approach for Multi-Modal adaptation of CLIP. Specifically, we add a trainable Multi-Head Attention layer that combines text and image features to produce an additive adaptation of both. Multi-Modal Adapter demonstrates improved generalizability, based on its performance on unseen classes compared to existing adaptation methods. We perform additional ablations and investigations to validate and interpret the proposed approach.
Read more9/6/2024