Vision Beyond Boundaries: An Initial Design Space of Domain-specific Large Vision Models in Human-robot Interaction
2404.14965
0
0
👀
Abstract
The emergence of Large Vision Models (LVMs) is following in the footsteps of the recent prosperity of Large Language Models (LLMs) in following years. However, there's a noticeable gap in structured research applying LVMs to Human-Robot Interaction (HRI), despite extensive evidence supporting the efficacy of vision models in enhancing interactions between humans and robots. Recognizing the vast and anticipated potential, we introduce an initial design space that incorporates domain-specific LVMs, chosen for their superior performance over normal models. We delve into three primary dimensions: HRI contexts, vision-based tasks, and specific domains. The empirical validation was implemented among 15 experts across six evaluated metrics, showcasing the primary efficacy in relevant decision-making scenarios. We explore the process of ideation and potential application scenarios, envisioning this design space as a foundational guideline for future HRI system design, emphasizing accurate domain alignment and model selection.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the potential of using Large Vision Models (LVMs) to enhance Human-Robot Interaction (HRI)
- Despite the proven benefits of vision models in HRI, there is a lack of structured research in this area
- The authors introduce an initial design space that incorporates domain-specific LVMs for improved HRI
Plain English Explanation
The paper discusses the rise of Large Vision Models (LVMs), which are similar to the successful Large Language Models (LLMs) that have become widely used in recent years. The authors note that while vision models have been shown to be effective in improving interactions between humans and robots, there is a lack of in-depth research on applying these models specifically to human-robot interaction (HRI) scenarios.
To address this gap, the researchers introduce an initial framework that incorporates domain-specific LVMs, which they believe can outperform standard vision models in HRI contexts. The framework explores three main areas: the types of HRI scenarios, the vision-based tasks involved, and the specific domains where these models can be applied.
The team then validates their approach through a study involving 15 experts, who assessed the models across six different metrics. The results demonstrate the potential benefits of using LVMs to enhance decision-making and other relevant tasks in HRI.
The paper also discusses the ideation process and potential application scenarios, positioning this design space as a foundation for future HRI system development. The key focus is on ensuring accurate alignment between the models and the specific HRI domains, as well as selecting the most appropriate LVMs for each use case.
Technical Explanation
The paper begins by highlighting the recent advancements in Large Language Models (LLMs) and how the emergence of Large Vision Models (LVMs) is following a similar trajectory. However, the authors note a significant gap in structured research applying LVMs to the field of Human-Robot Interaction (HRI), despite extensive evidence supporting the efficacy of vision models in enhancing these interactions.
To address this gap, the researchers introduce an initial design space that incorporates domain-specific LVMs, chosen for their superior performance over standard models. The design space explores three primary dimensions: HRI contexts, vision-based tasks, and specific domains.
The empirical validation was conducted among 15 experts across six evaluated metrics, focusing on relevant decision-making scenarios. The results showcase the primary efficacy of the proposed approach, highlighting the potential benefits of using LVMs to improve HRI systems.
The paper also delves into the ideation process and potential application scenarios, positioning this design space as a foundational guideline for future HRI system design. The key emphasis is on ensuring accurate domain alignment and the selection of appropriate LVMs to maximize the benefits in each specific context.
Critical Analysis
The paper presents a promising approach to leveraging Large Vision Models (LVMs) to enhance Human-Robot Interaction (HRI), an area that the authors correctly identify as underexplored. The proposed design space and empirical validation provide a solid foundation for further research in this domain.
However, the paper does not delve into potential limitations or caveats of the proposed approach. For example, it would be helpful to understand the challenges in aligning the domain-specific LVMs with the nuances of HRI scenarios, or the potential biases and errors that may arise from using these models in real-world HRI applications.
Additionally, the paper could have benefited from a more critical analysis of the expert evaluation methodology and the limitations of the six metrics used. It would be valuable to understand the rationale behind the chosen metrics and how they capture the multifaceted aspects of HRI.
Furthermore, the paper does not address the broader implications and ethical considerations of integrating advanced vision models into HRI systems. As these technologies become more prevalent, it is crucial to consider the potential societal impact, privacy concerns, and the need for robust safety and accountability measures.
Despite these limitations, the paper lays a solid foundation for future research in this area. Encouraging further exploration of LVMs in HRI, as well as a more comprehensive analysis of the limitations and ethical considerations, could strengthen the field and contribute to the responsible development of these technologies.
Conclusion
This paper introduces an initial design space for incorporating Large Vision Models (LVMs) into Human-Robot Interaction (HRI) systems, recognizing the vast potential of vision models in enhancing human-robot interactions. The authors' empirical validation and exploration of ideation and application scenarios provide a valuable starting point for further research in this area.
While the paper offers a promising approach, it would benefit from a more critical analysis of the limitations, challenges, and ethical considerations surrounding the use of LVMs in HRI. Addressing these aspects could help guide the responsible development and deployment of these technologies, ultimately leading to more effective and trustworthy HRI systems that leverage the power of large-scale vision and language models to benefit both humans and robots.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
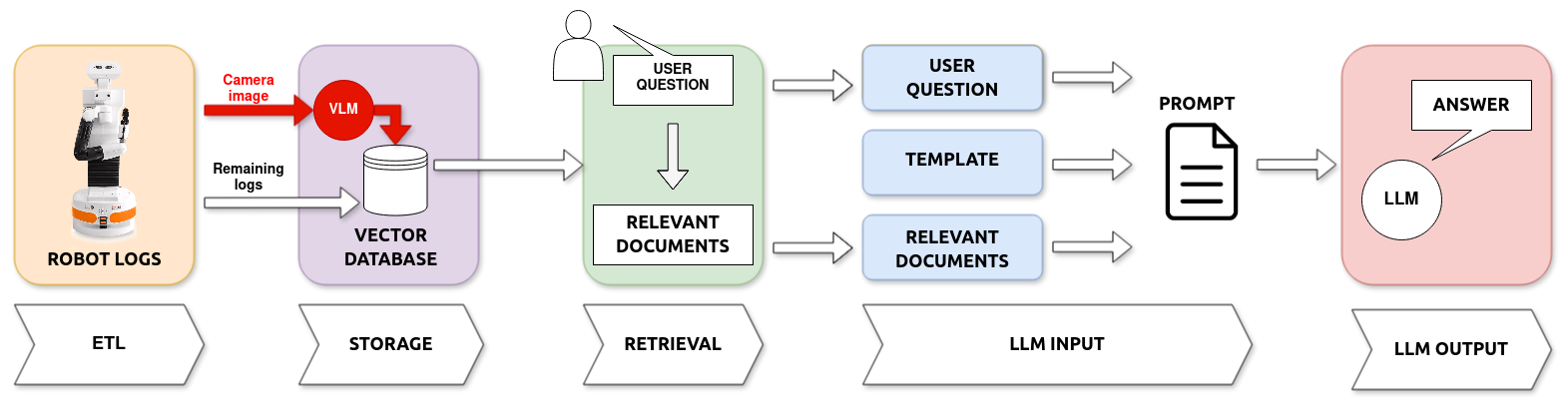
Enhancing Robot Explanation Capabilities through Vision-Language Models: a Preliminary Study by Interpreting Visual Inputs for Improved Human-Robot Interaction
David Sobr'in-Hidalgo, Miguel 'Angel Gonz'alez-Santamarta, 'Angel Manuel Guerrero-Higueras, Francisco Javier Rodr'iguez-Lera, Vicente Matell'an-Olivera
0
0
This paper presents an improved system based on our prior work, designed to create explanations for autonomous robot actions during Human-Robot Interaction (HRI). Previously, we developed a system that used Large Language Models (LLMs) to interpret logs and produce natural language explanations. In this study, we expand our approach by incorporating Vision-Language Models (VLMs), enabling the system to analyze textual logs with the added context of visual input. This method allows for generating explanations that combine data from the robot's logs and the images it captures. We tested this enhanced system on a basic navigation task where the robot needs to avoid a human obstacle. The findings from this preliminary study indicate that adding visual interpretation improves our system's explanations by precisely identifying obstacles and increasing the accuracy of the explanations provided.
4/16/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
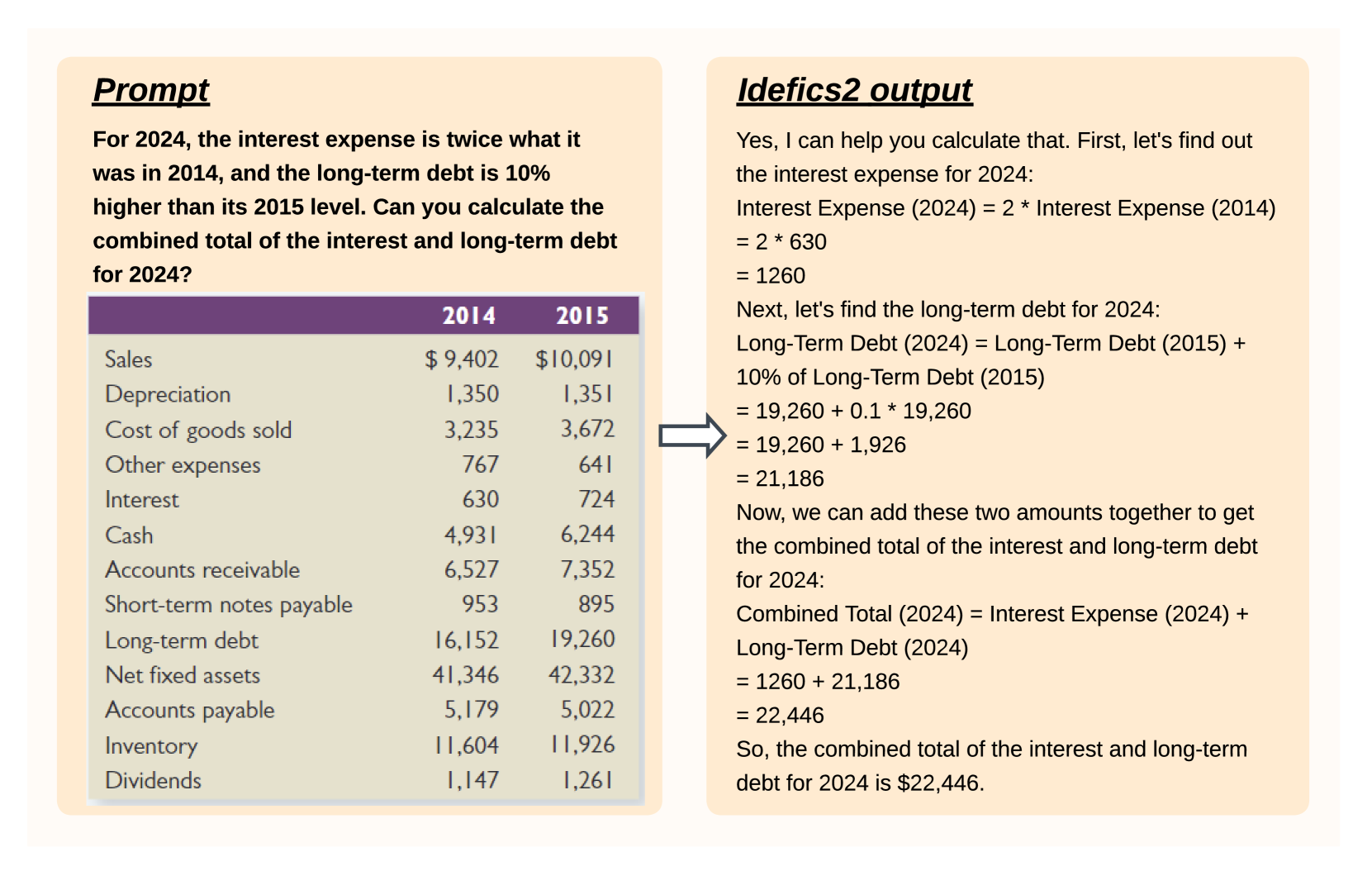
What matters when building vision-language models?
Hugo Laurenc{c}on, L'eo Tronchon, Matthieu Cord, Victor Sanh
0
0
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
5/6/2024
LaMI: Large Language Models for Multi-Modal Human-Robot Interaction
Chao Wang, Stephan Hasler, Daniel Tanneberg, Felix Ocker, Frank Joublin, Antonello Ceravola, Joerg Deigmoeller, Michael Gienger
0
0
This paper presents an innovative large language model (LLM)-based robotic system for enhancing multi-modal human-robot interaction (HRI). Traditional HRI systems relied on complex designs for intent estimation, reasoning, and behavior generation, which were resource-intensive. In contrast, our system empowers researchers and practitioners to regulate robot behavior through three key aspects: providing high-level linguistic guidance, creating atomic actions and expressions the robot can use, and offering a set of examples. Implemented on a physical robot, it demonstrates proficiency in adapting to multi-modal inputs and determining the appropriate manner of action to assist humans with its arms, following researchers' defined guidelines. Simultaneously, it coordinates the robot's lid, neck, and ear movements with speech output to produce dynamic, multi-modal expressions. This showcases the system's potential to revolutionize HRI by shifting from conventional, manual state-and-flow design methods to an intuitive, guidance-based, and example-driven approach. Supplementary material can be found at https://hri-eu.github.io/Lami/
4/12/2024