Enhancing Software Related Information Extraction with Generative Language Models through Single-Choice Question Answering

0
⛏️
Sign in to get full access
Overview
- Explores using generative language models to improve software-related information extraction tasks
- Focuses on single-choice question answering as a way to enhance named entity recognition, relation extraction, and software citation retrieval
- Introduces a new dataset of software-related questions and evaluates different language model approaches
Plain English Explanation
This research paper looks at how advanced language models, like those used in chatbots and virtual assistants, can be used to better extract relevant information from text about software projects and development. The key idea is to use a technique called "single-choice question answering" to help the language models identify important named entities (like software names or author names), understand relationships between them, and retrieve relevant citations.
The researchers created a new dataset of software-related questions that can be answered by finding information in text. They then experimented with different language model approaches to see which ones performed best at this task. The goal is to develop better AI tools that can automatically parse software-related documents and pull out the key facts and connections - things that are currently quite challenging for computers to do.
Evaluating Generative Language Models for Information Extraction and Improving Medical Reasoning Through Retrieval and Self-Reflection are two related papers that also explore using language models for information extraction tasks in specialized domains.
Technical Explanation
The paper presents a new approach for enhancing software-related information extraction using generative language models. The key innovation is framing the tasks of named entity recognition, relation extraction, and software citation retrieval as single-choice question answering problems.
The researchers created a new dataset called SoftQA, which contains over 10,000 questions about software projects, authors, and citations that can be answered from given text passages. They then evaluated different language model architectures, including T5, BART, and GPT, on this dataset, measuring their performance on the question answering task as a proxy for assessing their ability to extract relevant software-related information.
The results show that fine-tuning large language models on the SoftQA dataset can significantly improve their performance on software-related information extraction compared to standard fine-tuning on general-purpose datasets. The paper also presents detailed analyses on the strengths and weaknesses of different modeling approaches.
Related work in Intent Detection and Entity Extraction from Biomedical Literature, CONFLARE: Conformal Large Language Model Retrieval, and PerKweCOQA: Enhancing Persian Conversational Question Answering explores similar ideas of using language models for information extraction and question answering in other specialized domains.
Critical Analysis
The paper presents a novel and promising approach for improving software-related information extraction using language models. The single-choice question answering framing is an interesting way to leverage the strengths of large language models, and the SoftQA dataset provides a valuable resource for evaluating and comparing different modeling techniques.
However, the paper does not deeply explore the potential limitations or failure modes of this approach. For example, the dataset may not fully capture the complexity and nuance of real-world software documentation, and the language models may struggle with ambiguous or contextual references that humans can easily resolve.
Additionally, the paper does not discuss the computational and memory requirements of fine-tuning large language models, which could be a significant barrier to practical deployment, especially for smaller research teams or organizations.
Further research could investigate ways to make the language model-based information extraction more robust, efficient, and adaptable to different software ecosystems and documentation styles. Integrating this approach with other information extraction techniques, such as rule-based or knowledge-based methods, could also be a fruitful area for exploration.
Conclusion
This research paper presents a novel approach for enhancing software-related information extraction using generative language models and single-choice question answering. The results demonstrate the potential of this technique to improve the automatic parsing and understanding of software documentation, which could have significant implications for tasks like software search, citation management, and knowledge management.
While the paper provides a solid foundation, there are still many open challenges and areas for further development. Continued research in this direction could lead to more powerful AI-powered tools for software engineers, researchers, and others working with large volumes of technical documentation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
Enhancing Software Related Information Extraction with Generative Language Models through Single-Choice Question Answering
Wolfgang Otto, Sharmila Upadhyaya, Stefan Dietze
This paper describes our participation in the Shared Task on Software Mentions Disambiguation (SOMD), with a focus on improving relation extraction in scholarly texts through generative Large Language Models (LLMs) using single-choice question-answering. The methodology prioritises the use of in-context learning capabilities of GLMs to extract software-related entities and their descriptive attributes, such as distributive information. Our approach uses Retrieval-Augmented Generation (RAG) techniques and GLMs for Named Entity Recognition (NER) and Attributive NER to identify relationships between extracted software entities, providing a structured solution for analysing software citations in academic literature. The paper provides a detailed description of our approach, demonstrating how using GLMs in a single-choice QA paradigm can greatly enhance IE methodologies. Our participation in the SOMD shared task highlights the importance of precise software citation practices and showcases our system's ability to overcome the challenges of disambiguating and extracting relationships between software mentions. This sets the groundwork for future research and development in this field.
Read more4/23/2024

0
Scholarly Question Answering using Large Language Models in the NFDI4DataScience Gateway
Hamed Babaei Giglou, Tilahun Abedissa Taffa, Rana Abdullah, Aida Usmanova, Ricardo Usbeck, Jennifer D'Souza, Soren Auer
This paper introduces a scholarly Question Answering (QA) system on top of the NFDI4DataScience Gateway, employing a Retrieval Augmented Generation-based (RAG) approach. The NFDI4DS Gateway, as a foundational framework, offers a unified and intuitive interface for querying various scientific databases using federated search. The RAG-based scholarly QA, powered by a Large Language Model (LLM), facilitates dynamic interaction with search results, enhancing filtering capabilities and fostering a conversational engagement with the Gateway search. The effectiveness of both the Gateway and the scholarly QA system is demonstrated through experimental analysis.
Read more6/12/2024
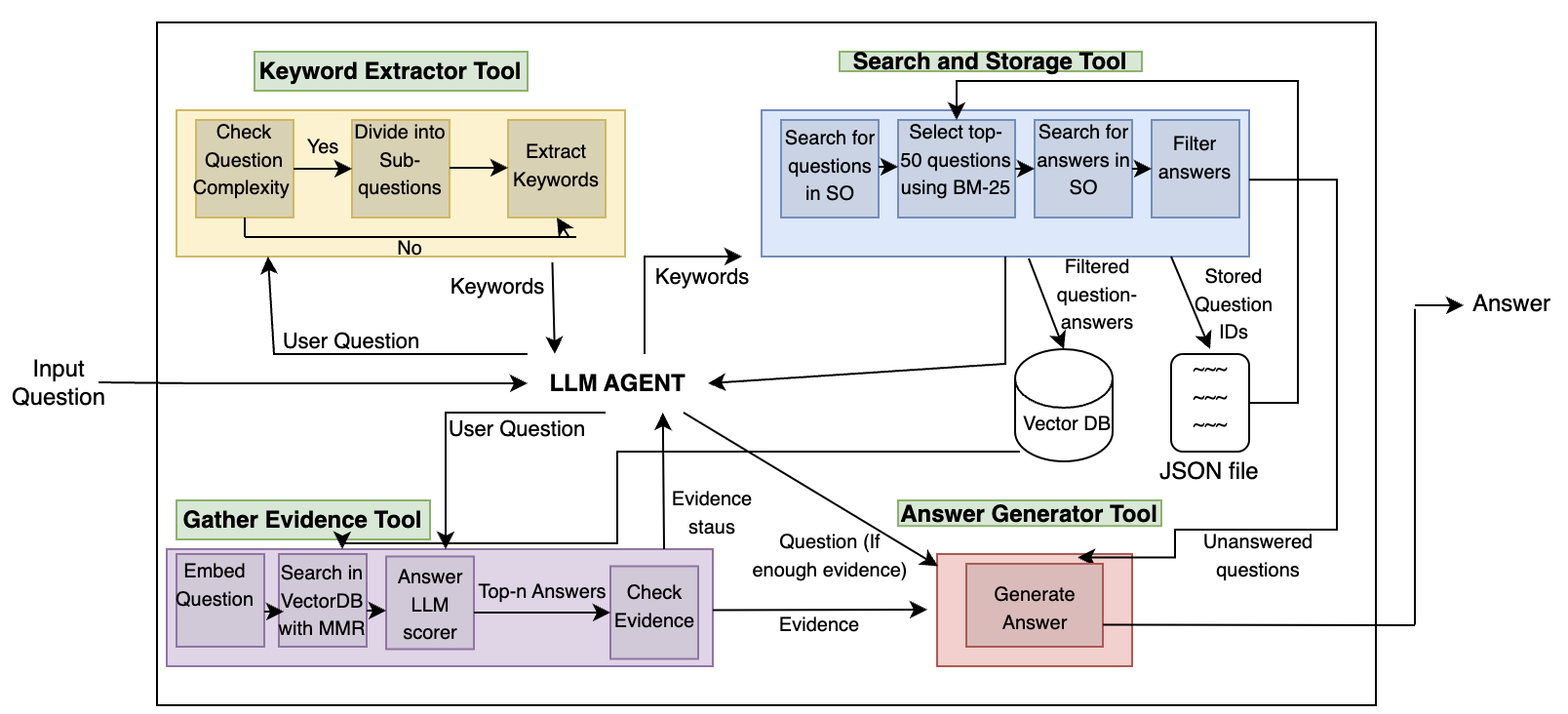
0
StackRAG Agent: Improving Developer Answers with Retrieval-Augmented Generation
Davit Abrahamyan, Fatemeh H. Fard
Developers spend much time finding information that is relevant to their questions. Stack Overflow has been the leading resource, and with the advent of Large Language Models (LLMs), generative models such as ChatGPT are used frequently. However, there is a catch in using each one separately. Searching for answers is time-consuming and tedious, as shown by the many tools developed by researchers to address this issue. On the other, using LLMs is not reliable, as they might produce irrelevant or unreliable answers (i.e., hallucination). In this work, we present StackRAG, a retrieval-augmented Multiagent generation tool based on LLMs that combines the two worlds: aggregating the knowledge from SO to enhance the reliability of the generated answers. Initial evaluations show that the generated answers are correct, accurate, relevant, and useful.
Read more6/21/2024
👁️
0
Software Mention Recognition with a Three-Stage Framework Based on BERTology Models at SOMD 2024
Thuy Nguyen Thi, Anh Nguyen Viet, Thin Dang Van, Ngan Nguyen Luu Thuy
This paper describes our systems for the sub-task I in the Software Mention Detection in Scholarly Publications shared-task. We propose three approaches leveraging different pre-trained language models (BERT, SciBERT, and XLM-R) to tackle this challenge. Our bestperforming system addresses the named entity recognition (NER) problem through a three-stage framework. (1) Entity Sentence Classification - classifies sentences containing potential software mentions; (2) Entity Extraction - detects mentions within classified sentences; (3) Entity Type Classification - categorizes detected mentions into specific software types. Experiments on the official dataset demonstrate that our three-stage framework achieves competitive performance, surpassing both other participating teams and our alternative approaches. As a result, our framework based on the XLM-R-based model achieves a weighted F1-score of 67.80%, delivering our team the 3rd rank in Sub-task I for the Software Mention Recognition task.
Read more5/6/2024