Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation

34
🛸
Sign in to get full access
Overview
- Recent AI systems use "scaffolding programs" - code written in languages like Python - to structure multiple calls to language models (LMs) and generate better outputs.
- In this work, the researchers used a scaffolding program that calls an LM to improve itself.
- They started with a "seed improver" that could improve an input program by querying an LM multiple times and returning the best solution.
- They then ran this seed improver to improve itself.
- The resulting improved improver generated programs with significantly better performance than the original seed improver.
- The LM proposed various self-improvement strategies like beam search, genetic algorithms, and simulated annealing.
Plain English Explanation
The researchers developed a computer program that was able to call itself and make improvements. This program was built on top of a language model - a type of AI system that can understand and generate human-like text.
The process worked like this:
- They started with a simple "seed" program that could take an input, query the language model, and return an improved version of the input.
- They then ran this seed program on itself, allowing it to modify and improve its own code.
- The resulting "improved improver" was able to generate programs that performed significantly better than the original seed program.
The language model suggested various strategies for the program to use to improve itself, like beam search, genetic algorithms, and simulated annealing.
This demonstrates that modern language models are capable of generating code that can call and improve itself, even though the language models themselves are not being altered. This is an important step towards self-improving AI systems, but there are still concerns about the potential development of such technologies.
Technical Explanation
The researchers developed a scaffolding program written in Python that uses a language model (LM) to generate and evaluate potential improvements to its own code. They start with a "seed improver" that takes an input program, queries the LM multiple times, and returns the best improved version of the program according to a given utility function.
They then run this seed improver on itself, allowing it to modify and enhance its own code. Across a small set of downstream tasks, the resulting "improved improver" generates programs with significantly better performance than the original seed improver.
The LM proposes a variety of self-improvement strategies, including beam search, genetic algorithms, and simulated annealing. Since the LM itself is not altered, this is not considered full recursive self-improvement. Nonetheless, it demonstrates that a modern language model, specifically GPT-4 in their experiments, has the capability to write code that can call and improve itself.
Critical Analysis
The researchers acknowledge several caveats and limitations to their work. First, they only evaluated their approach on a small set of tasks, so the generalizability of the results is uncertain. Additionally, the self-improvement strategies proposed by the LM were relatively simple and may not scale to more complex self-improvement scenarios.
There are also significant concerns around the development of self-improving technologies. While the researchers did not observe the generated code bypassing their sandbox, this remains a serious risk that requires careful monitoring and safeguards. The potential for uncontrolled self-improvement could lead to unpredictable and potentially dangerous outcomes.
Further research is needed to explore more advanced self-improvement strategies, ensure the safety and reliability of such systems, and investigate the broader implications for the field of AI and society as a whole.
Conclusion
This research demonstrates that modern language models are capable of generating code that can call and improve itself, even if the language models themselves are not being directly modified. This is an important step towards the development of self-improving AI systems, but significant challenges and concerns remain.
The researchers were able to use a scaffolding program and a language model to create an "improved improver" that generated better-performing programs than the original seed improver. However, the self-improvement strategies proposed by the LM were relatively simple, and the researchers acknowledge the need for further work to address safety and reliability concerns.
As the field of AI continues to progress, it will be crucial to carefully consider the implications of self-improving technologies and work to ensure that they are developed and deployed responsibly and with appropriate safeguards in place.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
34
Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation
Eric Zelikman, Eliana Lorch, Lester Mackey, Adam Tauman Kalai
Several recent advances in AI systems solve problems by providing a scaffolding program that structures multiple calls to language models (LMs) to generate better outputs. A scaffolding program is written in a programming language such as Python. In this work, we use a language-model-infused scaffolding program to improve itself. We start with a seed improver that improves an input program according to a given utility function by querying an LM several times and returning the best solution. We then run this seed improver to improve itself. Across a small set of downstream tasks, the resulting improved improver generates programs with significantly better performance than its seed improver. A variety of self-improvement strategies are proposed by the language model, including beam search, genetic algorithms, and simulated annealing. Since the language models themselves are not altered, this is not full recursive self-improvement. Nonetheless, it demonstrates that a modern language model, GPT-4 in our experiments, is capable of writing code that can call itself to improve itself. We consider concerns around the development of self-improving technologies and evaluate the frequency with which the generated code bypasses a sandbox.
Read more8/19/2024
0
An Empirical Study on Self-correcting Large Language Models for Data Science Code Generation
Thai Tang Quoc, Duc Ha Minh, Tho Quan Thanh, Anh Nguyen-Duc
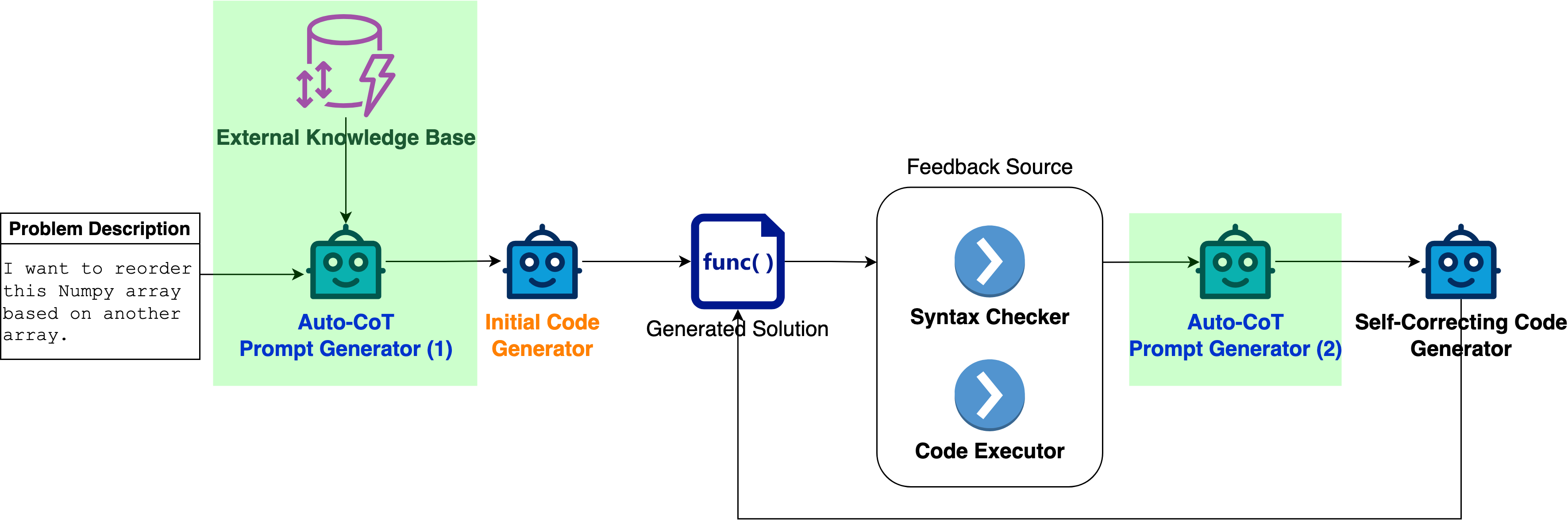
Large Language Models (LLMs) have recently advanced many applications on software engineering tasks, particularly the potential for code generation. Among contemporary challenges, code generated by LLMs often suffers from inaccuracies and hallucinations, requiring external inputs to correct. One recent strategy to fix these issues is to refine the code generated from LLMs using the input from the model itself (self-augmented). In this work, we proposed a novel method, namely CoT-SelfEvolve. CoT-SelfEvolve iteratively and automatically refines code through a self-correcting process, guided by a chain of thought constructed from real-world programming problem feedback. Focusing on data science code, including Python libraries such as NumPy and Pandas, our evaluations on the DS-1000 dataset demonstrate that CoT-SelfEvolve significantly outperforms existing models in solving complex problems. The framework shows substantial improvements in both initial code generation and subsequent iterations, with the model's accuracy increasing significantly with each additional iteration. This highlights the effectiveness of using chain-of-thought prompting to address complexities revealed by program executor traceback error messages. We also discuss how CoT-SelfEvolve can be integrated into continuous software engineering environments, providing a practical solution for improving LLM-based code generation.
Read more8/29/2024
💬
0
From Language Models to Practical Self-Improving Computer Agents
Alex Sheng
We develop a simple and straightforward methodology to create AI computer agents that can carry out diverse computer tasks and self-improve by developing tools and augmentations to enable themselves to solve increasingly complex tasks. As large language models (LLMs) have been shown to benefit from non-parametric augmentations, a significant body of recent work has focused on developing software that augments LLMs with various capabilities. Rather than manually developing static software to augment LLMs through human engineering effort, we propose that an LLM agent can systematically generate software to augment itself. We show, through a few case studies, that a minimal querying loop with appropriate prompt engineering allows an LLM to generate and use various augmentations, freely extending its own capabilities to carry out real-world computer tasks. Starting with only terminal access, we prompt an LLM agent to augment itself with retrieval, internet search, web navigation, and text editor capabilities. The agent effectively uses these various tools to solve problems including automated software development and web-based tasks.
Read more4/19/2024

0
SIaM: Self-Improving Code-Assisted Mathematical Reasoning of Large Language Models
Dian Yu, Baolin Peng, Ye Tian, Linfeng Song, Haitao Mi, Dong Yu
There is a growing trend of teaching large language models (LLMs) to solve mathematical problems through coding. Existing studies primarily focus on prompting powerful, closed-source models to generate seed training data followed by in-domain data augmentation, equipping LLMs with considerable capabilities for code-aided mathematical reasoning. However, continually training these models on augmented data derived from a few datasets such as GSM8K may impair their generalization abilities and restrict their effectiveness to a narrow range of question types. Conversely, the potential of improving such LLMs by leveraging large-scale, expert-written, diverse math question-answer pairs remains unexplored. To utilize these resources and tackle unique challenges such as code response assessment, we propose a novel paradigm that uses a code-based critic model to guide steps including question-code data construction, quality control, and complementary evaluation. We also explore different alignment algorithms with self-generated instruction/preference data to foster continuous improvement. Experiments across both in-domain (up to +5.7%) and out-of-domain (+4.4%) benchmarks in English and Chinese demonstrate the effectiveness of the proposed paradigm.
Read more8/29/2024