Enabling On-Device Learning via Experience Replay with Efficient Dataset Condensation

0

Sign in to get full access
Overview
- This paper presents a novel approach to enable on-device learning by efficiently condensing large datasets into smaller ones, which can then be used for experience replay during training.
- The proposed method, called Efficient Dataset Condensation (EDC), aims to overcome the challenges of traditional dataset condensation techniques, which can be computationally expensive and lead to significant performance degradation.
- EDC leverages advanced optimization techniques to generate a highly compact dataset that retains the essential characteristics of the original data, allowing for effective on-device learning while minimizing storage and computational requirements.
Plain English Explanation
Imagine you have a huge collection of images, and you want to use them to train an AI model on a device with limited storage and processing power, like a smartphone. The traditional approach would be to compress the entire dataset and store it on the device, but this can be very slow and may not work well.
The researchers in this paper have developed a new method called Efficient Dataset Condensation (EDC) that can take that huge dataset and create a much smaller version of it, with just the most important bits. This smaller dataset can then be used to train the AI model on the device, without losing too much accuracy.
The key idea behind EDC is to use advanced optimization techniques to figure out which parts of the original dataset are the most essential for training the AI model. This allows them to create a highly compact version of the dataset that still retains the most important information. This means the AI model can be trained on the device itself, without needing to store or process the entire original dataset.
This is really important for things like enabling on-device learning, where the AI model needs to be able to adapt and learn new things while running on a device with limited resources. By using EDC, the researchers have found a way to make this kind of on-device learning much more practical and efficient.
Technical Explanation
The paper proposes a novel approach called Efficient Dataset Condensation (EDC) that aims to address the challenges of traditional dataset condensation techniques. EDC leverages advanced optimization methods to generate a highly compact dataset that retains the essential characteristics of the original data, enabling effective on-device learning while minimizing storage and computational requirements.
The core idea of EDC is to treat the dataset condensation problem as an optimization task, where the goal is to find a small subset of data points that can effectively represent the original dataset. The researchers use a combination of techniques, including dataset condensation, multisize dataset condensation, and KoopCon, to efficiently generate a compact dataset that can be used for on-device learning via experience replay.
The paper presents extensive experiments on various benchmark datasets and tasks, demonstrating that EDC can achieve comparable or even superior performance compared to the original full datasets, while significantly reducing the storage and computational requirements. The researchers also explore the transportability of the condensed datasets, showing that they can be effectively used across different models and tasks.
Critical Analysis
The paper presents a well-designed and thorough study of the Efficient Dataset Condensation (EDC) approach, with a strong theoretical foundation and extensive experimental validation. The use of advanced optimization techniques, such as multisize dataset condensation and KoopCon, is a promising approach to address the limitations of traditional dataset condensation methods.
However, the paper does not fully explore the potential limitations and caveats of the EDC approach. For example, the performance of the condensed datasets may vary depending on the complexity of the original dataset and the specific task at hand. Additionally, the transportability of the condensed datasets across different models and tasks could be further investigated to understand the broader applicability of the method.
Furthermore, the paper does not address potential privacy and security concerns that may arise when deploying on-device learning systems using condensed datasets. Researchers may need to consider these aspects in future work to ensure the responsible development and deployment of such technologies.
Overall, the paper presents a significant contribution to the field of on-device learning and dataset condensation, but there are still avenues for further research and refinement of the EDC approach.
Conclusion
This paper introduces a novel method called Efficient Dataset Condensation (EDC) that enables on-device learning by generating highly compact datasets that can be used for experience replay during training. EDC leverages advanced optimization techniques to condense large datasets into smaller versions that retain the essential characteristics of the original data, overcoming the limitations of traditional dataset condensation approaches.
The key innovation of EDC is its ability to create compact datasets that can be effectively used for on-device learning, significantly reducing the storage and computational requirements compared to the full original datasets. This paves the way for more practical and efficient deployment of AI models on resource-constrained devices, with potential applications in areas like mobile computing, edge devices, and Internet of Things (IoT) systems.
The paper's thorough experimental evaluation and analysis demonstrate the significant potential of the EDC approach, opening up new avenues for further research and development in the field of on-device learning and efficient dataset management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enabling On-Device Learning via Experience Replay with Efficient Dataset Condensation
Gelei Xu, Ningzhi Tang, Jun Xia, Wei Jin, Yiyu Shi
Upon deployment to edge devices, it is often desirable for a model to further learn from streaming data to improve accuracy. However, extracting representative features from such data is challenging because it is typically unlabeled, non-independent and identically distributed (non-i.i.d), and is seen only once. To mitigate this issue, a common strategy is to maintain a small data buffer on the edge device to hold the most representative data for further learning. As most data is either never stored or quickly discarded, identifying the most representative data to avoid significant information loss becomes critical. In this paper, we propose an on-device framework that addresses this issue by condensing incoming data into more informative samples. Specifically, to effectively handle unlabeled incoming data, we propose a pseudo-labeling technique designed for unlabeled on-device learning environments. Additionally, we develop a dataset condensation technique that only requires little computation resources. To counteract the effects of noisy labels during the condensation process, we further utilize a contrastive learning objective to improve the purity of class data within the buffer. Our empirical results indicate substantial improvements over existing methods, particularly when buffer capacity is severely restricted. For instance, with a buffer capacity of just one sample per class, our method achieves an accuracy that outperforms the best existing baseline by 58.4% on the CIFAR-10 dataset.
Read more5/28/2024

0
Elucidating the Design Space of Dataset Condensation
Shitong Shao, Zikai Zhou, Huanran Chen, Zhiqiang Shen
Dataset condensation, a concept within data-centric learning, efficiently transfers critical attributes from an original dataset to a synthetic version, maintaining both diversity and realism. This approach significantly improves model training efficiency and is adaptable across multiple application areas. Previous methods in dataset condensation have faced challenges: some incur high computational costs which limit scalability to larger datasets (e.g., MTT, DREAM, and TESLA), while others are restricted to less optimal design spaces, which could hinder potential improvements, especially in smaller datasets (e.g., SRe2L, G-VBSM, and RDED). To address these limitations, we propose a comprehensive design framework that includes specific, effective strategies like implementing soft category-aware matching and adjusting the learning rate schedule. These strategies are grounded in empirical evidence and theoretical backing. Our resulting approach, Elucidate Dataset Condensation (EDC), establishes a benchmark for both small and large-scale dataset condensation. In our testing, EDC achieves state-of-the-art accuracy, reaching 48.6% on ImageNet-1k with a ResNet-18 model at an IPC of 10, which corresponds to a compression ratio of 0.78%. This performance exceeds those of SRe2L, G-VBSM, and RDED by margins of 27.3%, 17.2%, and 6.6%, respectively.
Read more5/7/2024
0
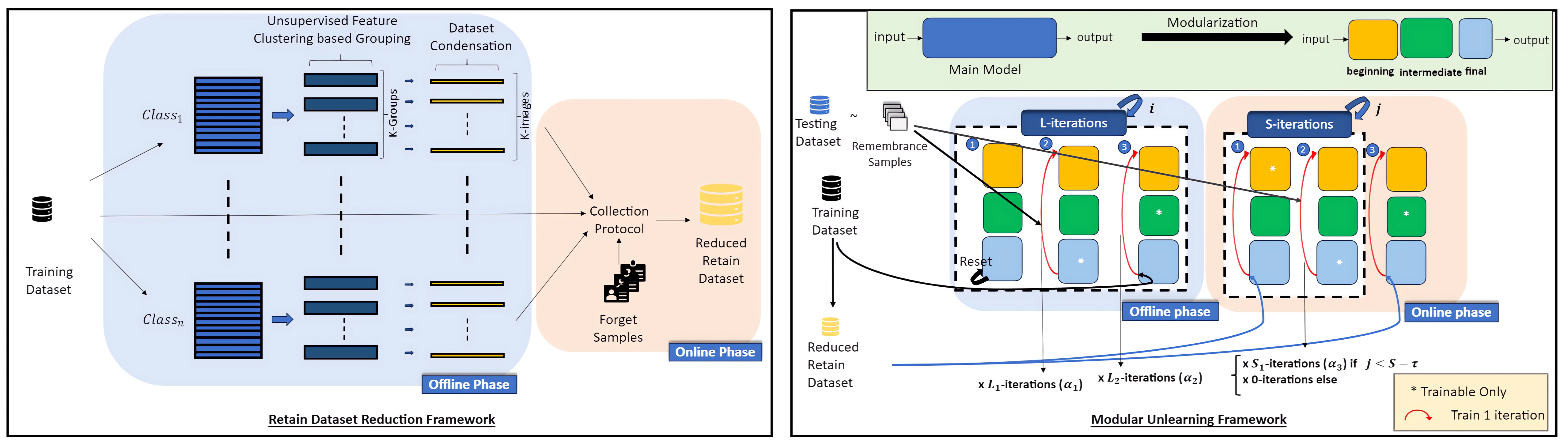
Dataset Condensation Driven Machine Unlearning
Junaid Iqbal Khan
The current trend in data regulation requirements and privacy-preserving machine learning has emphasized the importance of machine unlearning. The naive approach to unlearning training data by retraining over the complement of the forget samples is susceptible to computational challenges. These challenges have been effectively addressed through a collection of techniques falling under the umbrella of machine unlearning. However, there still exists a lack of sufficiency in handling persistent computational challenges in harmony with the utility and privacy of unlearned model. We attribute this to the lack of work on improving the computational complexity of approximate unlearning from the perspective of the training dataset. In this paper, we aim to fill this gap by introducing dataset condensation as an essential component of machine unlearning in the context of image classification. To achieve this goal, we propose new dataset condensation techniques and an innovative unlearning scheme that strikes a balance between machine unlearning privacy, utility, and efficiency. Furthermore, we present a novel and effective approach to instrumenting machine unlearning and propose its application in defending against membership inference and model inversion attacks. Additionally, we explore a new application of our approach, which involves removing data from `condensed model', which can be employed to quickly train any arbitrary model without being influenced by unlearning samples. The corresponding code is available at href{https://github.com/algebraicdianuj/DC_U}{URL}.
Read more5/14/2024
0
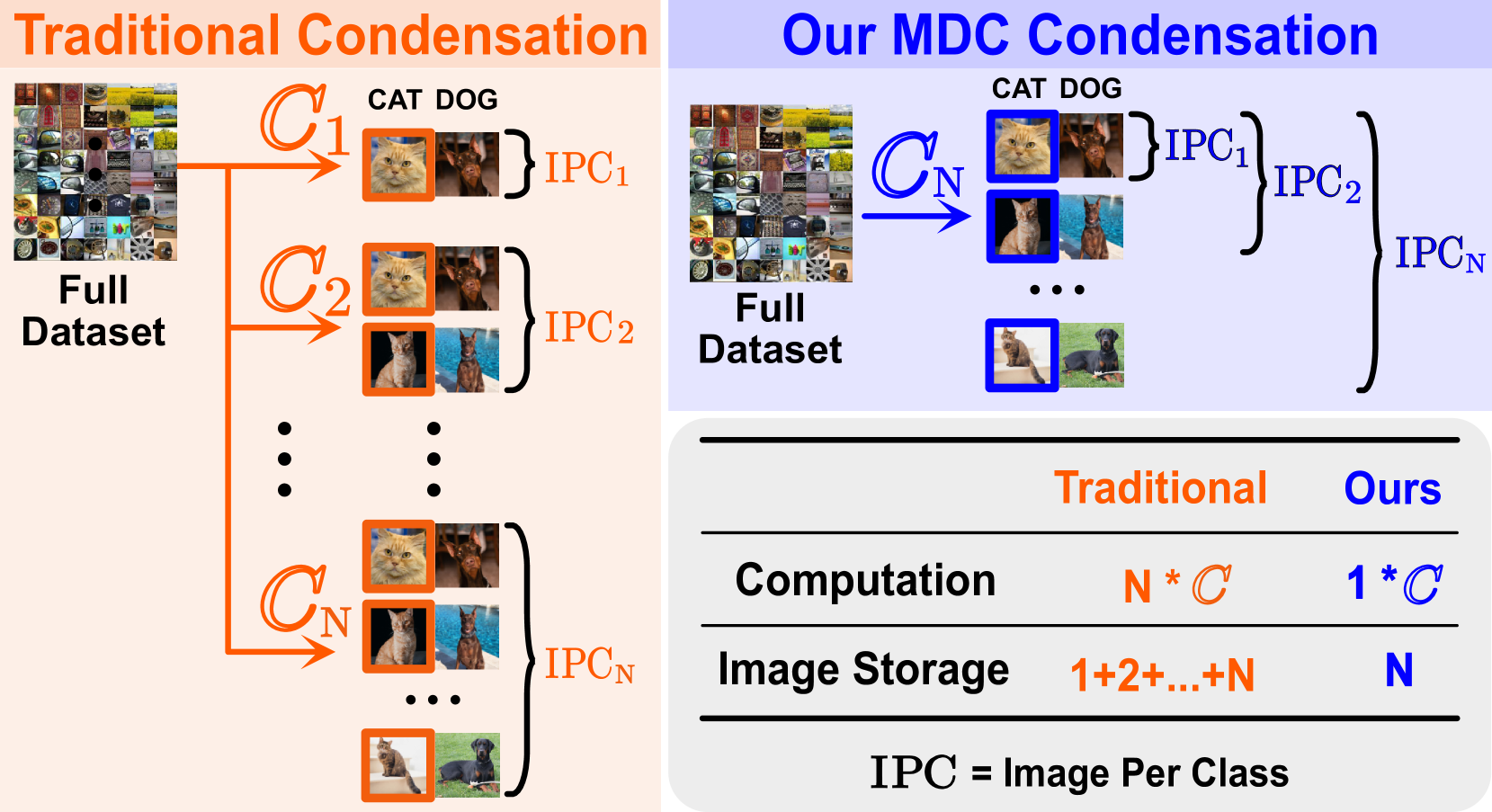
Multisize Dataset Condensation
Yang He, Lingao Xiao, Joey Tianyi Zhou, Ivor Tsang
While dataset condensation effectively enhances training efficiency, its application in on-device scenarios brings unique challenges. 1) Due to the fluctuating computational resources of these devices, there's a demand for a flexible dataset size that diverges from a predefined size. 2) The limited computational power on devices often prevents additional condensation operations. These two challenges connect to the subset degradation problem in traditional dataset condensation: a subset from a larger condensed dataset is often unrepresentative compared to directly condensing the whole dataset to that smaller size. In this paper, we propose Multisize Dataset Condensation (MDC) by compressing N condensation processes into a single condensation process to obtain datasets with multiple sizes. Specifically, we introduce an adaptive subset loss on top of the basic condensation loss to mitigate the subset degradation problem. Our MDC method offers several benefits: 1) No additional condensation process is required; 2) reduced storage requirement by reusing condensed images. Experiments validate our findings on networks including ConvNet, ResNet and DenseNet, and datasets including SVHN, CIFAR-10, CIFAR-100 and ImageNet. For example, we achieved 5.22%-6.40% average accuracy gains on condensing CIFAR-10 to ten images per class. Code is available at: https://github.com/he-y/Multisize-Dataset-Condensation.
Read more4/16/2024