Enhancing Scene Graph Generation with Hierarchical Relationships and Commonsense Knowledge

0
🛸
Sign in to get full access
Overview
- This paper proposes an enhanced approach to generating scene graphs that incorporates a relationship hierarchy and commonsense knowledge.
- The key innovations are a hierarchical relation head that predicts relation super-categories and detailed relations, as well as a commonsense validation pipeline that removes nonsensical predictions.
- Experiments on Visual Genome and OpenImage V6 datasets show significant improvements in scene graph generation over existing methods.
Plain English Explanation
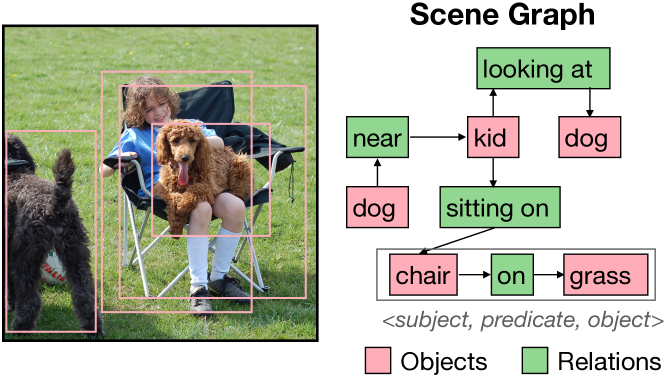
The paper describes a new way to automatically generate scene graphs from images. Scene graphs are a structured representation of the objects, their attributes, and the relationships between them in a scene.
The researchers developed two main improvements to existing scene graph generation methods:
-
Hierarchical Relation Head: Instead of just predicting the specific relationship between pairs of objects (e.g. "on", "next to"), the model first predicts a broader category or "super-category" of the relationship (e.g. "spatial", "functional"). It then predicts the more detailed relationship within that super-category. This hierarchical approach helps the model better understand the semantic structure of relationships.
-
Commonsense Validation: After the initial scene graph is generated, the model runs it through a "commonsense" filter. This uses a separate, language-only model to identify any nonsensical or unrealistic relationships (e.g. "dog riding car") and removes them. This helps ensure the final scene graph is more grounded in real-world knowledge.
The researchers tested their approach on two popular scene graph datasets and found it significantly outperformed existing methods, generating more accurate and reasonable scene graphs. This could have applications in areas like image understanding, visual question answering, and 3D scene understanding.
Technical Explanation
The paper introduces a two-stage scene graph generation approach that first predicts relation super-categories and then detailed relations, as well as a commonsense validation pipeline.
The hierarchical relation head module takes in object feature representations and predicts a relation super-category (e.g. spatial, functional) along with the specific relation (e.g. on, riding) between each pair of objects. This allows the model to capture the semantic structure of relationships.
The commonsense validation module then uses a separate language-only model to evaluate the predicted scene graph. It identifies and removes any nonsensical or unrealistic relationship predictions, helping ensure the final output is grounded in real-world knowledge.
The researchers evaluated their approach on the Visual Genome and OpenImage V6 datasets. They found that integrating the hierarchical relation head and commonsense validation as plug-and-play enhancements to existing scene graph generation models led to significant performance improvements, generating more accurate and reasonable scene graphs compared to prior methods.
Critical Analysis
The paper makes a compelling case for the benefits of incorporating both relational hierarchy and commonsense knowledge into scene graph generation. The hierarchical relation head helps the model better capture the semantic structure of relationships, while the commonsense validation step removes unrealistic predictions.
However, the paper does not provide much insight into the specific limitations or potential failure cases of the commonsense validation module. It would be helpful to know more about the types of unrealistic predictions it is able to detect, as well as any cases where it may incorrectly remove valid relationships.
Additionally, the paper focuses on improving the quality of the final scene graph output, but does not address potential issues around the computational efficiency or inference speed of the overall system. As scene graph generation is often a component of larger computer vision pipelines, the practical deployment of this approach may depend on its resource requirements.
Overall, this research represents a meaningful advance in the field of scene graph generation and could inspire further work on incorporating higher-level reasoning and real-world knowledge into visual understanding systems.
Conclusion
This paper introduces an enhanced approach to scene graph generation that leverages both a hierarchical relation prediction module and a commonsense validation pipeline. By capturing the semantic structure of relationships and filtering out unrealistic predictions, the proposed method generates more accurate and reasonable scene graphs compared to prior state-of-the-art techniques.
The innovations described in this work could have important implications for a variety of computer vision applications that rely on scene understanding, such as image captioning, visual question answering, and 3D scene reconstruction. As the field of visual AI continues to advance, approaches that integrate higher-level reasoning and commonsense knowledge will be crucial for building systems that can truly understand and reason about the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Enhancing Scene Graph Generation with Hierarchical Relationships and Commonsense Knowledge
Bowen Jiang, Zhijun Zhuang, Shreyas S. Shivakumar, Camillo J. Taylor
This work introduces an enhanced approach to generating scene graphs by incorporating both a relationship hierarchy and commonsense knowledge. Specifically, we begin by proposing a hierarchical relation head that exploits an informative hierarchical structure. It jointly predicts the relation super-category between object pairs in an image, along with detailed relations under each super-category. Following this, we implement a robust commonsense validation pipeline that harnesses foundation models to critique the results from the scene graph prediction system, removing nonsensical predicates even with a small language-only model. Extensive experiments on Visual Genome and OpenImage V6 datasets demonstrate that the proposed modules can be seamlessly integrated as plug-and-play enhancements to existing scene graph generation algorithms. The results show significant improvements with an extensive set of reasonable predictions beyond dataset annotations. Codes are available at https://github.com/bowen-upenn/scene_graph_commonsense.
Read more7/18/2024
0
Adaptive Visual Scene Understanding: Incremental Scene Graph Generation
Naitik Khandelwal, Xiao Liu, Mengmi Zhang
Scene graph generation (SGG) involves analyzing images to extract meaningful information about objects and their relationships. Given the dynamic nature of the visual world, it becomes crucial for AI systems to detect new objects and establish their new relationships with existing objects. To address the lack of continual learning methodologies in SGG, we introduce the comprehensive Continual ScenE Graph Generation (CSEGG) dataset along with 3 learning scenarios and 8 evaluation metrics. Our research investigates the continual learning performances of existing SGG methods on the retention of previous object entities and relationships as they learn new ones. Moreover, we also explore how continual object detection enhances generalization in classifying known relationships on unknown objects. We conduct extensive experiments benchmarking and analyzing the classical two-stage SGG methods and the most recent transformer-based SGG methods in continual learning settings, and gain valuable insights into the CSEGG problem. We invite the research community to explore this emerging field of study.
Read more4/15/2024
0
From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
Rongjie Li, Songyang Zhang, Dahua Lin, Kai Chen, Xuming He
Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
Read more4/9/2024
📊
0
GPT4SGG: Synthesizing Scene Graphs from Holistic and Region-specific Narratives
Zuyao Chen, Jinlin Wu, Zhen Lei, Zhaoxiang Zhang, Changwen Chen
Training Scene Graph Generation (SGG) models with natural language captions has become increasingly popular due to the abundant, cost-effective, and open-world generalization supervision signals that natural language offers. However, such unstructured caption data and its processing pose significant challenges in learning accurate and comprehensive scene graphs. The challenges can be summarized as three aspects: 1) traditional scene graph parsers based on linguistic representation often fail to extract meaningful relationship triplets from caption data. 2) grounding unlocalized objects of parsed triplets will meet ambiguity issues in visual-language alignment. 3) caption data typically are sparse and exhibit bias to partial observations of image content. Aiming to address these problems, we propose a divide-and-conquer strategy with a novel framework named textit{GPT4SGG}, to obtain more accurate and comprehensive scene graph signals. This framework decomposes a complex scene into a bunch of simple regions, resulting in a set of region-specific narratives. With these region-specific narratives (partial observations) and a holistic narrative (global observation) for an image, a large language model (LLM) performs the relationship reasoning to synthesize an accurate and comprehensive scene graph. Experimental results demonstrate textit{GPT4SGG} significantly improves the performance of SGG models trained on image-caption data, in which the ambiguity issue and long-tail bias have been well-handled with more accurate and comprehensive scene graphs.
Read more6/4/2024