GenEARL: A Training-Free Generative Framework for Multimodal Event Argument Role Labeling

0
Sign in to get full access
Overview
- This paper introduces GenEARL, a new training-free generative framework for multimodal event argument role labeling (EARL).
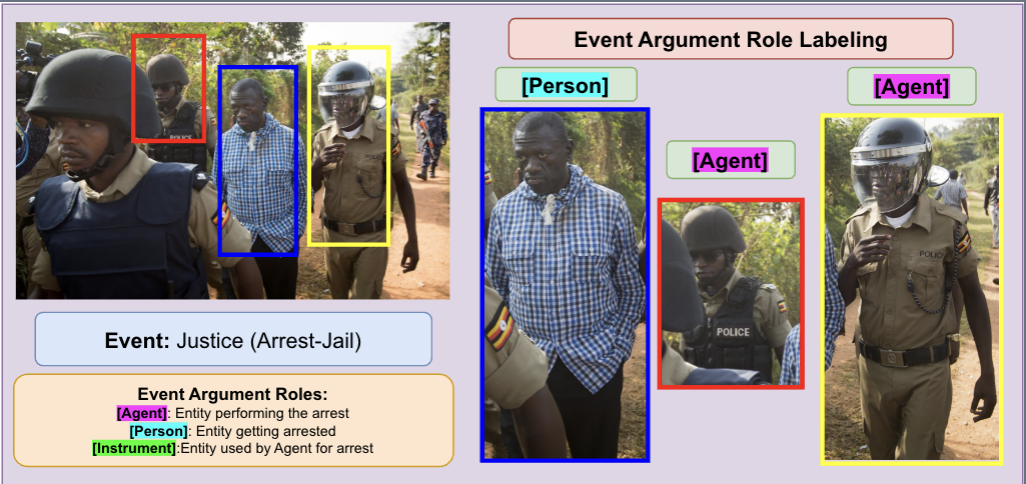
- EARL is the task of identifying the entities involved in an event (e.g., a person, organization, or location) and assigning them role labels (e.g., agent, patient, instrument).
- GenEARL leverages large language models and a novel generative approach to perform EARL without requiring any task-specific training.
Plain English Explanation
GenEARL: A Training-Free Generative Framework for Multimodal Event Argument Role Labeling is a new system that can automatically identify the key participants in an event and describe their roles, using only general language models without any specialized training. This is a valuable capability, as understanding the who, what, and where of events is crucial for many real-world applications like news analysis, policy decision-making, and knowledge base construction.
The key innovation of GenEARL is that it can perform this event argument role labeling task in a "training-free" manner, meaning it doesn't require extensive datasets and fine-tuning like traditional machine learning models. Instead, it leverages the powerful language understanding capabilities of large pre-trained models like BERT and OWL-Modularization, and combines them with a novel generative approach to directly output the role labels for a given event description.
This makes GenEARL much more flexible and accessible than previous EARL systems, which often required large amounts of annotated training data that can be expensive and time-consuming to collect. By avoiding the need for task-specific training, GenEARL can be applied to a wide range of domains and event types, opening up new possibilities for real-world applications of this important technology.
Technical Explanation
GenEARL: A Training-Free Generative Framework for Multimodal Event Argument Role Labeling presents a novel approach to the task of multimodal event argument role labeling (EARL). EARL involves identifying the key entities involved in an event (such as a person, organization, or location) and assigning them appropriate role labels (such as agent, patient, or instrument).
The core innovation of GenEARL is that it can perform EARL in a "training-free" manner, without requiring any task-specific fine-tuning or annotated datasets. This is achieved by leveraging large pre-trained language models like BERT and OWL-Modularization to encode the input event description, and then using a generative model to directly output the corresponding role labels.
The authors demonstrate the effectiveness of this approach through experiments on several EARL benchmarks, showing that GenEARL can achieve performance on par with or exceeding traditional supervised models, while being much more flexible and accessible. This is a significant advancement, as previous EARL systems often required expensive data collection and model training, limiting their real-world applicability.
Critical Analysis
The GenEARL paper presents an innovative and promising approach to the task of multimodal event argument role labeling. By leveraging large pre-trained language models and a novel generative framework, the authors have developed a system that can perform EARL in a training-free manner, without requiring specialized datasets or fine-tuning.
One potential limitation of the approach, as noted by the authors, is that GenEARL currently only supports textual input and does not fully leverage the multimodal nature of many real-world events, which may include images, video, or other modalities. Extending GenEARL to handle these additional data sources could further enhance its performance and real-world applicability.
Additionally, while the paper demonstrates the effectiveness of GenEARL on several benchmark datasets, it would be valuable to see more comprehensive evaluations, including assessment of the model's robustness, generalization capabilities, and potential biases. As with any AI system, it is important to carefully scrutinize its behavior and limitations to ensure it is deployed responsibly.
Overall, the GenEARL framework represents an exciting step forward in the field of event argument role labeling, and the authors' training-free approach has the potential to significantly broaden the accessibility and real-world impact of this technology.
Conclusion
GenEARL: A Training-Free Generative Framework for Multimodal Event Argument Role Labeling introduces a novel approach to the task of identifying and labeling the key participants in an event. By leveraging large pre-trained language models and a generative framework, the GenEARL system can perform this task without requiring any specialized training data or fine-tuning, making it much more flexible and accessible than previous EARL systems.
The ability to automatically extract and understand the "who, what, and where" of events has significant implications for a wide range of real-world applications, from news analysis and policy decision-making to knowledge base construction and question answering. The training-free nature of GenEARL opens up new possibilities for deploying this technology in diverse domains and settings, potentially leading to important advancements in our ability to make sense of the complex, multimodal events that shape our world.
While the current GenEARL model has some limitations, such as its focus on textual input, the core innovation of the paper represents an important step forward in the field of event understanding. As the authors continue to refine and expand their approach, the potential impact of this research could be far-reaching, contributing to our broader efforts to build more intelligent and capable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GenEARL: A Training-Free Generative Framework for Multimodal Event Argument Role Labeling
Hritik Bansal, Po-Nien Kung, P. Jeffrey Brantingham, Kai-Wei Chang, Nanyun Peng
Multimodal event argument role labeling (EARL), a task that assigns a role for each event participant (object) in an image is a complex challenge. It requires reasoning over the entire image, the depicted event, and the interactions between various objects participating in the event. Existing models heavily rely on high-quality event-annotated training data to understand the event semantics and structures, and they fail to generalize to new event types and domains. In this paper, we propose GenEARL, a training-free generative framework that harness the power of the modern generative models to understand event task descriptions given image contexts to perform the EARL task. Specifically, GenEARL comprises two stages of generative prompting with a frozen vision-language model (VLM) and a frozen large language model (LLM). First, a generative VLM learns the semantics of the event argument roles and generates event-centric object descriptions based on the image. Subsequently, a LLM is prompted with the generated object descriptions with a predefined template for EARL (i.e., assign an object with an event argument role). We show that GenEARL outperforms the contrastive pretraining (CLIP) baseline by 9.4% and 14.2% accuracy for zero-shot EARL on the M2E2 and SwiG datasets, respectively. In addition, we outperform CLIP-Event by 22% precision on M2E2 dataset. The framework also allows flexible adaptation and generalization to unseen domains.
Read more4/9/2024

0
Large Language Models for Document-Level Event-Argument Data Augmentation for Challenging Role Types
Joseph Gatto, Parker Seegmiller, Omar Sharif, Sarah M. Preum
Event Argument Extraction (EAE) is an extremely difficult information extraction problem -- with significant limitations in few-shot cross-domain (FSCD) settings. A common solution to FSCD modeling is data augmentation. Unfortunately, existing augmentation methods are not well-suited to a variety of real-world EAE contexts including (i) The need to model long documents (10+ sentences) (ii) The need to model zero and few-shot roles (i.e. event roles with little to no training representation). In this work, we introduce two novel LLM-powered data augmentation frameworks for synthesizing extractive document-level EAE samples using zero in-domain training data. Our highest performing methods provide a 16-pt increase in F1 score on extraction of zero shot role types. To better facilitate analysis of cross-domain EAE, we additionally introduce a new metric, Role-Depth F1 (RDF1), which uses statistical depth to identify roles in the target domain which are semantic outliers with respect to roles observed in the source domain. Our experiments show that LLM-based augmentation can boost RDF1 performance by up to 11 F1 points compared to baseline methods.
Read more6/14/2024

0
MEEL: Multi-Modal Event Evolution Learning
Zhengwei Tao, Zhi Jin, Junqiang Huang, Xiancai Chen, Xiaoying Bai, Haiyan Zhao, Yifan Zhang, Chongyang Tao
Multi-modal Event Reasoning (MMER) endeavors to endow machines with the ability to comprehend intricate event relations across diverse data modalities. MMER is fundamental and underlies a wide broad of applications. Despite extensive instruction fine-tuning, current multi-modal large language models still fall short in such ability. The disparity stems from that existing models are insufficient to capture underlying principles governing event evolution in various scenarios. In this paper, we introduce Multi-Modal Event Evolution Learning (MEEL) to enable the model to grasp the event evolution mechanism, yielding advanced MMER ability. Specifically, we commence with the design of event diversification to gather seed events from a rich spectrum of scenarios. Subsequently, we employ ChatGPT to generate evolving graphs for these seed events. We propose an instruction encapsulation process that formulates the evolving graphs into instruction-tuning data, aligning the comprehension of event reasoning to humans. Finally, we observe that models trained in this way are still struggling to fully comprehend event evolution. In such a case, we propose the guiding discrimination strategy, in which models are trained to discriminate the improper evolution direction. We collect and curate a benchmark M-EV2 for MMER. Extensive experiments on M-EV2 validate the effectiveness of our approach, showcasing competitive performance in open-source multi-modal LLMs.
Read more4/17/2024

0
Enhancing Event Reasoning in Large Language Models through Instruction Fine-Tuning with Semantic Causal Graphs
Mazal Bethany, Emet Bethany, Brandon Wherry, Cho-Yu Chiang, Nishant Vishwamitra, Anthony Rios, Peyman Najafirad
Event detection and text reasoning have become critical applications across various domains. While LLMs have recently demonstrated impressive progress in reasoning abilities, they often struggle with event detection, particularly due to the absence of training methods that consider causal relationships between event triggers and types. To address this challenge, we propose a novel approach for instruction fine-tuning LLMs for event detection. Our method introduces Semantic Causal Graphs (SCGs) to capture both causal relationships and contextual information within text. Building off of SCGs, we propose SCG Instructions for fine-tuning LLMs by focusing on event triggers and their relationships to event types, and employ Low-Rank Adaptation (LoRA) to help preserve the general reasoning abilities of LLMs. Our evaluations demonstrate that training LLMs with SCG Instructions outperforms standard instruction fine-tuning by an average of 35.69% on Event Trigger Classification. Notably, our fine-tuned Mistral 7B model also outperforms GPT-4 on key event detection metrics by an average of 31.01% on Event Trigger Identification, 37.40% on Event Trigger Classification, and 16.43% on Event Classification. We analyze the retention of general capabilities, observing only a minimal average drop of 2.03 points across six benchmarks. This comprehensive study investigates multiple LLMs for the event detection task across various datasets, prompting strategies, and training approaches.
Read more9/4/2024