Indoor and Outdoor 3D Scene Graph Generation via Language-Enabled Spatial Ontologies

0
Sign in to get full access
Overview
- This paper presents a method for generating 3D scene graphs from natural language descriptions of indoor and outdoor environments.
- The approach leverages language-enabled spatial ontologies to capture the semantic and spatial relationships between objects in a scene.
- The resulting scene graphs can be used for various applications, such as scene understanding, navigation, and augmented reality.
Plain English Explanation
The paper describes a way to create detailed 3D models of indoor and outdoor spaces based on textual descriptions. The researchers developed a system that can take a natural language description of a scene, such as "There is a table in the middle of the room with a vase on it," and use that information to automatically generate a 3D diagram, or "scene graph," that visually represents the spatial relationships between the objects in the scene.
This is useful because it allows computers to better understand the contents and layout of a space based on how people naturally describe it in words. Rather than trying to piece together a 3D model from raw sensor data, the system can leverage the rich semantic information contained in language to quickly build an accurate representation of a scene.
The key innovation is the use of "spatial ontologies" - databases that formally define the different types of objects that can exist in a space and how they are typically arranged in relation to one another. By mapping the linguistic description to these ontological concepts, the system can infer the 3D structure and create an interactive 3D model.
This technology could have applications in areas like scene understanding, navigation, and augmented reality. For example, a robot could use this to build an internal map of its surroundings by listening to a human describe the room. Or an AR app could overlay virtual objects onto the real world in a more semantically-meaningful way.
Technical Explanation
The core of the approach is a neural network-based model that takes a natural language scene description as input and generates a 3D scene graph as output. The scene graph encodes the semantic and spatial relationships between objects in the scene, represented as nodes (entities) and edges (relations).
To enable this, the model leverages language-enabled spatial ontologies - structured knowledge bases that formally define the different types of objects that can exist in a space, and the typical spatial configurations they have relative to one another. These ontologies are used to map the linguistic input to a set of candidate 3D object instances and their spatial relationships.
The neural network architecture consists of two main components: a language encoder that processes the input text, and a graph decoder that generates the output scene graph. The language encoder uses transformer-based models to embed the semantic and syntactic information from the text. The graph decoder then predicts the objects, their attributes, and the relations between them in a iterative, auto-regressive fashion.
The model is trained end-to-end on datasets of textual scene descriptions paired with ground truth 3D scene graphs. Experiments show that it is able to generate accurate scene graphs for both indoor and outdoor environments, outperforming previous methods that relied on rule-based language parsing or 2D image understanding.
Critical Analysis
A key strength of this approach is its ability to leverage rich semantic information from natural language to construct detailed 3D scene representations, going beyond what can be inferred from raw sensor data alone. The use of spatial ontologies is a clever way to bridge the gap between linguistic and visual understanding of a space.
However, the paper also acknowledges some important limitations. The ontologies used in the experiments cover a relatively narrow set of object categories and spatial relations, so the system may struggle with more complex or unconventional scenes. Additionally, the training datasets are still relatively small, so the model's performance may be sensitive to the specific distribution of scenes it is exposed to during learning.
Further research could explore ways to expand the ontological knowledge, potentially by dynamically integrating it with large-scale commonsense reasoning systems. Techniques like open-vocabulary scene parsing could also help the model handle a wider range of objects and spatial configurations.
Additionally, the paper does not discuss how the generated scene graphs could be used in downstream applications like efficient exploration, scene retrieval, or augmented reality. Further work is needed to demonstrate the practical utility of this technology in real-world settings.
Conclusion
This paper presents a novel approach for generating 3D scene graphs from natural language descriptions, leveraging language-enabled spatial ontologies. The resulting scene representations capture rich semantic and spatial information that could enable a wide range of applications in areas like scene understanding, navigation, and augmented reality.
While the current system has some limitations, the core idea of bridging linguistic and visual understanding of space is a promising direction for further research. Expanding the ontological knowledge and exploring how the scene graphs can be used in downstream tasks could help unlock the full potential of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Indoor and Outdoor 3D Scene Graph Generation via Language-Enabled Spatial Ontologies
Jared Strader, Nathan Hughes, William Chen, Alberto Speranzon, Luca Carlone
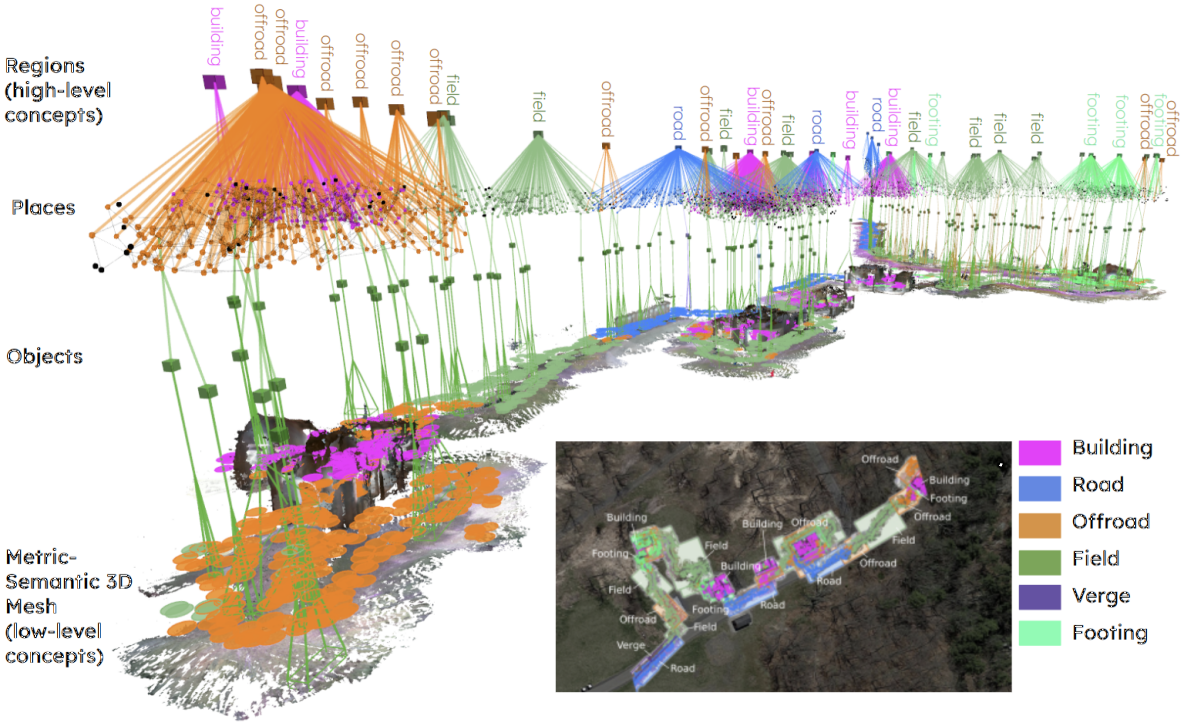
This paper proposes an approach to build 3D scene graphs in arbitrary indoor and outdoor environments. Such extension is challenging; the hierarchy of concepts that describe an outdoor environment is more complex than for indoors, and manually defining such hierarchy is time-consuming and does not scale. Furthermore, the lack of training data prevents the straightforward application of learning-based tools used in indoor settings. To address these challenges, we propose two novel extensions. First, we develop methods to build a spatial ontology defining concepts and relations relevant for indoor and outdoor robot operation. In particular, we use a Large Language Model (LLM) to build such an ontology, thus largely reducing the amount of manual effort required. Second, we leverage the spatial ontology for 3D scene graph construction using Logic Tensor Networks (LTN) to add logical rules, or axioms (e.g., a beach contains sand), which provide additional supervisory signals at training time thus reducing the need for labelled data, providing better predictions, and even allowing predicting concepts unseen at training time. We test our approach in a variety of datasets, including indoor, rural, and coastal environments, and show that it leads to a significant increase in the quality of the 3D scene graph generation with sparsely annotated data.
Read more4/26/2024
0
Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation
Abdelrhman Werby, Chenguang Huang, Martin Buchner, Abhinav Valada, Wolfram Burgard
Recent open-vocabulary robot mapping methods enrich dense geometric maps with pre-trained visual-language features. While these maps allow for the prediction of point-wise saliency maps when queried for a certain language concept, large-scale environments and abstract queries beyond the object level still pose a considerable hurdle, ultimately limiting language-grounded robotic navigation. In this work, we present HOV-SG, a hierarchical open-vocabulary 3D scene graph mapping approach for language-grounded robot navigation. Leveraging open-vocabulary vision foundation models, we first obtain state-of-the-art open-vocabulary segment-level maps in 3D and subsequently construct a 3D scene graph hierarchy consisting of floor, room, and object concepts, each enriched with open-vocabulary features. Our approach is able to represent multi-story buildings and allows robotic traversal of those using a cross-floor Voronoi graph. HOV-SG is evaluated on three distinct datasets and surpasses previous baselines in open-vocabulary semantic accuracy on the object, room, and floor level while producing a 75% reduction in representation size compared to dense open-vocabulary maps. In order to prove the efficacy and generalization capabilities of HOV-SG, we showcase successful long-horizon language-conditioned robot navigation within real-world multi-storage environments. We provide code and trial video data at http://hovsg.github.io/.
Read more6/4/2024

0
SceneTeller: Language-to-3D Scene Generation
Bac{s}ak Melis Ocal, Maxim Tatarchenko, Sezer Karaoglu, Theo Gevers
Designing high-quality indoor 3D scenes is important in many practical applications, such as room planning or game development. Conventionally, this has been a time-consuming process which requires both artistic skill and familiarity with professional software, making it hardly accessible for layman users. However, recent advances in generative AI have established solid foundation for democratizing 3D design. In this paper, we propose a pioneering approach for text-based 3D room design. Given a prompt in natural language describing the object placement in the room, our method produces a high-quality 3D scene corresponding to it. With an additional text prompt the users can change the appearance of the entire scene or of individual objects in it. Built using in-context learning, CAD model retrieval and 3D-Gaussian-Splatting-based stylization, our turnkey pipeline produces state-of-the-art 3D scenes, while being easy to use even for novices. Our project page is available at https://sceneteller.github.io/.
Read more7/31/2024

0
Planner3D: LLM-enhanced graph prior meets 3D indoor scene explicit regularization
Yao Wei, Martin Renqiang Min, George Vosselman, Li Erran Li, Michael Ying Yang
Compositional 3D scene synthesis has diverse applications across a spectrum of industries such as robotics, films, and video games, as it closely mirrors the complexity of real-world multi-object environments. Conventional works typically employ shape retrieval based frameworks which naturally suffer from limited shape diversity. Recent progresses have been made in object shape generation with generative models such as diffusion models, which increases the shape fidelity. However, these approaches separately treat 3D shape generation and layout generation. The synthesized scenes are usually hampered by layout collision, which suggests that the scene-level fidelity is still under-explored. In this paper, we aim at generating realistic and reasonable 3D indoor scenes from scene graph. To enrich the priors of the given scene graph inputs, large language model is utilized to aggregate the global-wise features with local node-wise and edge-wise features. With a unified graph encoder, graph features are extracted to guide joint layout-shape generation. Additional regularization is introduced to explicitly constrain the produced 3D layouts. Benchmarked on the SG-FRONT dataset, our method achieves better 3D scene synthesis, especially in terms of scene-level fidelity. The source code will be released after publication.
Read more8/27/2024