Embracing Federated Learning: Enabling Weak Client Participation via Partial Model Training

0

Sign in to get full access
Overview
- This paper proposes a novel approach to federated learning that enables weak client participation through partial model training.
- The goal is to make federated learning more accessible to a wider range of devices, including those with limited computational resources.
- The approach involves training only a subset of the model parameters on client devices, reducing the computational burden and allowing for greater participation.
Plain English Explanation
Federated learning is a way for AI models to be trained using data from many different devices, without the data having to be centralized. This is useful for protecting privacy and reducing data communication costs. However, some devices may not have enough computing power to fully train the AI model. This paper presents a solution that allows these weaker devices to still participate by only training a partial version of the model.
The key idea is that the AI model can be divided into different parts, and the weaker devices only need to train the easier parts. This reduces the computational load on the device, making it possible for more devices to contribute to the federated learning process. Other approaches have tried to address this issue, but this paper proposes a more flexible and efficient solution.
Technical Explanation
The paper proposes a "partial model training" approach to federated learning. Instead of requiring each client device to train the full AI model, the model is divided into different components or "blocks". Clients then only train a subset of these blocks, reducing the computational burden.
The server coordinates this process, determining which blocks each client should train based on their capabilities. After each round of training, the server aggregates the partial model updates from the clients and updates the full global model. This allows weaker devices to meaningfully contribute to the federated learning process.
The paper demonstrates the effectiveness of this approach through experiments on benchmark datasets. Compared to standard federated learning, the partial model training approach achieves similar model performance while enabling a larger number of client devices to participate. This can lead to faster model convergence and better overall performance.
Critical Analysis
The paper provides a compelling solution to the challenge of enabling weaker devices to participate in federated learning. By only requiring clients to train a subset of the model, it lowers the computational barrier to entry and can lead to more diverse and representative data being used to train the global model.
However, the paper does not deeply explore the potential downsides or limitations of this approach. For example, it's unclear how the choice of which model components to assign to each client affects the final model quality. There may also be challenges in coordinating the partial training process at scale, especially if client device capabilities are highly heterogeneous.
Additionally, the paper does not discuss how this approach would work in more flexible federated learning architectures. Integrating partial model training with other federated learning techniques could lead to further improvements in accessibility and performance.
Conclusion
This paper presents an innovative solution to a key challenge in federated learning - enabling weaker client devices to meaningfully participate. By allowing clients to train only a subset of the model parameters, it reduces the computational burden and opens up federated learning to a wider range of devices.
The experimental results demonstrate the effectiveness of this approach, showing that it can achieve similar model performance to standard federated learning while increasing the number of participating clients. This has important implications for making federated learning more accessible and inclusive, ultimately leading to better AI models that are trained on more diverse and representative data.
While the paper does not fully explore the limitations and potential complexities of this approach, it represents an important step forward in advancing the field of federated learning. Further research and development in this area could unlock even greater opportunities for collaborative, privacy-preserving AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Embracing Federated Learning: Enabling Weak Client Participation via Partial Model Training
Sunwoo Lee, Tuo Zhang, Saurav Prakash, Yue Niu, Salman Avestimehr
In Federated Learning (FL), clients may have weak devices that cannot train the full model or even hold it in their memory space. To implement large-scale FL applications, thus, it is crucial to develop a distributed learning method that enables the participation of such weak clients. We propose EmbracingFL, a general FL framework that allows all available clients to join the distributed training regardless of their system resource capacity. The framework is built upon a novel form of partial model training method in which each client trains as many consecutive output-side layers as its system resources allow. Our study demonstrates that EmbracingFL encourages each layer to have similar data representations across clients, improving FL efficiency. The proposed partial model training method guarantees convergence to a neighbor of stationary points for non-convex and smooth problems. We evaluate the efficacy of EmbracingFL under a variety of settings with a mixed number of strong, moderate (~40% memory), and weak (~15% memory) clients, datasets (CIFAR-10, FEMNIST, and IMDB), and models (ResNet20, CNN, and LSTM). Our empirical study shows that EmbracingFL consistently achieves high accuracy as like all clients are strong, outperforming the state-of-the-art width reduction methods (i.e. HeteroFL and FjORD).
Read more6/24/2024
🏅
0
Accelerating Hybrid Federated Learning Convergence under Partial Participation
Jieming Bian, Lei Wang, Kun Yang, Cong Shen, Jie Xu
Over the past few years, Federated Learning (FL) has become a popular distributed machine learning paradigm. FL involves a group of clients with decentralized data who collaborate to learn a common model under the coordination of a centralized server, with the goal of protecting clients' privacy by ensuring that local datasets never leave the clients and that the server only performs model aggregation. However, in realistic scenarios, the server may be able to collect a small amount of data that approximately mimics the population distribution and has stronger computational ability to perform the learning process. To address this, we focus on the hybrid FL framework in this paper. While previous hybrid FL work has shown that the alternative training of clients and server can increase convergence speed, it has focused on the scenario where clients fully participate and ignores the negative effect of partial participation. In this paper, we provide theoretical analysis of hybrid FL under clients' partial participation to validate that partial participation is the key constraint on convergence speed. We then propose a new algorithm called FedCLG, which investigates the two-fold role of the server in hybrid FL. Firstly, the server needs to process the training steps using its small amount of local datasets. Secondly, the server's calculated gradient needs to guide the participated clients' training and the server's aggregation. We validate our theoretical findings through numerical experiments, which show that our proposed method FedCLG outperforms state-of-the-art methods.
Read more5/21/2024
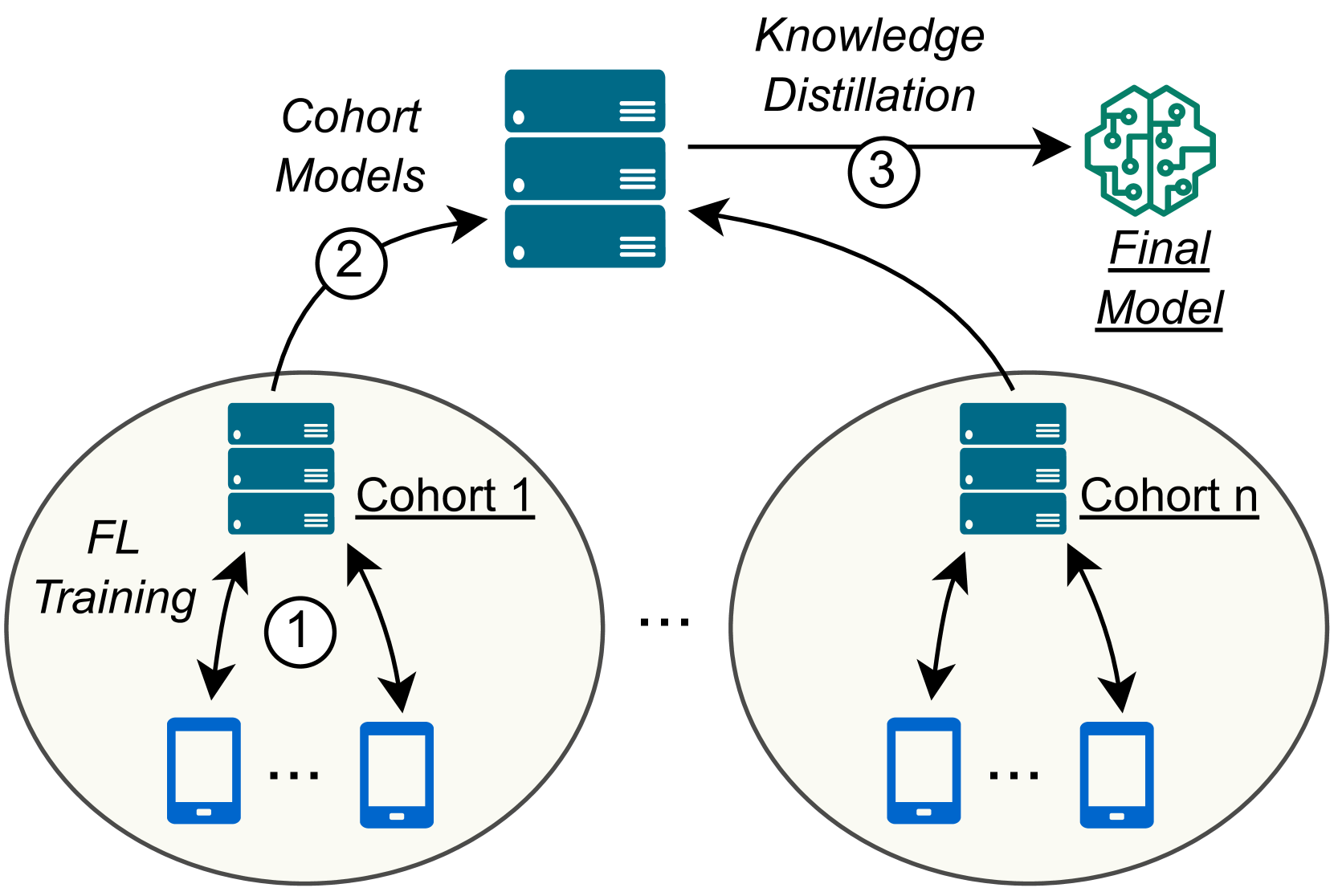
0
Harnessing Increased Client Participation with Cohort-Parallel Federated Learning
Akash Dhasade, Anne-Marie Kermarrec, Tuan-Anh Nguyen, Rafael Pires, Martijn de Vos
Federated Learning (FL) is a machine learning approach where nodes collaboratively train a global model. As more nodes participate in a round of FL, the effectiveness of individual model updates by nodes also diminishes. In this study, we increase the effectiveness of client updates by dividing the network into smaller partitions, or cohorts. We introduce Cohort-Parallel Federated Learning (CPFL): a novel learning approach where each cohort independently trains a global model using FL, until convergence, and the produced models by each cohort are then unified using one-shot Knowledge Distillation (KD) and a cross-domain, unlabeled dataset. The insight behind CPFL is that smaller, isolated networks converge quicker than in a one-network setting where all nodes participate. Through exhaustive experiments involving realistic traces and non-IID data distributions on the CIFAR-10 and FEMNIST image classification tasks, we investigate the balance between the number of cohorts, model accuracy, training time, and compute and communication resources. Compared to traditional FL, CPFL with four cohorts, non-IID data distribution, and CIFAR-10 yields a 1.9$times$ reduction in train time and a 1.3$times$ reduction in resource usage, with a minimal drop in test accuracy.
Read more5/27/2024
📈
0
NeFL: Nested Model Scaling for Federated Learning with System Heterogeneous Clients
Honggu Kang, Seohyeon Cha, Jinwoo Shin, Jongmyeong Lee, Joonhyuk Kang
Federated learning (FL) enables distributed training while preserving data privacy, but stragglers-slow or incapable clients-can significantly slow down the total training time and degrade performance. To mitigate the impact of stragglers, system heterogeneity, including heterogeneous computing and network bandwidth, has been addressed. While previous studies have addressed system heterogeneity by splitting models into submodels, they offer limited flexibility in model architecture design, without considering potential inconsistencies arising from training multiple submodel architectures. We propose nested federated learning (NeFL), a generalized framework that efficiently divides deep neural networks into submodels using both depthwise and widthwise scaling. To address the inconsistency arising from training multiple submodel architectures, NeFL decouples a subset of parameters from those being trained for each submodel. An averaging method is proposed to handle these decoupled parameters during aggregation. NeFL enables resource-constrained devices to effectively participate in the FL pipeline, facilitating larger datasets for model training. Experiments demonstrate that NeFL achieves performance gain, especially for the worst-case submodel compared to baseline approaches (7.63% improvement on CIFAR-100). Furthermore, NeFL aligns with recent advances in FL, such as leveraging pre-trained models and accounting for statistical heterogeneity. Our code is available online.
Read more9/11/2024