Swin SMT: Global Sequential Modeling in 3D Medical Image Segmentation

0
Sign in to get full access
Overview
- This paper presents Swin SMT, a novel approach for global sequential modeling to enhance 3D medical image segmentation.
- Swin SMT integrates a Vision Transformer (ViT) architecture with a Swin Transformer to capture both local and global contextual information for improved segmentation performance.
- The proposed method leverages the strengths of Transformers to model long-range dependencies and hierarchical representations, addressing limitations of conventional 3D convolutional neural networks.
Plain English Explanation
Swin SMT is a new technique for improving the accuracy of 3D medical image segmentation, which is the process of identifying and outlining different structures or regions within 3D medical scans, such as MRI or CT images. The key innovation of Swin SMT is its integration of two powerful machine learning models - the Vision Transformer (ViT) and the Swin Transformer.
The Vision Transformer is a type of neural network that is particularly well-suited for capturing long-range dependencies and global context in visual data, like medical images. The Swin Transformer is a variant of the Transformer that can efficiently model local and hierarchical features.
By combining these two Transformer-based architectures, Swin SMT is able to effectively learn both the local details and the broader, global patterns in 3D medical scans. This allows the model to make more accurate segmentations compared to traditional 3D convolutional neural networks, which can struggle to capture long-range dependencies. The improvements demonstrated by Swin SMT could lead to better diagnosis and treatment planning in various medical applications that rely on accurate 3D image segmentation, such as lesion segmentation or stroke analysis.
Technical Explanation
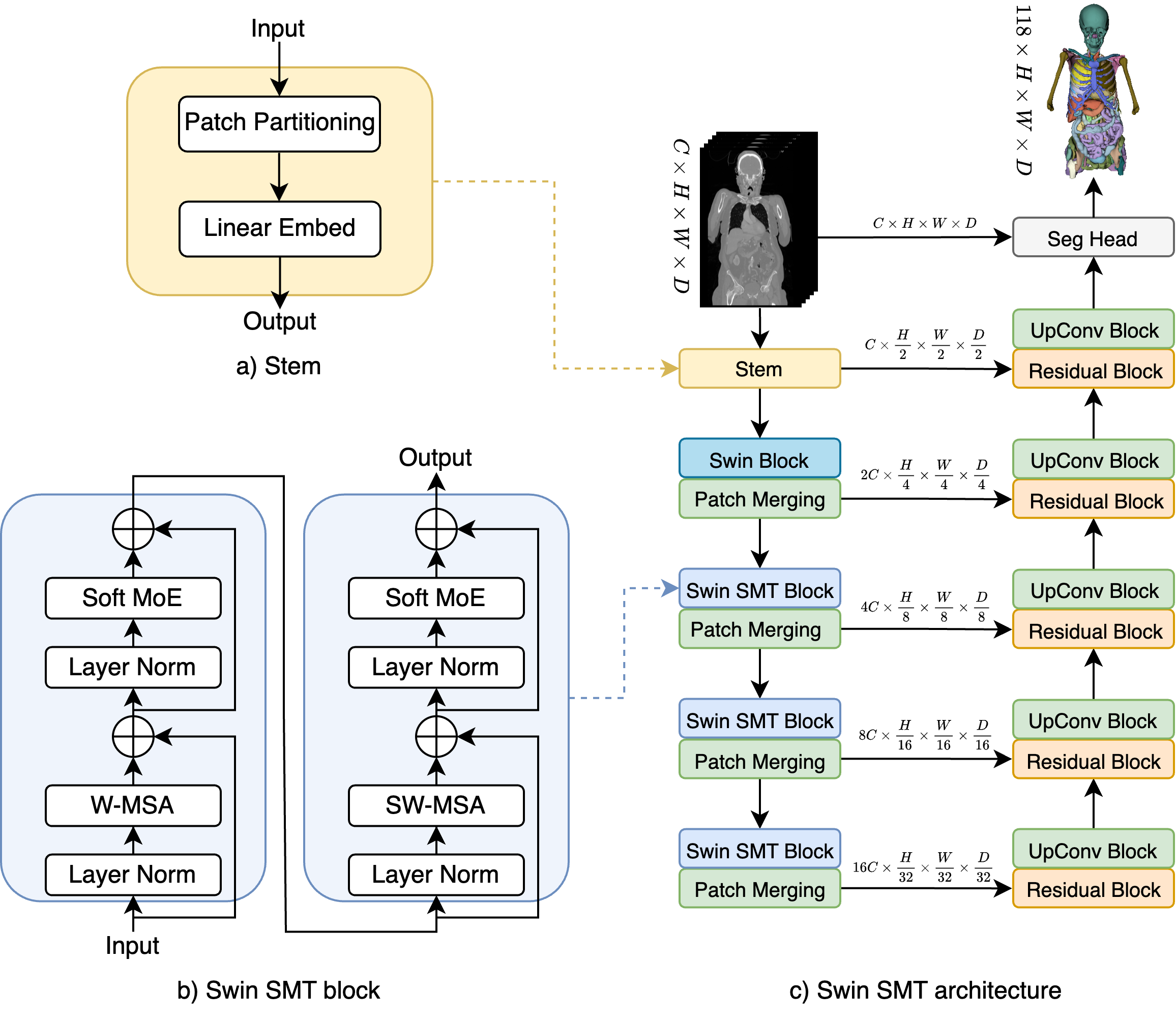
The Swin SMT model integrates a Vision Transformer (ViT) and a Swin Transformer to capture both local and global contextual information for 3D medical image segmentation. The ViT is used to model long-range dependencies and global context, while the Swin Transformer is used to efficiently learn local and hierarchical representations.
The ViT component of Swin SMT divides the input 3D medical image into non-overlapping patches, which are then linearly embedded and fed into a Transformer encoder. This allows the model to attend to and extract global features from the entire 3D volume. The Swin Transformer module, on the other hand, uses a shifted window-based self-attention mechanism to efficiently capture local spatial relationships and hierarchical features.
The outputs from the ViT and Swin Transformer modules are then combined and passed through a segmentation head to produce the final 3D segmentation map. The authors demonstrate that this combination of global and local modeling capabilities outperforms both traditional 3D convolutional neural networks and other state-of-the-art Transformer-based methods for 3D medical image segmentation tasks.
Critical Analysis
The Swin SMT paper presents a compelling approach for enhancing 3D medical image segmentation by leveraging the strengths of Transformer-based architectures. However, the authors acknowledge several limitations and areas for future research:
-
The proposed method may have higher computational and memory requirements compared to 3D convolutional networks, which could be a concern for deployment in resource-constrained clinical settings. Techniques to improve the efficiency of Swin SMT should be investigated.
-
The paper only evaluates Swin SMT on a limited number of 3D medical imaging datasets and segmentation tasks. Broader evaluation on a wider range of modalities and applications would help further validate the generalizability of the approach.
-
The authors do not provide a detailed analysis of the relative contributions of the ViT and Swin Transformer components to the overall performance improvements. A more in-depth ablation study could yield additional insights.
-
While the paper demonstrates state-of-the-art results, there may be room for further performance gains by incorporating additional modalities, such as clinical metadata or multimodal image registration, or by exploring alternative Transformer architectures and configurations.
Overall, the Swin SMT model represents an important step forward in leveraging Transformer-based techniques for 3D medical image segmentation. Addressing the identified limitations and exploring further enhancements could lead to even more powerful and practical solutions for this critical task.
Conclusion
The Swin SMT paper presents a novel approach for improving 3D medical image segmentation by integrating a Vision Transformer and a Swin Transformer to capture both global and local contextual information. By combining the strengths of these two Transformer-based architectures, Swin SMT is able to outperform traditional 3D convolutional neural networks and other state-of-the-art methods.
The proposed technique has the potential to lead to more accurate diagnoses and better-informed treatment planning in various medical applications that rely on precise 3D image segmentation, such as lesion detection and stroke analysis. While the paper identifies some limitations that warrant further investigation, Swin SMT represents an important advance in the field of medical imaging and could inspire the development of even more powerful Transformer-based solutions for 3D segmentation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Swin SMT: Global Sequential Modeling in 3D Medical Image Segmentation
Szymon P{l}otka, Maciej Chrabaszcz, Przemyslaw Biecek
Recent advances in Vision Transformers (ViTs) have significantly enhanced medical image segmentation by facilitating the learning of global relationships. However, these methods face a notable challenge in capturing diverse local and global long-range sequential feature representations, particularly evident in whole-body CT (WBCT) scans. To overcome this limitation, we introduce Swin Soft Mixture Transformer (Swin SMT), a novel architecture based on Swin UNETR. This model incorporates a Soft Mixture-of-Experts (Soft MoE) to effectively handle complex and diverse long-range dependencies. The use of Soft MoE allows for scaling up model parameters maintaining a balance between computational complexity and segmentation performance in both training and inference modes. We evaluate Swin SMT on the publicly available TotalSegmentator-V2 dataset, which includes 117 major anatomical structures in WBCT images. Comprehensive experimental results demonstrate that Swin SMT outperforms several state-of-the-art methods in 3D anatomical structure segmentation, achieving an average Dice Similarity Coefficient of 85.09%. The code and pre-trained weights of Swin SMT are publicly available at https://github.com/MI2DataLab/SwinSMT.
Read more7/11/2024
0
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
Shehan Perera, Pouyan Navard, Alper Yilmaz
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
Read more4/17/2024
📈
0
Enhancing 3D Transformer Segmentation Model for Medical Image with Token-level Representation Learning
Xinrong Hu, Dewen Zeng, Yawen Wu, Xueyang Li, Yiyu Shi
In the field of medical images, although various works find Swin Transformer has promising effectiveness on pixelwise dense prediction, whether pre-training these models without using extra dataset can further boost the performance for the downstream semantic segmentation remains unexplored.Applications of previous representation learning methods are hindered by the limited number of 3D volumes and high computational cost. In addition, most of pretext tasks designed specifically for Transformer are not applicable to hierarchical structure of Swin Transformer. Thus, this work proposes a token-level representation learning loss that maximizes agreement between token embeddings from different augmented views individually instead of volume-level global features. Moreover, we identify a potential representation collapse exclusively caused by this new loss. To prevent collapse, we invent a simple rotate-and-restore mechanism, which rotates and flips one augmented view of input volume, and later restores the order of tokens in the feature maps. We also modify the contrastive loss to address the discrimination between tokens at the same position but from different volumes. We test our pre-training scheme on two public medical segmentation datasets, and the results on the downstream segmentation task show more improvement of our methods than other state-of-the-art pre-trainig methods.
Read more8/13/2024
🛠️
0
Self-Supervised Modality-Agnostic Pre-Training of Swin Transformers
Abhiroop Talasila, Maitreya Maity, U. Deva Priyakumar
Unsupervised pre-training has emerged as a transformative paradigm, displaying remarkable advancements in various domains. However, the susceptibility to domain shift, where pre-training data distribution differs from fine-tuning, poses a significant obstacle. To address this, we augment the Swin Transformer to learn from different medical imaging modalities, enhancing downstream performance. Our model, dubbed SwinFUSE (Swin Multi-Modal Fusion for UnSupervised Enhancement), offers three key advantages: (i) it learns from both Computed Tomography (CT) and Magnetic Resonance Images (MRI) during pre-training, resulting in complementary feature representations; (ii) a domain-invariance module (DIM) that effectively highlights salient input regions, enhancing adaptability; (iii) exhibits remarkable generalizability, surpassing the confines of tasks it was initially pre-trained on. Our experiments on two publicly available 3D segmentation datasets show a modest 1-2% performance trade-off compared to single-modality models, yet significant out-performance of up to 27% on out-of-distribution modality. This substantial improvement underscores our proposed approach's practical relevance and real-world applicability. Code is available at: https://github.com/devalab/SwinFUSE
Read more5/22/2024