Probing the Feasibility of Multilingual Speaker Anonymization

0

Sign in to get full access
Overview
- This paper explores the feasibility of multilingual speaker anonymization, which involves modifying a speaker's voice to conceal their identity while preserving the linguistic content.
- The researchers investigate various approaches to achieve this, including end-to-end streaming models for low-latency voice conversion and asynchronous voice anonymization using adversarial perturbation.
- The study also examines the impact of speech anonymization on pathology detection and its limitations, as well as the potential for zero-shot multi-lingual speaker verification in clinical settings.
Plain English Explanation
The paper explores ways to hide a person's identity when they speak, while still preserving the actual words they say. This could be useful in scenarios where someone wants to protect their privacy, such as in legal or medical contexts. The researchers test different methods to modify a speaker's voice so that it sounds different, but the underlying language remains the same.
One approach they look at is using machine learning models that can convert a voice in real-time, without introducing too much delay. Another method involves adding subtle distortions to the audio that make it harder to recognize the original speaker. The paper also considers how these voice anonymization techniques might impact the ability to detect certain medical conditions from a person's speech, and explores the potential for using them in multilingual settings.
The goal is to develop ways for people to speak freely without worrying about their identity being revealed, which could have important applications in fields like healthcare and law.
Technical Explanation
The paper investigates the feasibility of multilingual speaker anonymization, which aims to modify a speaker's voice to conceal their identity while preserving the linguistic content of their speech. The researchers explore various approaches to achieve this, including:
-
End-to-end streaming models for low-latency voice conversion: These models can perform real-time voice conversion with minimal latency, which is crucial for practical applications.
-
Asynchronous voice anonymization using adversarial perturbation: This technique introduces subtle distortions to the audio signal that can fool speaker recognition systems without significantly altering the linguistic content.
The paper also examines the impact of speech anonymization on pathology detection and its limitations, as well as the potential for zero-shot multi-lingual speaker verification in clinical settings.
The researchers conduct experiments to evaluate the performance of these approaches, considering factors such as intelligibility, speaker recognition accuracy, and cross-lingual generalization. The findings provide insights into the feasibility and challenges of developing effective multilingual speaker anonymization systems.
Critical Analysis
The paper presents a comprehensive investigation of multilingual speaker anonymization, exploring various technical approaches and their potential implications. However, the research also acknowledges several limitations and areas for further exploration:
-
The impact of voice modification on the detection of speech pathologies is a complex issue that requires further study, as changes to the audio signal may inadvertently affect the ability to diagnose certain medical conditions.
-
The cross-lingual generalization of the proposed techniques is not fully explored, and additional research is needed to understand how well these methods perform across different languages and linguistic contexts.
-
The ethical considerations and potential misuse of such technologies, such as in surveillance or social manipulation, are not extensively discussed, and warrant deeper examination.
-
The paper focuses primarily on technical feasibility and does not delve into the broader societal implications and policy considerations around the deployment of speaker anonymization technologies.
Overall, the paper makes a valuable contribution to the field, but the research community should continue to critically examine the technical, ethical, and societal implications of multilingual speaker anonymization to ensure its responsible development and deployment.
Conclusion
This paper presents a thorough investigation into the feasibility of multilingual speaker anonymization, exploring various approaches to modifying a speaker's voice while preserving linguistic content. The researchers explore technical solutions, such as end-to-end streaming models and adversarial perturbation techniques, and examine their impact on pathology detection and the potential for multilingual speaker verification.
The findings provide insights into the current state of the art and the challenges involved in developing effective speaker anonymization systems. While the research demonstrates the technical viability of these techniques, it also highlights the need for further study on the broader implications, including the impact on speech-based medical diagnostics and the ethical considerations around the deployment of such technologies.
As the field of speaker anonymization continues to evolve, it will be crucial for researchers, policymakers, and the broader community to engage in a thoughtful and comprehensive dialogue to ensure that these technologies are developed and used in a way that respects privacy, promotes fairness, and serves the greater good.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Probing the Feasibility of Multilingual Speaker Anonymization
Sarina Meyer, Florian Lux, Ngoc Thang Vu
In speaker anonymization, speech recordings are modified in a way that the identity of the speaker remains hidden. While this technology could help to protect the privacy of individuals around the globe, current research restricts this by focusing almost exclusively on English data. In this study, we extend a state-of-the-art anonymization system to nine languages by transforming language-dependent components to their multilingual counterparts. Experiments testing the robustness of the anonymized speech against privacy attacks and speech deterioration show an overall success of this system for all languages. The results suggest that speaker embeddings trained on English data can be applied across languages, and that the anonymization performance for a language is mainly affected by the quality of the speech synthesis component used for it.
Read more7/4/2024

0
A Benchmark for Multi-speaker Anonymization
Xiaoxiao Miao, Ruijie Tao, Chang Zeng, Xin Wang
Privacy-preserving voice protection approaches primarily suppress privacy-related information derived from paralinguistic attributes while preserving the linguistic content. Existing solutions focus on single-speaker scenarios. However, they lack practicality for real-world applications, i.e., multi-speaker scenarios. In this paper, we present an initial attempt to provide a multi-speaker anonymization benchmark by defining the task and evaluation protocol, proposing benchmarking solutions, and discussing the privacy leakage of overlapping conversations. Specifically, ideal multi-speaker anonymization should preserve the number of speakers and the turn-taking structure of the conversation, ensuring accurate context conveyance while maintaining privacy. To achieve that, a cascaded system uses speaker diarization to aggregate the speech of each speaker and speaker anonymization to conceal speaker privacy and preserve speech content. Additionally, we propose two conversation-level speaker vector anonymization methods to improve the utility further. Both methods aim to make the original and corresponding pseudo-speaker identities of each speaker unlinkable while preserving or even improving the distinguishability among pseudo-speakers in a conversation. The first method minimizes the differential similarity across speaker pairs in the original and anonymized conversations to maintain original speaker relationships in the anonymized version. The other method minimizes the aggregated similarity across anonymized speakers to achieve better differentiation between speakers. Experiments conducted on both non-overlap simulated and real-world datasets demonstrate the effectiveness of the multi-speaker anonymization system with the proposed speaker anonymizers. Additionally, we analyzed overlapping speech regarding privacy leakage and provide potential solutions.
Read more7/9/2024
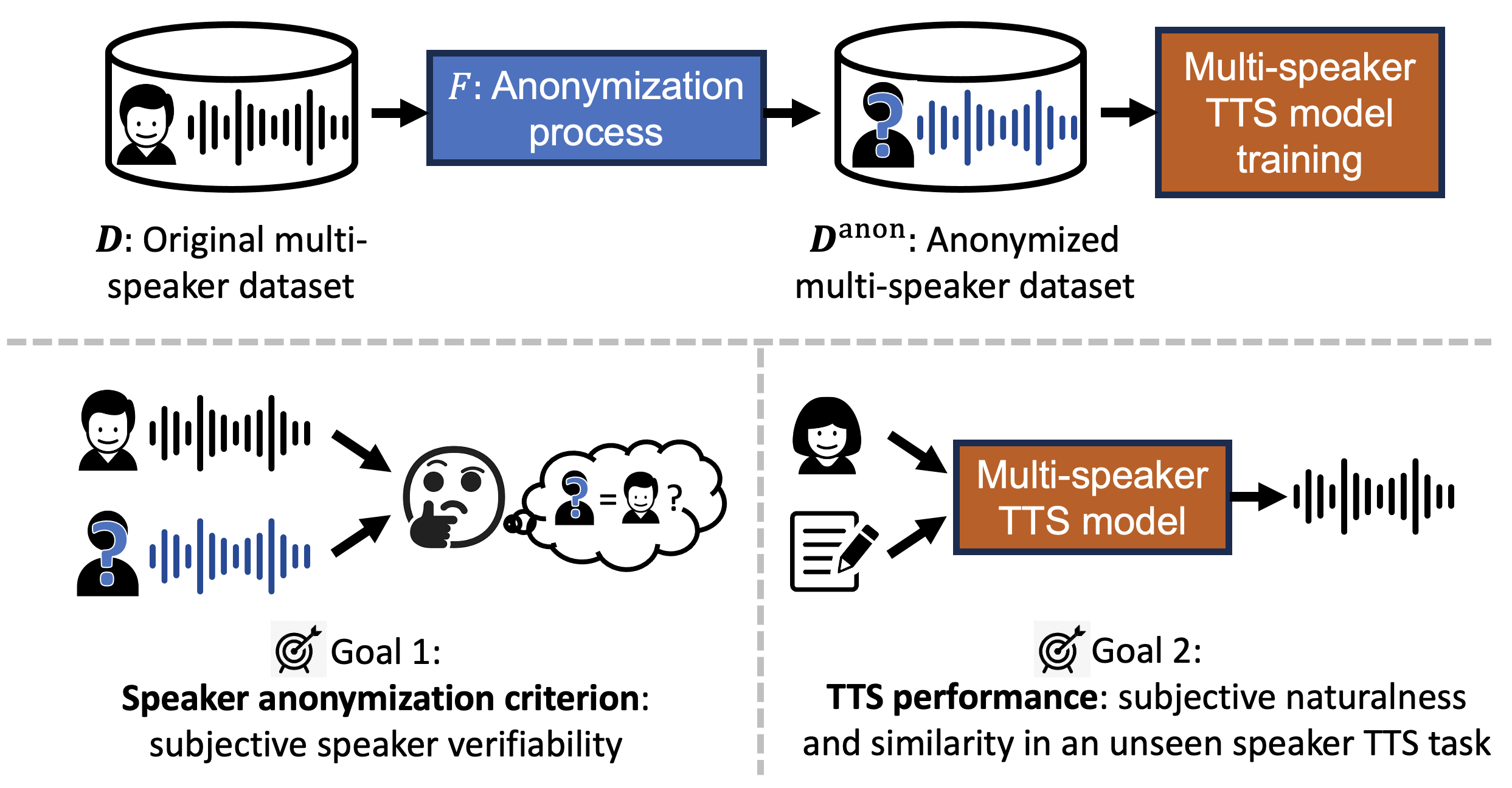
0
Multi-speaker Text-to-speech Training with Speaker Anonymized Data
Wen-Chin Huang, Yi-Chiao Wu, Tomoki Toda
The trend of scaling up speech generation models poses a threat of biometric information leakage of the identities of the voices in the training data, raising privacy and security concerns. In this paper, we investigate training multi-speaker text-to-speech (TTS) models using data that underwent speaker anonymization (SA), a process that tends to hide the speaker identity of the input speech while maintaining other attributes. Two signal processing-based and three deep neural network-based SA methods were used to anonymize VCTK, a multi-speaker TTS dataset, which is further used to train an end-to-end TTS model, VITS, to perform unseen speaker TTS during the testing phase. We conducted extensive objective and subjective experiments to evaluate the anonymized training data, as well as the performance of the downstream TTS model trained using those data. Importantly, we found that UTMOS, a data-driven subjective rating predictor model, and GVD, a metric that measures the gain of voice distinctiveness, are good indicators of the downstream TTS performance. We summarize insights in the hope of helping future researchers determine the goodness of the SA system for multi-speaker TTS training.
Read more5/21/2024

0
End-to-end Streaming model for Low-Latency Speech Anonymization
Waris Quamer, Ricardo Gutierrez-Osuna
Speaker anonymization aims to conceal cues to speaker identity while preserving linguistic content. Current machine learning based approaches require substantial computational resources, hindering real-time streaming applications. To address these concerns, we propose a streaming model that achieves speaker anonymization with low latency. The system is trained in an end-to-end autoencoder fashion using a lightweight content encoder that extracts HuBERT-like information, a pretrained speaker encoder that extract speaker identity, and a variance encoder that injects pitch and energy information. These three disentangled representations are fed to a decoder that resynthesizes the speech signal. We present evaluation results from two implementations of our system, a full model that achieves a latency of 230ms, and a lite version (0.1x in size) that further reduces latency to 66ms while maintaining state-of-the-art performance in naturalness, intelligibility, and privacy preservation.
Read more6/14/2024