Eliciting Better Multilingual Structured Reasoning from LLMs through Code
2403.02567
0
0

Abstract
The development of large language models (LLM) has shown progress on reasoning, though studies have largely considered either English or simple reasoning tasks. To address this, we introduce a multilingual structured reasoning and explanation dataset, termed xSTREET, that covers four tasks across six languages. xSTREET exposes a gap in base LLM performance between English and non-English reasoning tasks. We then propose two methods to remedy this gap, building on the insight that LLMs trained on code are better reasoners. First, at training time, we augment a code dataset with multilingual comments using machine translation while keeping program code as-is. Second, at inference time, we bridge the gap between training and inference by employing a prompt structure that incorporates step-by-step code primitives to derive new facts and find a solution. Our methods show improved multilingual performance on xSTREET, most notably on the scientific commonsense reasoning subtask. Furthermore, the models show no regression on non-reasoning tasks, thus demonstrating our techniques maintain general-purpose abilities.
Create account to get full access
Overview
- This paper explores how to elicit better multilingual structured reasoning from large language models (LLMs) through the use of code.
- The researchers investigate the hypothesis that providing code-based prompts can improve the structured reasoning capabilities of LLMs across multiple languages.
- The paper examines related work on using code to enhance LLM reasoning, as well as techniques for improving multilingual reasoning more broadly.
- The researchers design experiments to evaluate the performance of LLMs on structured reasoning tasks when prompted with code versus natural language.
- The findings and insights from this work could have important implications for developing more powerful and versatile LLM-based reasoning systems.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, they can sometimes struggle with tasks that require structured, logical reasoning - for example, solving math problems or making inferences based on facts and rules.
The researchers of this paper explore a novel approach to improve the structured reasoning capabilities of LLMs. Their key idea is to provide the models with code-based prompts, rather than just natural language instructions. The hypothesis is that code can serve as a more effective way to convey the structure and logic needed for these types of reasoning tasks, compared to free-form text.
The paper also looks at ways to make these LLM reasoning systems work well across multiple languages, not just in English. This involves techniques like efficient model finetuning and effective translation of prompts and training data.
Overall, the goal is to develop LLMs that can engage in more sophisticated, structured reasoning - for example, solving complex math problems or making logical inferences. The researchers believe that incorporating code-based prompts is a promising approach to achieving this.
Technical Explanation
The paper first reviews related work on using code to enhance the reasoning capabilities of LLMs, as well as prior efforts to improve multilingual reasoning performance. [This includes research on techniques like question translation and structured understanding to support cross-lingual reasoning.]
The core of the paper describes the researchers' experiments evaluating the impact of code-based prompts on the structured reasoning abilities of LLMs. They design tasks that require logical inference, symbolic manipulation, and other forms of structured reasoning, and compare model performance when prompted with code versus natural language.
The researchers find that providing LLMs with code-based prompts consistently leads to improved reasoning performance, across a range of languages. They analyze the results to better understand the mechanisms behind this benefit, such as the ability of code to more effectively convey the underlying structure and logic of the reasoning process.
The paper also discusses strategies for scaling these techniques to work effectively in a multilingual setting, including the use of model finetuning and efficient translation approaches.
Critical Analysis
The paper presents a compelling approach for enhancing the structured reasoning capabilities of LLMs, but there are some limitations and areas for further research:
- The experiments focus on a relatively narrow set of reasoning tasks, and it's unclear how well the findings would generalize to more diverse or open-ended reasoning problems.
- The paper does not provide a deep analysis of the specific mechanisms by which code-based prompts improve reasoning performance. More research is needed to fully understand the cognitive and architectural factors at play.
- While the multilingual aspect of the research is valuable, the paper does not explore the potential for cross-lingual transfer of reasoning skills. [This is an area that other research has begun to investigate.]
Overall, this paper makes an important contribution to the field of LLM reasoning, but there is still significant room for further exploration and refinement of these techniques.
Conclusion
This paper presents a novel approach to improving the structured reasoning capabilities of large language models (LLMs) by leveraging code-based prompts. The researchers find that providing LLMs with code, rather than just natural language instructions, can lead to significant performance gains on a range of logical inference and symbolic manipulation tasks, across multiple languages.
The insights from this work have important implications for the development of more powerful and versatile LLM-based reasoning systems. By better understanding how to elicit structured reasoning from these models, the research community can work towards creating AI assistants that can tackle complex, logic-intensive problems in a robust and multilingual manner.
While the paper has some limitations, it represents an important step forward in enhancing the reasoning abilities of large language models. Continued research in this direction has the potential to unlock new frontiers in AI-powered problem-solving and decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
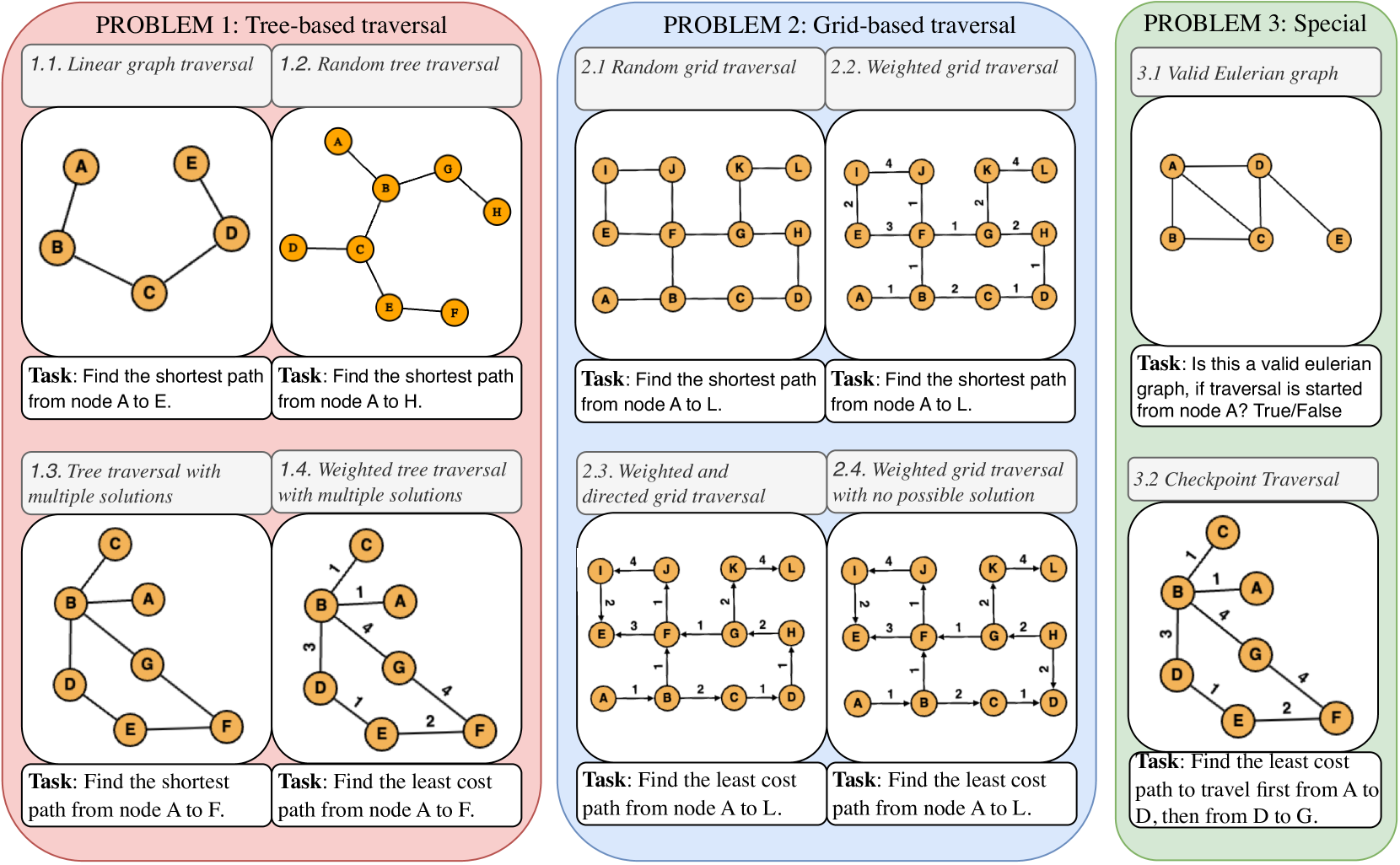
Can LLMs perform structured graph reasoning?
Palaash Agrawal, Shavak Vasania, Cheston Tan
0
0
Pretrained Large Language Models (LLMs) have demonstrated various reasoning capabilities through language-based prompts alone, particularly in unstructured task settings (tasks purely based on language semantics). However, LLMs often struggle with structured tasks, because of the inherent incompatibility of input representation. Reducing structured tasks to uni-dimensional language semantics often renders the problem trivial. Keeping the trade-off between LLM compatibility and structure complexity in mind, we design various graph reasoning tasks as a proxy to semi-structured tasks in this paper, in order to test the ability to navigate through representations beyond plain text in various LLMs. Particularly, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity, and benchmark 5 different instruct-finetuned LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) on the aforementioned tasks. Further, we analyse the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we introduce a new prompting technique specially designed for graph traversal tasks (PathCompare), which demonstrates a notable increase in the performance of LLMs in comparison to standard prompting techniques such as Chain-of-Thought (CoT).
4/19/2024

Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
0
0
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
6/28/2024

Can LLMs Reason in the Wild with Programs?
Yuan Yang, Siheng Xiong, Ali Payani, Ehsan Shareghi, Faramarz Fekri
0
0
Large Language Models (LLMs) have shown superior capability to solve reasoning problems with programs. While being a promising direction, most of such frameworks are trained and evaluated in settings with a prior knowledge of task requirements. However, as LLMs become more capable, it is necessary to assess their reasoning abilities in more realistic scenarios where many real-world problems are open-ended with ambiguous scope, and often require multiple formalisms to solve. To investigate this, we introduce the task of reasoning in the wild, where an LLM is tasked to solve a reasoning problem of unknown type by identifying the subproblems and their corresponding formalisms, and writing a program to solve each subproblem, guided by a tactic. We create a large tactic-guided trajectory dataset containing detailed solutions to a diverse set of reasoning problems, ranging from well-defined single-form reasoning (e.g., math, logic), to ambiguous and hybrid ones (e.g., commonsense, combined math and logic). This allows us to test various aspects of LLMs reasoning at the fine-grained level such as the selection and execution of tactics, and the tendency to take undesired shortcuts. In experiments, we highlight that existing LLMs fail significantly on problems with ambiguous and mixed scope, revealing critical limitations and overfitting issues (e.g. accuracy on GSM8K drops by at least 50%). We further show the potential of finetuning a local LLM on the tactic-guided trajectories in achieving better performance. Project repo is available at github.com/gblackout/Reason-in-the-Wild
6/21/2024

MindMerger: Efficient Boosting LLM Reasoning in non-English Languages
Zixian Huang, Wenhao Zhu, Gong Cheng, Lei Li, Fei Yuan
0
0
Reasoning capabilities are crucial for Large Language Models (LLMs), yet a notable gap exists between English and non-English languages. To bridge this disparity, some works fine-tune LLMs to relearn reasoning capabilities in non-English languages, while others replace non-English inputs with an external model's outputs such as English translation text to circumvent the challenge of LLM understanding non-English. Unfortunately, these methods often underutilize the built-in skilled reasoning and useful language understanding capabilities of LLMs. In order to better utilize the minds of reasoning and language understanding in LLMs, we propose a new method, namely MindMerger, which merges LLMs with the external language understanding capabilities from multilingual models to boost the multilingual reasoning performance. Furthermore, a two-step training scheme is introduced to first train to embeded the external capabilities into LLMs and then train the collaborative utilization of the external capabilities and the built-in capabilities in LLMs. Experiments on three multilingual reasoning datasets and a language understanding dataset demonstrate that MindMerger consistently outperforms all baselines, especially in low-resource languages. Without updating the parameters of LLMs, the average accuracy improved by 6.7% and 8.0% across all languages and low-resource languages on the MGSM dataset, respectively.
5/28/2024