Emergent Language Symbolic Autoencoder (ELSA) with Weak Supervision to Model Hierarchical Brain Networks

0
💬
Sign in to get full access
Overview
- Brain networks have a hierarchical organization, which poses a challenge for traditional deep learning models that are often structured as flat classifiers
- This can lead to difficulties in interpreting the models and understanding their "black box" nature
- To address this, the researchers propose a novel architecture: a symbolic autoencoder informed by weak supervision and an Emergent Language (EL) framework
- This model goes beyond flat classifiers by producing hierarchical clusters and corresponding imagery, which are then represented through symbolic sentences to improve clinical interpretability
Plain English Explanation
The human brain is organized in a complex, hierarchical way, with different regions working together to perform various functions. However, existing deep learning models are often designed as simple, flat classifiers, which can struggle to capture this hierarchical structure. This can make it difficult to understand how these models work and why they make the decisions they do - the "black box" problem.
To overcome this, the researchers have developed a new approach that is better able to model the hierarchical organization of the brain. Their model takes brain imaging data, such as functional MRI scans, and learns to organize it into a hierarchical structure. It then uses this hierarchy to generate both images and symbolic sentences that represent the different levels of brain activity. This allows researchers and clinicians to better understand how the model is interpreting the brain data, making it more transparent and interpretable.
The researchers' innovation includes a novel loss function that ensures the hierarchical structure is properly captured in both the images and sentences. They also introduce a way to quantitatively assess how well the model is preserving this hierarchical information. Their results show that this approach can achieve a very high level of hierarchical consistency, over 97% in their best-performing model.
This is an important step forward, as it advances the interpretability of deep learning models in the field of neuroimaging analysis. It also represents progress towards better understanding the complex, hierarchical nature of the brain.
Technical Explanation
The researchers' novel architecture is a symbolic autoencoder that combines weak supervision and an Emergent Language (EL) framework. This model goes beyond traditional flat classifiers by producing hierarchical clusters and corresponding imagery, which are then represented through symbolic sentences.
The key innovation is a generalized hierarchical loss function that ensures the hierarchical structure of the brain networks is accurately reflected in both the generated images and sentences. This allows the model to capture the hierarchical organization of functional brain networks, as observed in resting-state fMRI data.
Furthermore, the researchers introduce a quantitative method to assess the hierarchical consistency of these symbolic representations. Their qualitative and quantitative analyses demonstrate that the model successfully generates hierarchically organized, clinically interpretable images and sentences.
The researchers' best-performing model achieves a hierarchical consistency of over 97% when identifying images corresponding to brain networks. This represents a significant advancement in the interpretability of deep learning models applied to neuroimaging analysis, as well as progress towards better understanding the intricate hierarchical nature of brain networks.
Critical Analysis
The researchers acknowledge that their approach is limited to analyzing resting-state fMRI data and may not generalize to other neuroimaging modalities or task-based experiments. Additionally, the quantitative method for assessing hierarchical consistency could be further refined and validated against other metrics or expert-annotated ground truth.
While the model's ability to generate hierarchically organized images and sentences is impressive, the researchers do not provide a detailed evaluation of how clinicians or domain experts would interpret these outputs in practice. More user studies or clinical validation would be helpful to fully assess the model's utility and usability in real-world settings.
Furthermore, the researchers do not discuss the computational complexity or training time of their model, which could be important considerations for practical deployment in clinical or research environments. Exploring ways to improve the efficiency and scalability of the approach would also be a valuable direction for future research.
Overall, the researchers have made a valuable contribution to the field of interpretable deep learning for neuroimaging analysis. By addressing the hierarchical nature of brain networks, their work represents an important step towards bridging the gap between complex biological systems and the flat structures of many deep learning models.
Conclusion
The researchers have proposed a novel symbolic autoencoder architecture that can model the hierarchical organization of brain networks. By generating hierarchical clusters, corresponding imagery, and symbolic sentences, this approach significantly improves the interpretability of deep learning models applied to neuroimaging data.
The researchers' quantitative and qualitative evaluations demonstrate the model's ability to accurately capture the hierarchical structure of functional brain networks, as observed in resting-state fMRI data. This represents an important advancement in the field of interpretable deep learning, with potential applications in clinical decision-making, neuroscience research, and the broader understanding of complex biological systems.
While the current approach has some limitations, the researchers' work lays the foundation for future research into more powerful and generalizable methods for modeling the hierarchical nature of the brain. Continued progress in this area could lead to significant breakthroughs in our understanding of the human brain and its intricate function.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Emergent Language Symbolic Autoencoder (ELSA) with Weak Supervision to Model Hierarchical Brain Networks
Ammar Ahmed Pallikonda Latheef, Alberto Santamaria-Pang, Craig K Jones, Haris I Sair
Brain networks display a hierarchical organization, a complexity that poses a challenge for existing deep learning models, often structured as flat classifiers, leading to difficulties in interpretability and the 'black box' issue. To bridge this gap, we propose a novel architecture: a symbolic autoencoder informed by weak supervision and an Emergent Language (EL) framework. This model moves beyond traditional flat classifiers by producing hierarchical clusters and corresponding imagery, subsequently represented through symbolic sentences to improve the clinical interpretability of hierarchically organized data such as intrinsic brain networks, which can be characterized using resting-state fMRI images. Our innovation includes a generalized hierarchical loss function designed to ensure that both sentences and images accurately reflect the hierarchical structure of functional brain networks. This enables us to model functional brain networks from a broader perspective down to more granular details. Furthermore, we introduce a quantitative method to assess the hierarchical consistency of these symbolic representations. Our qualitative analyses show that our model successfully generates hierarchically organized, clinically interpretable images, a finding supported by our quantitative evaluations. We find that our best performing loss function leads to a hierarchical consistency of over 97% when identifying images corresponding to brain networks. This approach not only advances the interpretability of deep learning models in neuroimaging analysis but also represents a significant step towards modeling the intricate hierarchical nature of brain networks.
Read more4/17/2024
💬
0
Sparse Autoencoders Enable Scalable and Reliable Circuit Identification in Language Models
Charles O'Neill, Thang Bui
This paper introduces an efficient and robust method for discovering interpretable circuits in large language models using discrete sparse autoencoders. Our approach addresses key limitations of existing techniques, namely computational complexity and sensitivity to hyperparameters. We propose training sparse autoencoders on carefully designed positive and negative examples, where the model can only correctly predict the next token for the positive examples. We hypothesise that learned representations of attention head outputs will signal when a head is engaged in specific computations. By discretising the learned representations into integer codes and measuring the overlap between codes unique to positive examples for each head, we enable direct identification of attention heads involved in circuits without the need for expensive ablations or architectural modifications. On three well-studied tasks - indirect object identification, greater-than comparisons, and docstring completion - the proposed method achieves higher precision and recall in recovering ground-truth circuits compared to state-of-the-art baselines, while reducing runtime from hours to seconds. Notably, we require only 5-10 text examples for each task to learn robust representations. Our findings highlight the promise of discrete sparse autoencoders for scalable and efficient mechanistic interpretability, offering a new direction for analysing the inner workings of large language models.
Read more5/22/2024
👀
0
A Neuro-Symbolic Explainer for Rare Events: A Case Study on Predictive Maintenance
Jo~ao Gama, Rita P. Ribeiro, Saulo Mastelini, Narjes Davarid, Bruno Veloso
Predictive Maintenance applications are increasingly complex, with interactions between many components. Black box models are popular approaches based on deep learning techniques due to their predictive accuracy. This paper proposes a neural-symbolic architecture that uses an online rule-learning algorithm to explain when the black box model predicts failures. The proposed system solves two problems in parallel: anomaly detection and explanation of the anomaly. For the first problem, we use an unsupervised state of the art autoencoder. For the second problem, we train a rule learning system that learns a mapping from the input features to the autoencoder reconstruction error. Both systems run online and in parallel. The autoencoder signals an alarm for the examples with a reconstruction error that exceeds a threshold. The causes of the signal alarm are hard for humans to understand because they result from a non linear combination of sensor data. The rule that triggers that example describes the relationship between the input features and the autoencoder reconstruction error. The rule explains the failure signal by indicating which sensors contribute to the alarm and allowing the identification of the component involved in the failure. The system can present global explanations for the black box model and local explanations for why the black box model predicts a failure. We evaluate the proposed system in a real-world case study of Metro do Porto and provide explanations that illustrate its benefits.
Read more4/24/2024
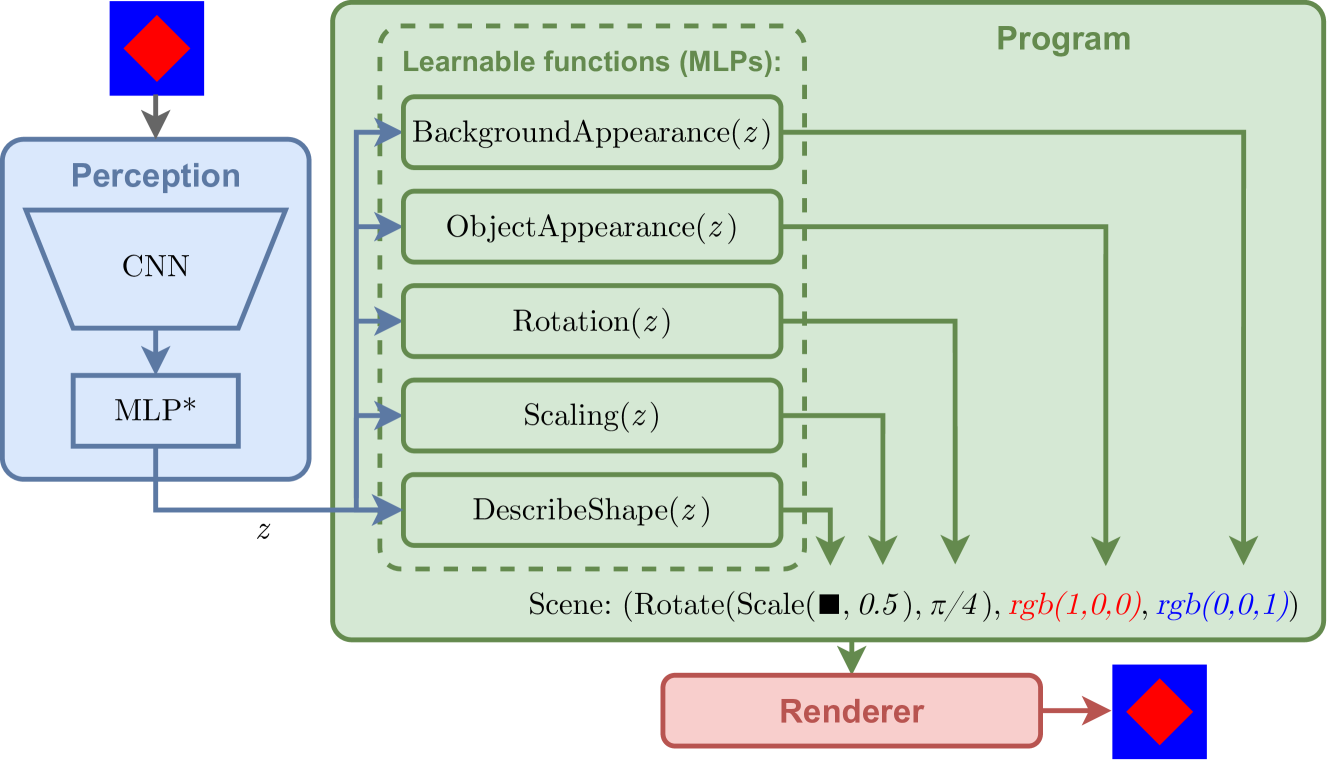
0
New!Disentangling Visual Priors: Unsupervised Learning of Scene Interpretations with Compositional Autoencoder
Krzysztof Krawiec, Antoni Nowinowski
Contemporary deep learning architectures lack principled means for capturing and handling fundamental visual concepts, like objects, shapes, geometric transforms, and other higher-level structures. We propose a neurosymbolic architecture that uses a domain-specific language to capture selected priors of image formation, including object shape, appearance, categorization, and geometric transforms. We express template programs in that language and learn their parameterization with features extracted from the scene by a convolutional neural network. When executed, the parameterized program produces geometric primitives which are rendered and assessed for correspondence with the scene content and trained via auto-association with gradient. We confront our approach with a baseline method on a synthetic benchmark and demonstrate its capacity to disentangle selected aspects of the image formation process, learn from small data, correct inference in the presence of noise, and out-of-sample generalization.
Read more9/17/2024