EmbSpatial-Bench: Benchmarking Spatial Understanding for Embodied Tasks with Large Vision-Language Models
2406.05756
0
0

Abstract
The recent rapid development of Large Vision-Language Models (LVLMs) has indicated their potential for embodied tasks.However, the critical skill of spatial understanding in embodied environments has not been thoroughly evaluated, leaving the gap between current LVLMs and qualified embodied intelligence unknown. Therefore, we construct EmbSpatial-Bench, a benchmark for evaluating embodied spatial understanding of LVLMs.The benchmark is automatically derived from embodied scenes and covers 6 spatial relationships from an egocentric perspective.Experiments expose the insufficient capacity of current LVLMs (even GPT-4V). We further present EmbSpatial-SFT, an instruction-tuning dataset designed to improve LVLMs' embodied spatial understanding.
Create account to get full access
Overview
- This paper presents EmbSpatial-Bench, a new benchmark for evaluating the spatial understanding capabilities of large vision-language models in embodied tasks.
- The benchmark includes a diverse set of real-world spatial reasoning tasks, such as reframing-spatial-reasoning-evaluation-language-models-real and evaluating-spatial-understanding-large-language-models, which are designed to test the models' ability to understand and reason about spatial relationships.
- The authors evaluate the performance of several state-of-the-art vision-language models on EmbSpatial-Bench and provide insights into the strengths and limitations of these models in spatial understanding.
Plain English Explanation
The paper introduces a new tool called EmbSpatial-Bench that can be used to test how well large language and vision models understand spatial relationships in the real world. Spatial understanding is an important capability for AI systems, as it allows them to better navigate and interact with their environment.
EmbSpatial-Bench includes a variety of tasks that assess different aspects of spatial reasoning, such as evaluating-large-vision-language-models-understanding-real and exploring-spatial-schema-intuitions-large-language. The authors use this benchmark to evaluate the performance of several state-of-the-art vision-language models, which are AI systems that can understand and generate text based on visual information.
The results provide insights into the strengths and weaknesses of these models when it comes to spatial understanding. This information can help researchers and developers improve the spatial reasoning capabilities of AI systems, which could lead to better performance in tasks like reframing-spatial-reasoning-evaluation-language-models-real and effectiveness-assessment-recent-large-vision-language-models.
Technical Explanation
The paper introduces EmbSpatial-Bench, a new benchmark designed to evaluate the spatial understanding capabilities of large vision-language models in embodied tasks. The benchmark includes a diverse set of real-world spatial reasoning tasks, such as reframing-spatial-reasoning-evaluation-language-models-real and evaluating-spatial-understanding-large-language-models, which are designed to test the models' ability to understand and reason about spatial relationships.
The authors evaluate the performance of several state-of-the-art vision-language models, including CLIP, ALBEF, and ViLT, on the EmbSpatial-Bench tasks. They find that while these models demonstrate strong performance on some spatial reasoning tasks, they struggle with others, particularly those that require more nuanced or contextual understanding of spatial relationships.
The paper also presents a detailed analysis of the models' performance, identifying strengths, weaknesses, and potential areas for improvement. For example, the authors note that the models tend to perform well on tasks that rely on exploring-spatial-schema-intuitions-large-language, but struggle with tasks that require more complex spatial reasoning or evaluating-large-vision-language-models-understanding-real understanding.
Critical Analysis
The paper provides a valuable contribution to the field of spatial reasoning in AI by introducing a comprehensive benchmark for evaluating the spatial understanding capabilities of large vision-language models. The authors have carefully designed the EmbSpatial-Bench tasks to cover a range of real-world spatial reasoning challenges, which is an important step towards effectiveness-assessment-recent-large-vision-language-models.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that the current benchmark focuses on static spatial relationships and may not fully capture the dynamic nature of real-world spatial understanding. Additionally, the paper suggests that future work could explore the use of reframing-spatial-reasoning-evaluation-language-models-real techniques to further improve the assessment of spatial reasoning capabilities.
It would also be interesting to see the authors investigate the underlying reasons for the models' performance on the different tasks, as this could provide valuable insights into the specific strengths and weaknesses of different approaches to spatial understanding in AI.
Conclusion
The EmbSpatial-Bench benchmark presented in this paper represents a significant advancement in the field of spatial understanding for embodied AI systems. By providing a comprehensive set of real-world spatial reasoning tasks, the authors have created a valuable tool for evaluating the capabilities of large vision-language models in this critical domain.
The insights gained from the evaluation of state-of-the-art models on EmbSpatial-Bench can inform future research and development efforts, ultimately leading to the creation of AI systems with more robust and nuanced spatial understanding. This could have far-reaching implications for effectiveness-assessment-recent-large-vision-language-models and a wide range of applications where spatial reasoning is essential, such as robotics, navigation, and assistive technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SpatialBot: Precise Spatial Understanding with Vision Language Models
Wenxiao Cai, Yaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, Bo Zhao
0
0
Vision Language Models (VLMs) have achieved impressive performance in 2D image understanding, however they are still struggling with spatial understanding which is the foundation of Embodied AI. In this paper, we propose SpatialBot for better spatial understanding by feeding both RGB and depth images. Additionally, we have constructed the SpatialQA dataset, which involves multi-level depth-related questions to train VLMs for depth understanding. Finally, we present SpatialBench to comprehensively evaluate VLMs' capabilities in spatial understanding at different levels. Extensive experiments on our spatial-understanding benchmark, general VLM benchmarks and Embodied AI tasks, demonstrate the remarkable improvements of SpatialBot trained on SpatialQA. The model, code and data are available at https://github.com/BAAI-DCAI/SpatialBot.
6/28/2024
Exploring Spatial Schema Intuitions in Large Language and Vision Models
Philipp Wicke, Lennart Wachowiak
0
0
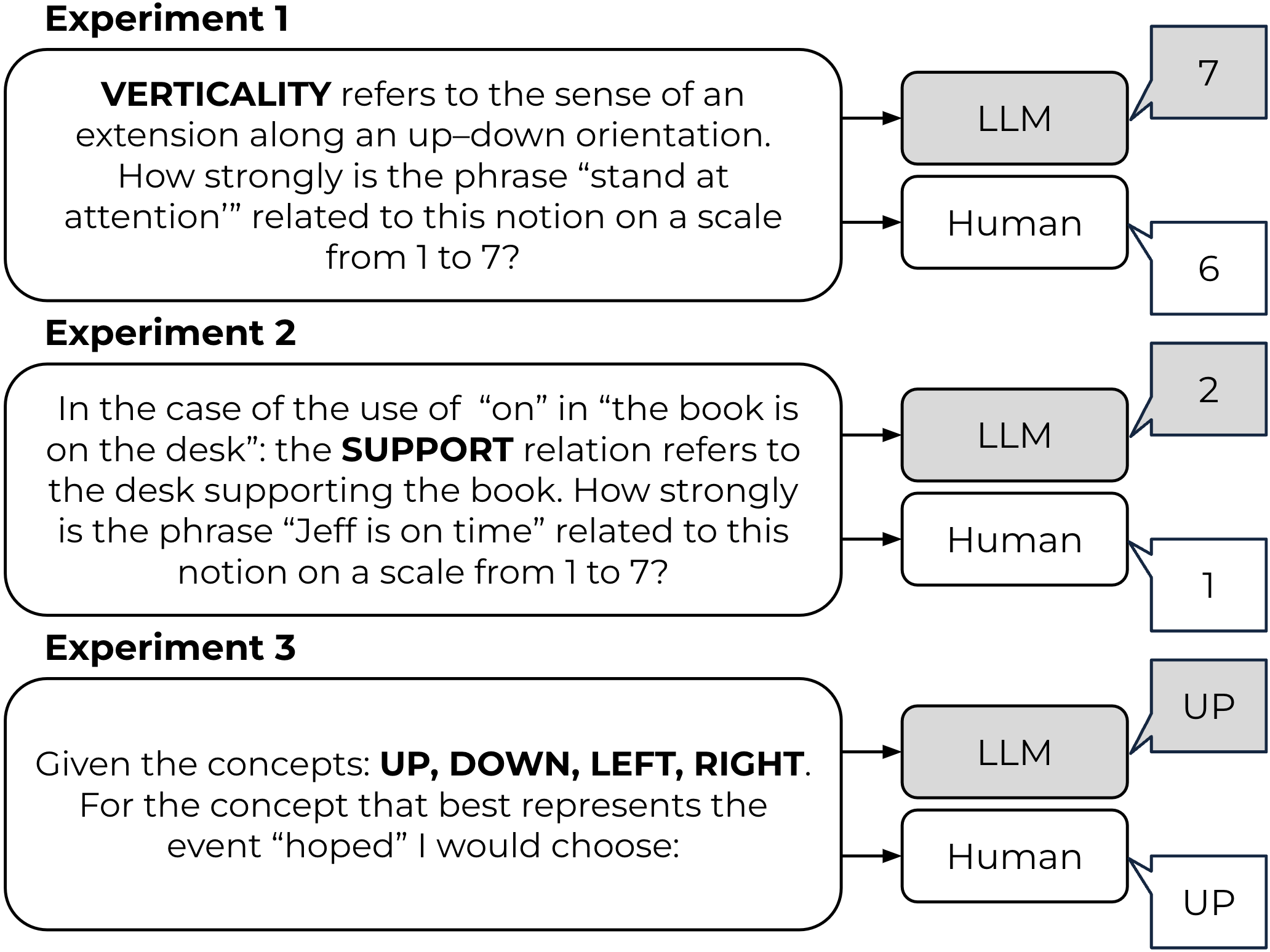
Despite the ubiquity of large language models (LLMs) in AI research, the question of embodiment in LLMs remains underexplored, distinguishing them from embodied systems in robotics where sensory perception directly informs physical action. Our investigation navigates the intriguing terrain of whether LLMs, despite their non-embodied nature, effectively capture implicit human intuitions about fundamental, spatial building blocks of language. We employ insights from spatial cognitive foundations developed through early sensorimotor experiences, guiding our exploration through the reproduction of three psycholinguistic experiments. Surprisingly, correlations between model outputs and human responses emerge, revealing adaptability without a tangible connection to embodied experiences. Notable distinctions include polarized language model responses and reduced correlations in vision language models. This research contributes to a nuanced understanding of the interplay between language, spatial experiences, and the computations made by large language models. More at https://cisnlp.github.io/Spatial_Schemas/
5/28/2024
GSR-BENCH: A Benchmark for Grounded Spatial Reasoning Evaluation via Multimodal LLMs
Navid Rajabi, Jana Kosecka
0
0
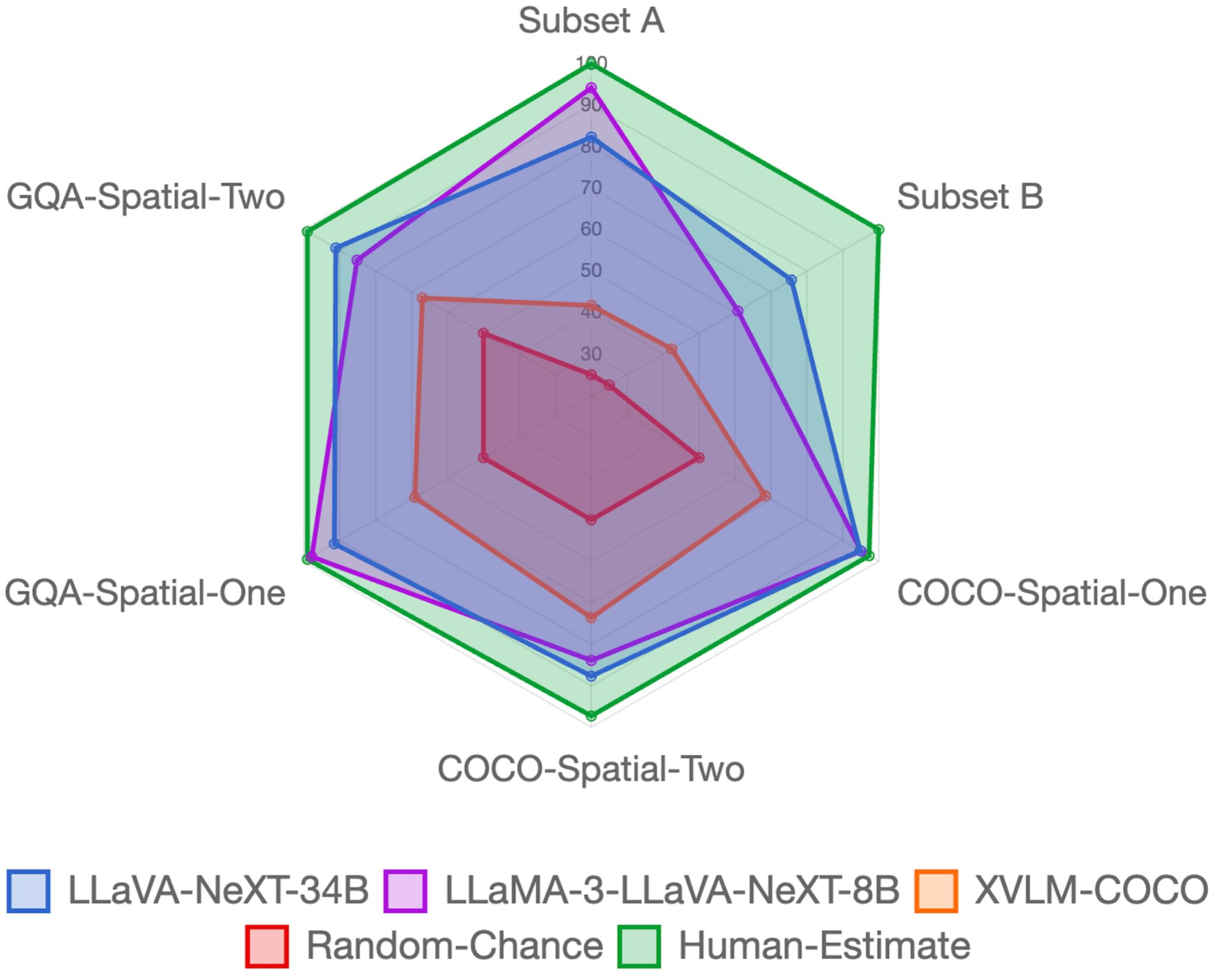
The ability to understand and reason about spatial relationships between objects in images is an important component of visual reasoning. This skill rests on the ability to recognize and localize objects of interest and determine their spatial relation. Early vision and language models (VLMs) have been shown to struggle to recognize spatial relations. We extend the previously released What'sUp dataset and propose a novel comprehensive evaluation for spatial relationship understanding that highlights the strengths and weaknesses of 27 different models. In addition to the VLMs evaluated in What'sUp, our extensive evaluation encompasses 3 classes of Multimodal LLMs (MLLMs) that vary in their parameter sizes (ranging from 7B to 110B), training/instruction-tuning methods, and visual resolution to benchmark their performances and scrutinize the scaling laws in this task.
6/21/2024
New!STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
Wenbin Li, Di Yao, Ruibo Zhao, Wenjie Chen, Zijie Xu, Chengxue Luo, Chang Gong, Quanliang Jing, Haining Tan, Jingping Bi
0
0
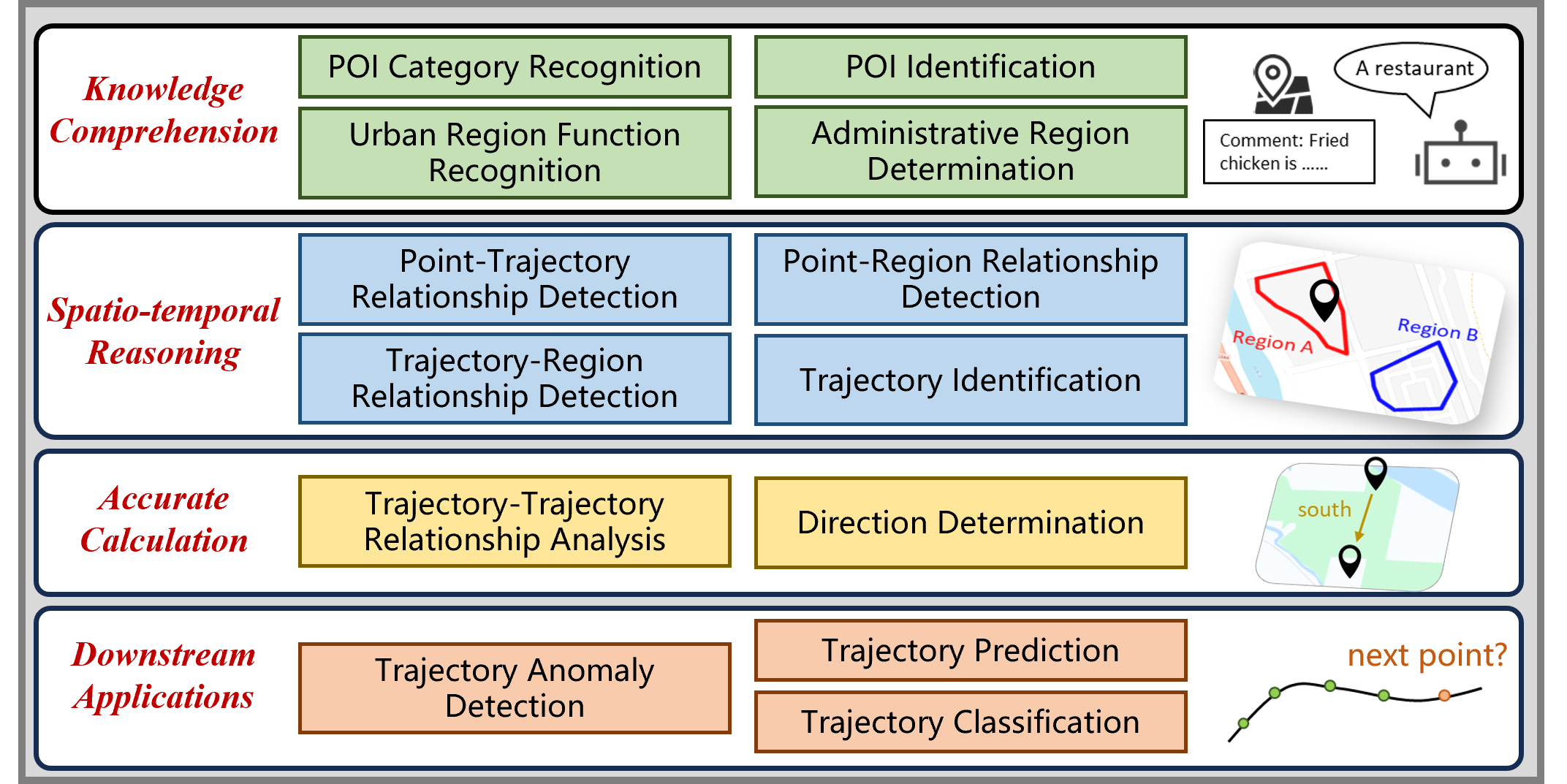
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.
6/28/2024