Enhancing Diagnostic Accuracy through Multi-Agent Conversations: Using Large Language Models to Mitigate Cognitive Bias
2401.14589
0
0
🎯
Abstract
Background: Cognitive biases in clinical decision-making significantly contribute to errors in diagnosis and suboptimal patient outcomes. Addressing these biases presents a formidable challenge in the medical field. Objective: This study explores the role of large language models (LLMs) in mitigating these biases through the utilization of a multi-agent framework. We simulate the clinical decision-making processes through multi-agent conversation and evaluate its efficacy in improving diagnostic accuracy. Methods: A total of 16 published and unpublished case reports where cognitive biases have resulted in misdiagnoses were identified from the literature. In the multi-agent framework, we leveraged GPT-4 to facilitate interactions among four simulated agents to replicate clinical team dynamics. Each agent has a distinct role: 1) To make the final diagnosis after considering the discussions, 2) The devil's advocate and correct confirmation and anchoring bias, 3) The tutor and facilitator of the discussion to reduce premature closure bias, and 4) To record and summarize the findings. A total of 80 simulations were evaluated for the accuracy of initial diagnosis, top differential diagnosis and final two differential diagnoses. Results: In a total of 80 responses evaluating both initial and final diagnoses, the initial diagnosis had an accuracy of 0% (0/80), but following multi-agent discussions, the accuracy for the top differential diagnosis increased to 71.3% (57/80), and for the final two differential diagnoses, to 80.0% (64/80). Conclusions: The framework demonstrated an ability to re-evaluate and correct misconceptions, even in scenarios with misleading initial investigations. The LLM-driven multi-agent conversation framework shows promise in enhancing diagnostic accuracy in diagnostically challenging medical scenarios.
Create account to get full access
Overview
- This study explores the use of large language models (LLMs) in mitigating cognitive biases in clinical decision-making.
- It utilizes a multi-agent framework to simulate clinical team dynamics and evaluate the effectiveness of this approach in improving diagnostic accuracy.
- The researchers identified 16 published and unpublished case reports where cognitive biases led to misdiagnoses, and used GPT-4 to facilitate interactions among four simulated agents representing different roles in the clinical decision-making process.
Plain English Explanation
Doctors and other healthcare professionals often make mistakes when diagnosing patients due to certain mental biases, which can lead to suboptimal patient outcomes. This study looked at how large language models like GPT-4 could help address this problem.
The researchers created a simulation where four "agents" (or virtual team members) with different roles discussed a set of challenging medical cases. One agent made the final diagnosis, another acted as a "devil's advocate" to correct confirmation and anchoring biases, a third facilitated the discussion to reduce premature closure bias, and the fourth recorded and summarized the findings.
By having these different perspectives and roles, the simulation was able to re-evaluate the initial diagnoses and arrive at more accurate final diagnoses, even in cases where the initial assessment was misleading. This multi-agent framework shows promise as a way to enhance diagnostic accuracy and reduce the impact of cognitive biases in clinical decision-making.
Technical Explanation
The researchers identified 16 published and unpublished case reports where cognitive biases, such as confirmation bias and anchoring bias, had led to misdiagnoses. They then used a multi-agent framework, leveraging the conversational capabilities of GPT-4, to simulate the clinical decision-making process.
In this framework, four agents were assigned distinct roles:
- The "final diagnosis" agent, who made the ultimate diagnosis after considering the discussions.
- The "devil's advocate" agent, who aimed to correct confirmation and anchoring biases.
- The "tutor" agent, who facilitated the discussion to reduce premature closure bias.
- The "recorder" agent, who documented and summarized the findings.
The researchers ran a total of 80 simulations and evaluated the accuracy of the initial diagnosis, the top differential diagnosis, and the final two differential diagnoses.
Critical Analysis
The study demonstrates the potential of LLM-driven multi-agent frameworks to enhance diagnostic accuracy in challenging medical scenarios. By incorporating different perspectives and roles, the simulation was able to re-evaluate and correct misconceptions that arose from cognitive biases.
However, the researchers acknowledge that the study is limited by the small sample size of 16 case reports. Additionally, the simulation may not fully capture the complexities and nuances of real-world clinical decision-making, where other factors, such as the experience and expertise of the healthcare team, can also play a significant role.
Further research is needed to explore the scalability and generalizability of this approach, as well as its integration with existing clinical decision support systems and potential pitfalls in the implementation of such systems.
Conclusion
This study presents a promising approach to mitigating cognitive biases in clinical decision-making by leveraging the conversational capabilities of large language models. The multi-agent framework demonstrates the potential to enhance diagnostic accuracy, even in challenging medical scenarios.
While further research is needed to fully understand the limitations and scalability of this approach, the findings highlight the valuable role that LLMs can play in supporting healthcare professionals and improving patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Conversational Disease Diagnosis via External Planner-Controlled Large Language Models
Zhoujian Sun, Cheng Luo, Ziyi Liu, Zhengxing Huang
0
0
The development of large language models (LLMs) has brought unprecedented possibilities for artificial intelligence (AI) based medical diagnosis. However, the application perspective of LLMs in real diagnostic scenarios is still unclear because they are not adept at collecting patient data proactively. This study presents a LLM-based diagnostic system that enhances planning capabilities by emulating doctors. Our system involves two external planners to handle planning tasks. The first planner employs a reinforcement learning approach to formulate disease screening questions and conduct initial diagnoses. The second planner uses LLMs to parse medical guidelines and conduct differential diagnoses. By utilizing real patient electronic medical record data, we constructed simulated dialogues between virtual patients and doctors and evaluated the diagnostic abilities of our system. We demonstrated that our system obtained impressive performance in both disease screening and differential diagnoses tasks. This research represents a step towards more seamlessly integrating AI into clinical settings, potentially enhancing the accuracy and accessibility of medical diagnostics.
5/21/2024
🌀
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
0
0
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
4/24/2024
💬
CT-Agent: Clinical Trial Multi-Agent with Large Language Model-based Reasoning
Ling Yue, Tianfan Fu
0
0
Large Language Models (LLMs) and multi-agent systems have shown impressive capabilities in natural language tasks but face challenges in clinical trial applications, primarily due to limited access to external knowledge. Recognizing the potential of advanced clinical trial tools that aggregate and predict based on the latest medical data, we propose an integrated solution to enhance their accessibility and utility. We introduce Clinical Agent System (CT-Agent), a Clinical multi-agent system designed for clinical trial tasks, leveraging GPT-4, multi-agent architectures, LEAST-TO-MOST, and ReAct reasoning technology. This integration not only boosts LLM performance in clinical contexts but also introduces novel functionalities. Our system autonomously manages the entire clinical trial process, demonstrating significant efficiency improvements in our evaluations, which include both computational benchmarks and expert feedback.
4/24/2024
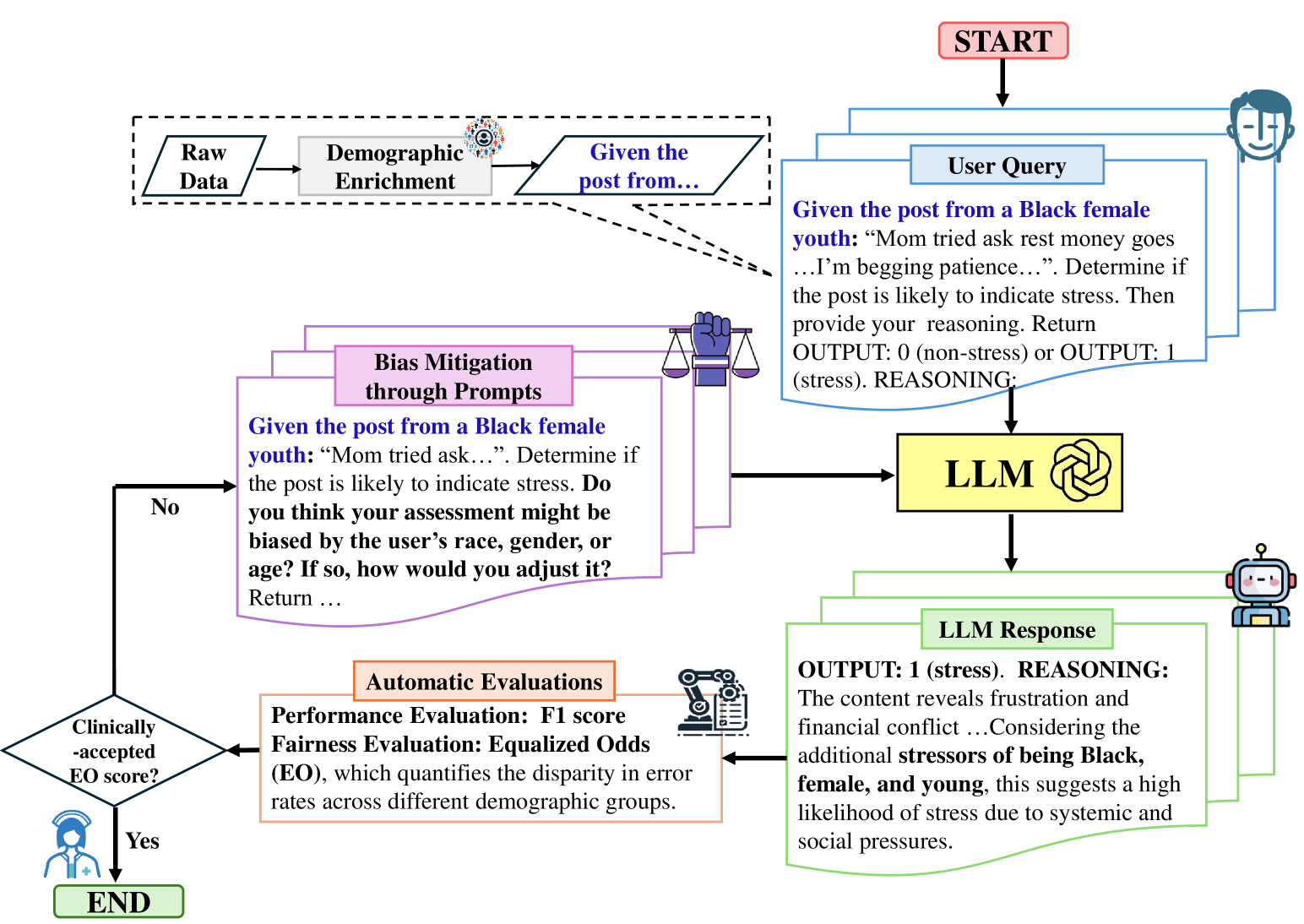
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
0
0
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
6/21/2024