EventLens: Leveraging Event-Aware Pretraining and Cross-modal Linking Enhances Visual Commonsense Reasoning
2404.13847
0
0

Abstract
Visual Commonsense Reasoning (VCR) is a cognitive task, challenging models to answer visual questions requiring human commonsense, and to provide rationales explaining why the answers are correct. With emergence of Large Language Models (LLMs), it is natural and imperative to explore their applicability to VCR. However, VCR task demands more external knowledge to tackle its challenging questions, necessitating special designs to activate LLMs' commonsense reasoning abilities. Also, most existing Multimodal LLMs adopted an abstraction of entire input image, which makes it difficult to comprehend VCR's unique co-reference tags between image regions and text, posing challenges for fine-grained alignment. To address these issues, we propose EventLens that leverages Event-Aware Pretraining and Cross-modal Linking and EnhanceS VCR. First, by emulating the cognitive process of human reasoning, an Event-Aware Pretraining auxiliary task is introduced to better activate LLM's global comprehension of intricate scenarios. Second, during fine-tuning, we further utilize reference tags to bridge RoI features with texts, while preserving both modality semantics. Finally, we use instruct-style prompts to narrow the gap between pretraining and fine-tuning, and task-specific adapters to better integrate LLM's inherent knowledge with new commonsense. Experimental results show the effectiveness of our proposed auxiliary task and fine-grained linking strategy.
Create account to get full access
Overview
- This paper introduces EventLens, a model that leverages event-aware pretraining and cross-modal linking to enhance visual commonsense reasoning.
- Visual commonsense reasoning is the ability to understand and reason about common real-world situations and events depicted in images.
- EventLens aims to improve performance on visual commonsense reasoning tasks by incorporating information about events and their relationships.
Plain English Explanation
EventLens is a new model that tries to help computers better understand images by using information about events and how they are connected. When we look at an image, we can usually make sense of what's happening based on our common sense knowledge about the world. For example, if we see someone cooking in a kitchen, we can infer that they are likely preparing a meal.
The researchers behind EventLens wanted to teach their model this kind of common sense reasoning about events and situations depicted in images. To do this, they first trained the model on a large amount of text data about events, so it could learn how different events are related to each other. Then, they connected this event knowledge to the visual information in images, allowing the model to link what it sees in the image to its understanding of the underlying events and situations.
By incorporating this event-based knowledge, EventLens was able to outperform other models on various visual commonsense reasoning tasks. This suggests that understanding the events and relationships in an image is crucial for making sense of the common real-world situations depicted.
Technical Explanation
The key innovations in EventLens are:
-
Event-Aware Pretraining: The model is first pretrained on a large corpus of textual event data, allowing it to learn about different types of events and how they are related. This event knowledge is then used to enhance the model's understanding of visual scenes.
-
Cross-Modal Linking: EventLens connects the event knowledge from the pretraining stage to the visual information in images through a cross-modal linking module. This allows the model to reason about the events and situations depicted in the visual data.
The researchers evaluated EventLens on several visual commonsense reasoning benchmarks, including VCR, CVIST, and Visual7W. Compared to other state-of-the-art models, EventLens demonstrated improved performance, highlighting the benefits of incorporating event-based knowledge for this task.
VLLMS Provide Better Context for Emotion Understanding Through Cross-Modal Reasoning
Critical Analysis
One potential limitation of the EventLens approach is that it relies heavily on the quality and coverage of the event knowledge acquired during pretraining. If the pretraining data does not adequately capture the full range of real-world events and their relationships, the model's commonsense reasoning capabilities may be constrained.
Additionally, the cross-modal linking module introduces additional complexity and potential points of failure in the model architecture. The researchers would need to carefully design and evaluate this component to ensure it is effectively integrating the event and visual information.
Vision-Language Navigation via Causal Learning
Further research could explore ways to dynamically acquire and update the event knowledge, perhaps through interaction with humans or by learning directly from large-scale web data. This could help the model stay current with evolving real-world events and situations.
General Training-Free Generative Framework for Multimodal Event Extraction
Conclusion
The EventLens model demonstrates the potential benefits of incorporating event-based knowledge for enhancing visual commonsense reasoning. By leveraging event-aware pretraining and cross-modal linking, the model is able to outperform other state-of-the-art approaches on several benchmark tasks.
This research highlights the importance of contextual understanding and the need to go beyond purely visual processing to tackle complex reasoning tasks. As AI systems continue to advance, the integration of diverse knowledge sources, such as event information, will likely be crucial for developing more robust and intelligent visual understanding capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
ViCor: Bridging Visual Understanding and Commonsense Reasoning with Large Language Models
Kaiwen Zhou, Kwonjoon Lee, Teruhisa Misu, Xin Eric Wang
0
0
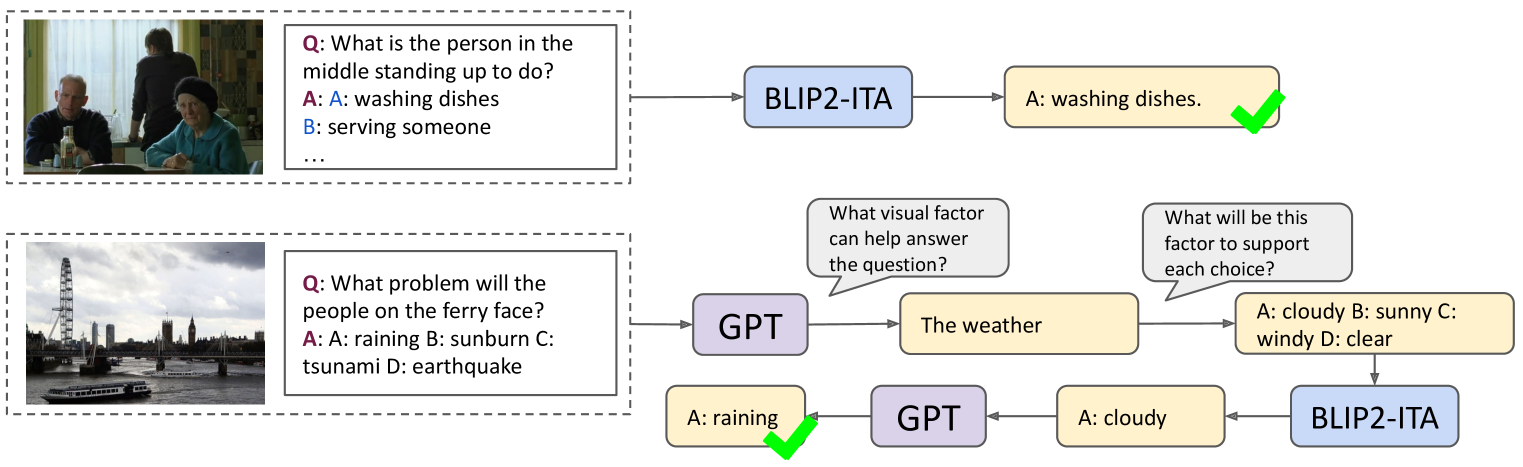
In our work, we explore the synergistic capabilities of pre-trained vision-and-language models (VLMs) and large language models (LLMs) on visual commonsense reasoning (VCR) problems. We find that VLMs and LLMs-based decision pipelines are good at different kinds of VCR problems. Pre-trained VLMs exhibit strong performance for problems involving understanding the literal visual content, which we noted as visual commonsense understanding (VCU). For problems where the goal is to infer conclusions beyond image content, which we noted as visual commonsense inference (VCI), VLMs face difficulties, while LLMs, given sufficient visual evidence, can use commonsense to infer the answer well. We empirically validate this by letting LLMs classify VCR problems into these two categories and show the significant difference between VLM and LLM with image caption decision pipelines on two subproblems. Moreover, we identify a challenge with VLMs' passive perception, which may miss crucial context information, leading to incorrect reasoning by LLMs. Based on these, we suggest a collaborative approach, named ViCor, where pre-trained LLMs serve as problem classifiers to analyze the problem category, then either use VLMs to answer the question directly or actively instruct VLMs to concentrate on and gather relevant visual elements to support potential commonsense inferences. We evaluate our framework on two VCR benchmark datasets and outperform all other methods that do not require in-domain fine-tuning.
5/20/2024

Do Vision-Language Transformers Exhibit Visual Commonsense? An Empirical Study of VCR
Zhenyang Li, Yangyang Guo, Kejie Wang, Xiaolin Chen, Liqiang Nie, Mohan Kankanhalli
0
0
Visual Commonsense Reasoning (VCR) calls for explanatory reasoning behind question answering over visual scenes. To achieve this goal, a model is required to provide an acceptable rationale as the reason for the predicted answers. Progress on the benchmark dataset stems largely from the recent advancement of Vision-Language Transformers (VL Transformers). These models are first pre-trained on some generic large-scale vision-text datasets, and then the learned representations are transferred to the downstream VCR task. Despite their attractive performance, this paper posits that the VL Transformers do not exhibit visual commonsense, which is the key to VCR. In particular, our empirical results pinpoint several shortcomings of existing VL Transformers: small gains from pre-training, unexpected language bias, limited model architecture for the two inseparable sub-tasks, and neglect of the important object-tag correlation. With these findings, we tentatively suggest some future directions from the aspect of dataset, evaluation metric, and training tricks. We believe this work could make researchers revisit the intuition and goals of VCR, and thus help tackle the remaining challenges in visual reasoning.
5/28/2024
Improving Visual Commonsense in Language Models via Multiple Image Generation
Guy Yariv, Idan Schwartz, Yossi Adi, Sagie Benaim
0
0
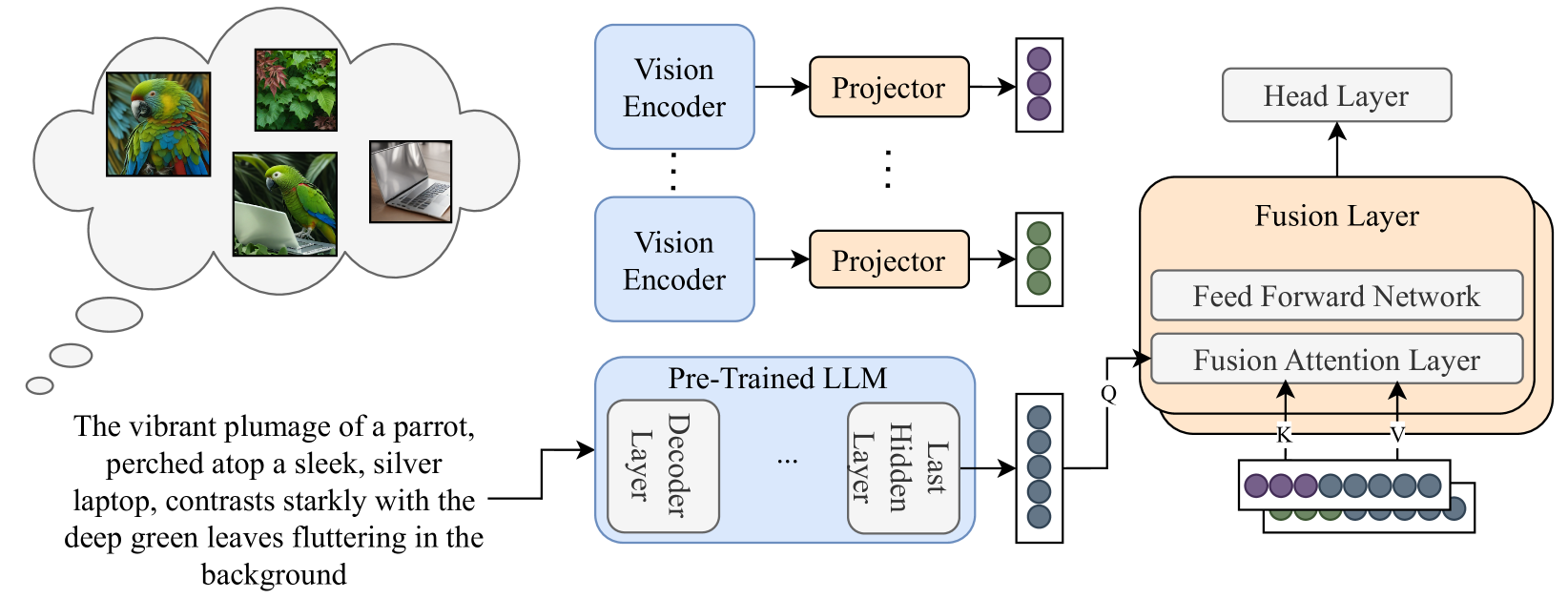
Commonsense reasoning is fundamentally based on multimodal knowledge. However, existing large language models (LLMs) are primarily trained using textual data only, limiting their ability to incorporate essential visual information. In contrast, Visual Language Models, which excel at visually-oriented tasks, often fail at non-visual tasks such as basic commonsense reasoning. This divergence highlights a critical challenge - the integration of robust visual understanding with foundational text-based language reasoning. To this end, we introduce a method aimed at enhancing LLMs' visual commonsense. Specifically, our method generates multiple images based on the input text prompt and integrates these into the model's decision-making process by mixing their prediction probabilities. To facilitate multimodal grounded language modeling, we employ a late-fusion layer that combines the projected visual features with the output of a pre-trained LLM conditioned on text only. This late-fusion layer enables predictions based on comprehensive image-text knowledge as well as text only when this is required. We evaluate our approach using several visual commonsense reasoning tasks together with traditional NLP tasks, including common sense reasoning and reading comprehension. Our experimental results demonstrate significant superiority over existing baselines. When applied to recent state-of-the-art LLMs (e.g., Llama3), we observe improvements not only in visual common sense but also in traditional NLP benchmarks. Code and models are available under https://github.com/guyyariv/vLMIG.
6/21/2024

VCR: Visual Caption Restoration
Tianyu Zhang, Suyuchen Wang, Lu Li, Ge Zhang, Perouz Taslakian, Sai Rajeswar, Jie Fu, Bang Liu, Yoshua Bengio
0
0
We introduce Visual Caption Restoration (VCR), a novel vision-language task that challenges models to accurately restore partially obscured texts using pixel-level hints within images. This task stems from the observation that text embedded in images is intrinsically different from common visual elements and natural language due to the need to align the modalities of vision, text, and text embedded in images. While numerous works have integrated text embedded in images into visual question-answering tasks, approaches to these tasks generally rely on optical character recognition or masked language modeling, thus reducing the task to mainly text-based processing. However, text-based processing becomes ineffective in VCR as accurate text restoration depends on the combined information from provided images, context, and subtle cues from the tiny exposed areas of masked texts. We develop a pipeline to generate synthetic images for the VCR task using image-caption pairs, with adjustable caption visibility to control the task difficulty. With this pipeline, we construct a dataset for VCR called VCR-Wiki using images with captions from Wikipedia, comprising 2.11M English and 346K Chinese entities in both easy and hard split variants. Our results reveal that current vision language models significantly lag behind human performance in the VCR task, and merely fine-tuning the models on our dataset does not lead to notable improvements. We release VCR-Wiki and the data construction code to facilitate future research.
6/26/2024