GPT4SGG: Synthesizing Scene Graphs from Holistic and Region-specific Narratives

0
📊
Sign in to get full access
Overview
- Generating accurate and comprehensive scene graphs from natural language captions is a challenging task.
- Traditional scene graph parsers often fail to extract meaningful relationship triplets from caption data.
- Grounding unlocalized objects in parsed triplets can lead to ambiguity issues in visual-language alignment.
- Caption data is typically sparse and biased towards partial observations of image content.
Plain English Explanation
Scene graphs are a way of representing the objects, their properties, and the relationships between them in an image. Training Scene Graph Generation (SGG) models using natural language captions has become popular because captions provide abundant, cost-effective, and open-world generalization signals. However, this unstructured caption data and its processing pose significant challenges in learning accurate and comprehensive scene graphs.
One challenge is that traditional scene graph parsers, which rely on linguistic representations, often fail to extract meaningful relationship triplets (object-relationship-object) from caption data. Another issue is that grounding the unlocalized objects mentioned in the parsed triplets can be ambiguous when trying to align the visual and language information.
Additionally, caption data is typically sparse and exhibits a bias towards only partially observing the image content. This can lead to incomplete or biased scene graphs that don't accurately represent the full scene.
Technical Explanation
To address these problems, the researchers propose a novel framework called GPT4SGG. This framework takes a "divide-and-conquer" approach, decomposing a complex scene into a set of simple regions and generating region-specific narratives. These partial observations are then combined with a holistic narrative for the entire image, and a large language model (LLM) is used to perform relationship reasoning and synthesize an accurate and comprehensive scene graph.
The key insight is that by breaking down the scene into smaller, more manageable regions, the LLM can better reason about the relationships between objects and generate a more complete scene graph. This helps overcome the ambiguity and bias issues inherent in the caption data.
The researchers' experiments demonstrate that GPT4SGG significantly improves the performance of SGG models trained on image-caption data, producing more accurate and comprehensive scene graphs compared to traditional approaches.
Critical Analysis
While the GPT4SGG framework shows promising results, there are a few potential limitations and areas for further research:
-
The reliance on a large language model might limit the scalability and efficiency of the approach, especially for real-time scene graph generation applications.
-
The researchers do not provide a detailed analysis of the types of errors or biases that the framework is able to mitigate, which could help inform future improvements.
-
It would be interesting to see how GPT4SGG performs on more diverse or challenging datasets, beyond the standard benchmarks used in the paper.
-
Integrating GPT4SGG with other scene graph grounding techniques could further enhance its performance and applicability.
Conclusion
The GPT4SGG framework presents a novel approach to addressing the challenges of learning accurate and comprehensive scene graphs from natural language captions. By decomposing complex scenes into simpler regions and leveraging the reasoning capabilities of large language models, the researchers have found a way to better handle the ambiguity and bias inherent in caption data.
While there are some potential areas for improvement, this research showcases the potential of combining natural language processing and computer vision techniques to tackle complex scene understanding tasks. As this field continues to evolve, we can expect to see more innovative approaches that push the boundaries of what's possible in real-time scene graph generation and other related applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
GPT4SGG: Synthesizing Scene Graphs from Holistic and Region-specific Narratives
Zuyao Chen, Jinlin Wu, Zhen Lei, Zhaoxiang Zhang, Changwen Chen
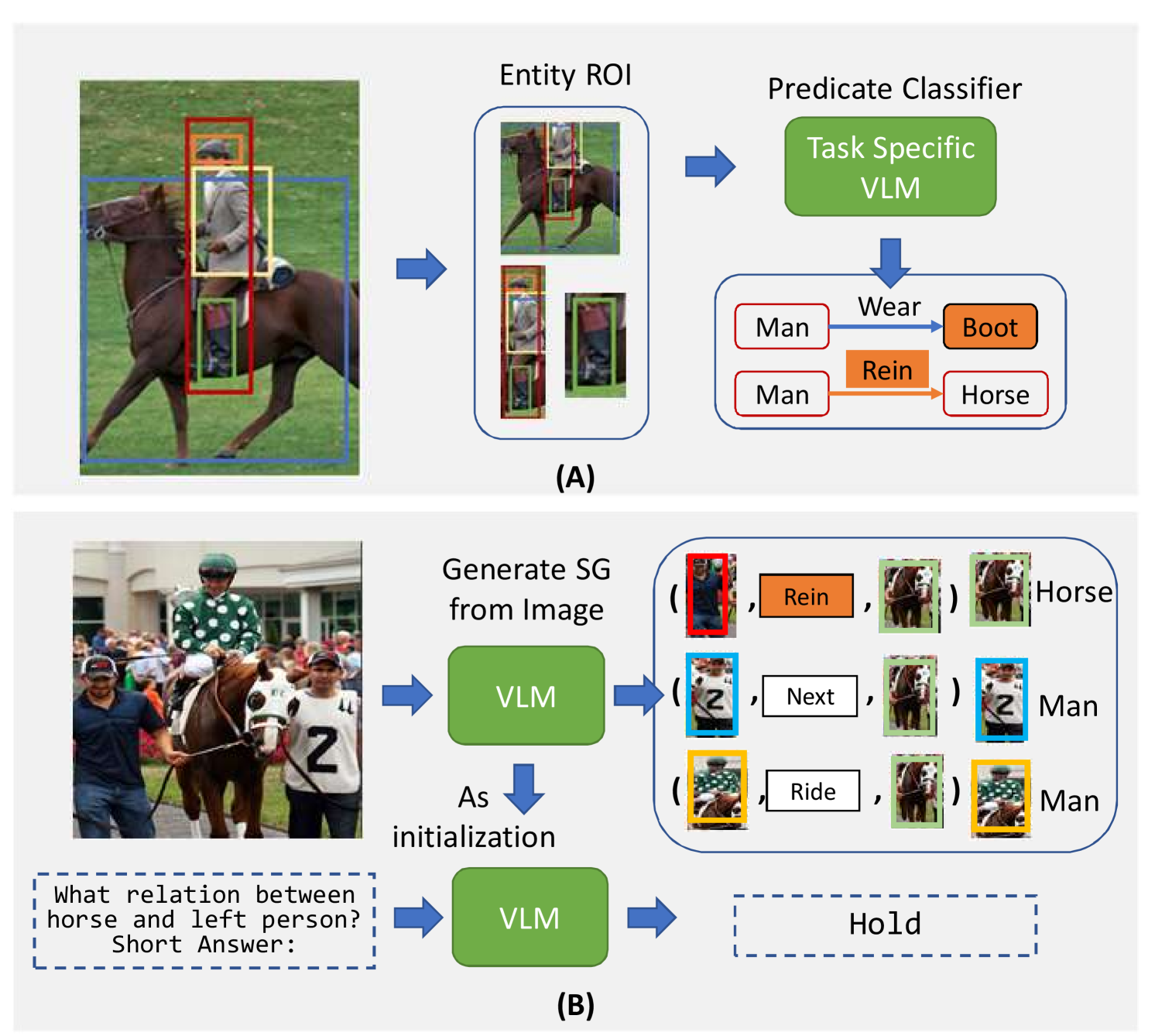
Training Scene Graph Generation (SGG) models with natural language captions has become increasingly popular due to the abundant, cost-effective, and open-world generalization supervision signals that natural language offers. However, such unstructured caption data and its processing pose significant challenges in learning accurate and comprehensive scene graphs. The challenges can be summarized as three aspects: 1) traditional scene graph parsers based on linguistic representation often fail to extract meaningful relationship triplets from caption data. 2) grounding unlocalized objects of parsed triplets will meet ambiguity issues in visual-language alignment. 3) caption data typically are sparse and exhibit bias to partial observations of image content. Aiming to address these problems, we propose a divide-and-conquer strategy with a novel framework named textit{GPT4SGG}, to obtain more accurate and comprehensive scene graph signals. This framework decomposes a complex scene into a bunch of simple regions, resulting in a set of region-specific narratives. With these region-specific narratives (partial observations) and a holistic narrative (global observation) for an image, a large language model (LLM) performs the relationship reasoning to synthesize an accurate and comprehensive scene graph. Experimental results demonstrate textit{GPT4SGG} significantly improves the performance of SGG models trained on image-caption data, in which the ambiguity issue and long-tail bias have been well-handled with more accurate and comprehensive scene graphs.
Read more6/4/2024
0
From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
Rongjie Li, Songyang Zhang, Dahua Lin, Kai Chen, Xuming He
Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
Read more4/9/2024

0
SG-Adapter: Enhancing Text-to-Image Generation with Scene Graph Guidance
Guibao Shen, Luozhou Wang, Jiantao Lin, Wenhang Ge, Chaozhe Zhang, Xin Tao, Yuan Zhang, Pengfei Wan, Zhongyuan Wang, Guangyong Chen, Yijun Li, Ying-Cong Chen
Recent advancements in text-to-image generation have been propelled by the development of diffusion models and multi-modality learning. However, since text is typically represented sequentially in these models, it often falls short in providing accurate contextualization and structural control. So the generated images do not consistently align with human expectations, especially in complex scenarios involving multiple objects and relationships. In this paper, we introduce the Scene Graph Adapter(SG-Adapter), leveraging the structured representation of scene graphs to rectify inaccuracies in the original text embeddings. The SG-Adapter's explicit and non-fully connected graph representation greatly improves the fully connected, transformer-based text representations. This enhancement is particularly notable in maintaining precise correspondence in scenarios involving multiple relationships. To address the challenges posed by low-quality annotated datasets like Visual Genome, we have manually curated a highly clean, multi-relational scene graph-image paired dataset MultiRels. Furthermore, we design three metrics derived from GPT-4V to effectively and thoroughly measure the correspondence between images and scene graphs. Both qualitative and quantitative results validate the efficacy of our approach in controlling the correspondence in multiple relationships.
Read more5/27/2024

0
Adaptive Self-training Framework for Fine-grained Scene Graph Generation
Kibum Kim, Kanghoon Yoon, Yeonjun In, Jinyoung Moon, Donghyun Kim, Chanyoung Park
Scene graph generation (SGG) models have suffered from inherent problems regarding the benchmark datasets such as the long-tailed predicate distribution and missing annotation problems. In this work, we aim to alleviate the long-tailed problem of SGG by utilizing unannotated triplets. To this end, we introduce a Self-Training framework for SGG (ST-SGG) that assigns pseudo-labels for unannotated triplets based on which the SGG models are trained. While there has been significant progress in self-training for image recognition, designing a self-training framework for the SGG task is more challenging due to its inherent nature such as the semantic ambiguity and the long-tailed distribution of predicate classes. Hence, we propose a novel pseudo-labeling technique for SGG, called Class-specific Adaptive Thresholding with Momentum (CATM), which is a model-agnostic framework that can be applied to any existing SGG models. Furthermore, we devise a graph structure learner (GSL) that is beneficial when adopting our proposed self-training framework to the state-of-the-art message-passing neural network (MPNN)-based SGG models. Our extensive experiments verify the effectiveness of ST-SGG on various SGG models, particularly in enhancing the performance on fine-grained predicate classes.
Read more8/6/2024