Language Models can Exploit Cross-Task In-context Learning for Data-Scarce Novel Tasks
2405.10548
0
0

Abstract
Large Language Models (LLMs) have transformed NLP with their remarkable In-context Learning (ICL) capabilities. Automated assistants based on LLMs are gaining popularity; however, adapting them to novel tasks is still challenging. While colossal models excel in zero-shot performance, their computational demands limit widespread use, and smaller language models struggle without context. This paper investigates whether LLMs can generalize from labeled examples of predefined tasks to novel tasks. Drawing inspiration from biological neurons and the mechanistic interpretation of the Transformer architecture, we explore the potential for information sharing across tasks. We design a cross-task prompting setup with three LLMs and show that LLMs achieve significant performance improvements despite no examples from the target task in the context. Cross-task prompting leads to a remarkable performance boost of 107% for LLaMA-2 7B, 18.6% for LLaMA-2 13B, and 3.2% for GPT 3.5 on average over zero-shot prompting, and performs comparable to standard in-context learning. The effectiveness of generating pseudo-labels for in-task examples is demonstrated, and our analyses reveal a strong correlation between the effect of cross-task examples and model activation similarities in source and target input tokens. This paper offers a first-of-its-kind exploration of LLMs' ability to solve novel tasks based on contextual signals from different task examples.
Create account to get full access
Overview
- This paper explores how large language models can leverage cross-task in-context learning to perform well on data-scarce novel tasks.
- The researchers investigate prompting techniques that allow language models to apply knowledge gained from previous tasks to learn new tasks quickly with limited data.
- The paper presents experiments and insights on the capabilities and limitations of this cross-task in-context learning approach.
Plain English Explanation
In-context learning is a technique that allows language models to quickly learn new tasks by providing relevant examples or instructions as part of the input, rather than requiring extensive training on large datasets. This paper investigates how language models can exploit cross-task in-context learning - using knowledge gained from previous tasks to perform well on new, data-scarce tasks.
The key idea is that language models may be able to leverage knowledge from prior tasks to adapt to novel tasks more efficiently, without needing large amounts of task-specific training data. This could be particularly useful for tasks where data is limited, such as specialized text classification or generating content in new domains.
The researchers experiment with different prompting techniques to enable this cross-task in-context learning, and analyze the capabilities and limitations of this approach. They provide insights into how well language models can transfer knowledge across tasks and the factors that impact the effectiveness of this technique.
Technical Explanation
The paper investigates how large language models can leverage cross-task in-context learning to perform well on data-scarce novel tasks. The key idea is that language models may be able to transfer knowledge gained from previous tasks to quickly adapt to new tasks using only limited task-specific data.
The researchers experiment with different prompting techniques that provide the language model with relevant examples or instructions as part of the input, allowing it to learn the new task through in-context learning. They evaluate the performance of language models on a variety of novel tasks, comparing their ability to learn from scratch versus leveraging cross-task knowledge.
The results show that language models can indeed exploit cross-task in-context learning to achieve strong performance on data-scarce tasks, outperforming approaches that rely solely on task-specific training data. However, the researchers also identify limitations and factors that impact the effectiveness of this technique, such as the similarity between the source and target tasks.
Critical Analysis
The paper presents a promising approach for enabling language models to rapidly adapt to new tasks with limited data. By leveraging cross-task in-context learning, the models can apply knowledge gained from previous experiences to bootstrap their performance on novel, data-scarce challenges.
However, the researchers acknowledge that the effectiveness of this technique is dependent on factors such as the similarity between the source and target tasks. In cases where the tasks are more distant, the language model may struggle to effectively transfer its knowledge, limiting the benefits of cross-task in-context learning.
Additionally, the paper does not explore the potential for negative transfer, where knowledge from one task may actually hinder performance on a new task. This is an important consideration that could limit the robustness of the cross-task in-context learning approach in real-world scenarios.
Further research is needed to better understand the boundaries and limitations of this technique, as well as explore ways to make it more reliable and versatile. Investigating methods to improve the task-agnostic knowledge representation of language models could be a promising direction to enhance their ability to effectively apply cross-task learning.
Conclusion
This paper presents an innovative approach that allows language models to leverage cross-task in-context learning to perform well on data-scarce novel tasks. By providing relevant examples or instructions as part of the input, the models can apply knowledge gained from previous experiences to quickly adapt to new challenges.
The findings suggest that this cross-task in-context learning technique can be a powerful tool for enabling language models to rapidly expand their capabilities, especially in domains where training data is limited. However, the effectiveness of the approach is dependent on factors such as the similarity between the source and target tasks, and further research is needed to fully understand its limitations and potential for negative transfer.
As language models continue to grow in capabilities, techniques like cross-task in-context learning will be increasingly important for expanding their utility and enabling them to tackle a wider range of real-world problems with limited data. This paper provides valuable insights and a foundation for further exploration in this exciting area of machine learning research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
What Do Language Models Learn in Context? The Structured Task Hypothesis
Jiaoda Li, Yifan Hou, Mrinmaya Sachan, Ryan Cotterell
0
0
Large language models (LLMs) exhibit an intriguing ability to learn a novel task from in-context examples presented in a demonstration, termed in-context learning (ICL). Understandably, a swath of research has been dedicated to uncovering the theories underpinning ICL. One popular hypothesis explains ICL by task selection. LLMs identify the task based on the demonstration and generalize it to the prompt. Another popular hypothesis is that ICL is a form of meta-learning, i.e., the models learn a learning algorithm at pre-training time and apply it to the demonstration. Finally, a third hypothesis argues that LLMs use the demonstration to select a composition of tasks learned during pre-training to perform ICL. In this paper, we empirically explore these three hypotheses that explain LLMs' ability to learn in context with a suite of experiments derived from common text classification tasks. We invalidate the first two hypotheses with counterexamples and provide evidence in support of the last hypothesis. Our results suggest an LLM could learn a novel task in context via composing tasks learned during pre-training.
6/11/2024
🌀
In-context Learning Generalizes, But Not Always Robustly: The Case of Syntax
Aaron Mueller, Albert Webson, Jackson Petty, Tal Linzen
0
0
In-context learning (ICL) is now a common method for teaching large language models (LLMs) new tasks: given labeled examples in the input context, the LLM learns to perform the task without weight updates. Do models guided via ICL infer the underlying structure of the task defined by the context, or do they rely on superficial heuristics that only generalize to identically distributed examples? We address this question using transformations tasks and an NLI task that assess sensitivity to syntax - a requirement for robust language understanding. We further investigate whether out-of-distribution generalization can be improved via chain-of-thought prompting, where the model is provided with a sequence of intermediate computation steps that illustrate how the task ought to be performed. In experiments with models from the GPT, PaLM, and Llama 2 families, we find large variance across LMs. The variance is explained more by the composition of the pre-training corpus and supervision methods than by model size; in particular, models pre-trained on code generalize better, and benefit more from chain-of-thought prompting.
4/11/2024
📈
An Empirical Study of In-context Learning in LLMs for Machine Translation
Pranjal A. Chitale, Jay Gala, Raj Dabre
0
0
Recent interest has surged in employing Large Language Models (LLMs) for machine translation (MT) via in-context learning (ICL) (Vilar et al., 2023). Most prior studies primarily focus on optimizing translation quality, with limited attention to understanding the specific aspects of ICL that influence the said quality. To this end, we perform the first of its kind, an exhaustive study of in-context learning for machine translation. We first establish that ICL is primarily example-driven and not instruction-driven. Following this, we conduct an extensive exploration of various aspects of the examples to understand their influence on downstream performance. Our analysis includes factors such as quality and quantity of demonstrations, spatial proximity, and source versus target originality. Further, we also investigate challenging scenarios involving indirectness and misalignment of examples to understand the limits of ICL. While we establish the significance of the quality of the target distribution over the source distribution of demonstrations, we further observe that perturbations sometimes act as regularizers, resulting in performance improvements. Surprisingly, ICL does not necessitate examples from the same task, and a related task with the same target distribution proves sufficient. We hope that our study acts as a guiding resource for considerations in utilizing ICL for MT. Our code is available on https://github.com/PranjalChitale/in-context-mt-analysis.
6/6/2024
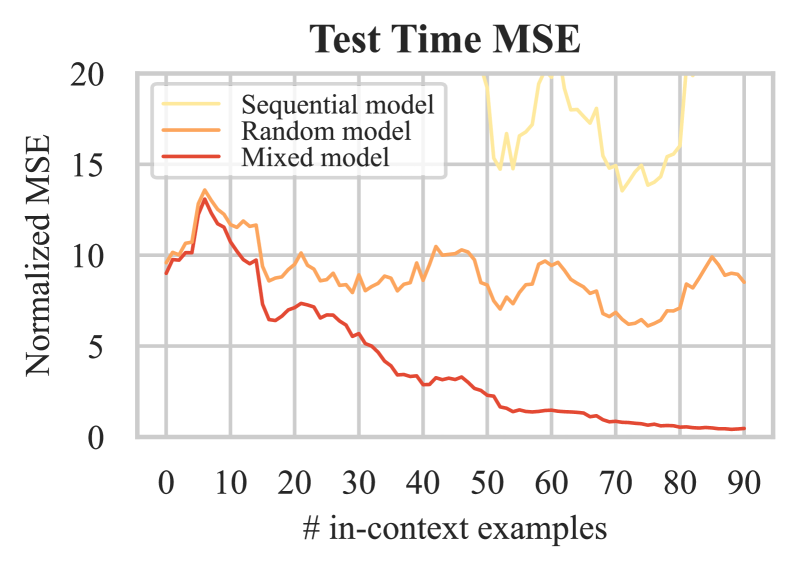
How does Multi-Task Training Affect Transformer In-Context Capabilities? Investigations with Function Classes
Harmon Bhasin, Timothy Ossowski, Yiqiao Zhong, Junjie Hu
0
0
Large language models (LLM) have recently shown the extraordinary ability to perform unseen tasks based on few-shot examples provided as text, also known as in-context learning (ICL). While recent works have attempted to understand the mechanisms driving ICL, few have explored training strategies that incentivize these models to generalize to multiple tasks. Multi-task learning (MTL) for generalist models is a promising direction that offers transfer learning potential, enabling large parameterized models to be trained from simpler, related tasks. In this work, we investigate the combination of MTL with ICL to build models that efficiently learn tasks while being robust to out-of-distribution examples. We propose several effective curriculum learning strategies that allow ICL models to achieve higher data efficiency and more stable convergence. Our experiments reveal that ICL models can effectively learn difficult tasks by training on progressively harder tasks while mixing in prior tasks, denoted as mixed curriculum in this work. Our code and models are available at https://github.com/harmonbhasin/curriculum_learning_icl .
4/5/2024