Explaining Deep Neural Networks by Leveraging Intrinsic Methods

0
🤿
Sign in to get full access
Overview
- Deep neural networks have become widely used, but are often seen as "black boxes" due to their complex internal structure and lack of explanations for their decisions
- This thesis aims to address this issue by contributing to the field of Explainable AI (XAI), focusing on enhancing the interpretability of deep neural networks
- The key contributions include novel techniques for making deep neural networks more interpretable, investigating the inner workings of trained networks, and analyzing the application of explanatory techniques in visual analytics
Plain English Explanation
Deep neural networks are a type of powerful artificial intelligence (AI) model that can learn to perform complex tasks, like recognizing objects in images or understanding natural language. However, these models are often referred to as "black boxes" because it's not always clear how they arrive at their decisions. This can make it challenging for people to trust and understand these AI systems.
This research thesis tries to address this problem by developing new ways to make deep neural networks more interpretable and explainable. The key contributions include:
- Designing deep neural networks that can provide explanations for their own decisions, such as by integrating external memory or using specialized layers that help explain the model's reasoning.
- Investigating the inner workings of trained deep neural networks, looking at the activation patterns of individual neurons to better understand how these models work under the hood.
- Analyzing how techniques for explaining AI systems are being used in visual analytics applications, exploring how well these explanations can actually communicate the reasoning behind the AI's decisions to human users.
By making deep neural networks more interpretable and explainable, the goal is to increase trust and acceptance of these powerful AI technologies as they become more widely used in society. The research aims to pave the way for a future of "human-centric" explainable AI that can be readily understood and engaged with by people.
Technical Explanation
The core of this thesis is focused on enhancing the interpretability of deep neural networks, which are often seen as opaque "black box" models due to their complex internal structures and lack of explanations for their decisions.
One key contribution is the introduction of novel techniques for designing self-explanatory deep neural networks. This includes integrating external memory components into the models to support interpretability, as well as using specialized "prototype" and "constraint-based" layers that can provide more transparency around the network's reasoning. These architectural innovations are explored across a variety of application domains.
The research also delves into investigating the inner workings of trained deep neural networks, looking at the activation patterns of individual neurons to uncover interesting phenomena that may offer insights into how these models function. This "neuron-level" analysis provides a complementary perspective to the high-level, architecture-focused approaches.
Finally, the thesis conducts an analysis of explanatory techniques in visual analytics, exploring the current state of their adoption and the potential for these systems to effectively convey explanations to human users. This assessment of real-world applications helps bridge the gap between technical XAI research and practical deployment.
Overall, this work aims to make significant contributions towards a more "explainable AI" future by developing new methods for enhancing the interpretability of deep neural networks and understanding how these techniques can be applied in holistic AI engineering design.
Critical Analysis
The research presented in this thesis tackles an important challenge in the field of AI - the "black box" nature of deep neural networks and the need for more interpretable and explainable models. The proposed techniques for designing self-explanatory networks and investigating neuron-level phenomena offer promising avenues for increasing the transparency of these powerful AI systems.
However, the paper acknowledges that there are still significant limitations and open research questions in this area. The analysis of visual analytics applications highlights that effectively communicating explanations to human users remains a key challenge, and more work is needed to bridge the gap between technical XAI research and real-world deployment.
Additionally, while the neuron-level analysis provides interesting insights, the paper notes that the relationship between individual neuron activations and high-level model reasoning is not always straightforward. Further research may be needed to better understand the complex internal representations and decision-making processes of deep neural networks.
Overall, this thesis makes valuable contributions to the field of Explainable AI, but there is still much work to be done to realize the vision of AI systems that are truly transparent and trustworthy. Continued innovation, along with careful evaluation of the practical implications and limitations of these techniques, will be crucial going forward.
Conclusion
This thesis tackles the important challenge of enhancing the interpretability and explainability of deep neural networks, which are often seen as opaque "black box" models despite their widespread impact. The key contributions include novel techniques for designing self-explanatory deep neural networks, investigating the inner workings of trained models, and analyzing the application of explanatory methods in visual analytics.
By making deep neural networks more interpretable, the research aims to increase trust and acceptance of these powerful AI technologies as they become more integrated into our daily lives. The work lays important groundwork for a future of "human-centric" explainable AI that can be readily understood and engaged with by people.
While significant progress has been made, the paper acknowledges that there are still limitations and open research questions in this area. Continued innovation and careful evaluation of these techniques in real-world applications will be crucial to realizing the full potential of explainable AI and building a more transparent and trustworthy AI ecosystem.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Explaining Deep Neural Networks by Leveraging Intrinsic Methods
Biagio La Rosa
Despite their impact on the society, deep neural networks are often regarded as black-box models due to their intricate structures and the absence of explanations for their decisions. This opacity poses a significant challenge to AI systems wider adoption and trustworthiness. This thesis addresses this issue by contributing to the field of eXplainable AI, focusing on enhancing the interpretability of deep neural networks. The core contributions lie in introducing novel techniques aimed at making these networks more interpretable by leveraging an analysis of their inner workings. Specifically, the contributions are threefold. Firstly, the thesis introduces designs for self-explanatory deep neural networks, such as the integration of external memory for interpretability purposes and the usage of prototype and constraint-based layers across several domains. Secondly, this research delves into novel investigations on neurons within trained deep neural networks, shedding light on overlooked phenomena related to their activation values. Lastly, the thesis conducts an analysis of the application of explanatory techniques in the field of visual analytics, exploring the maturity of their adoption and the potential of these systems to convey explanations to users effectively.
Read more7/18/2024
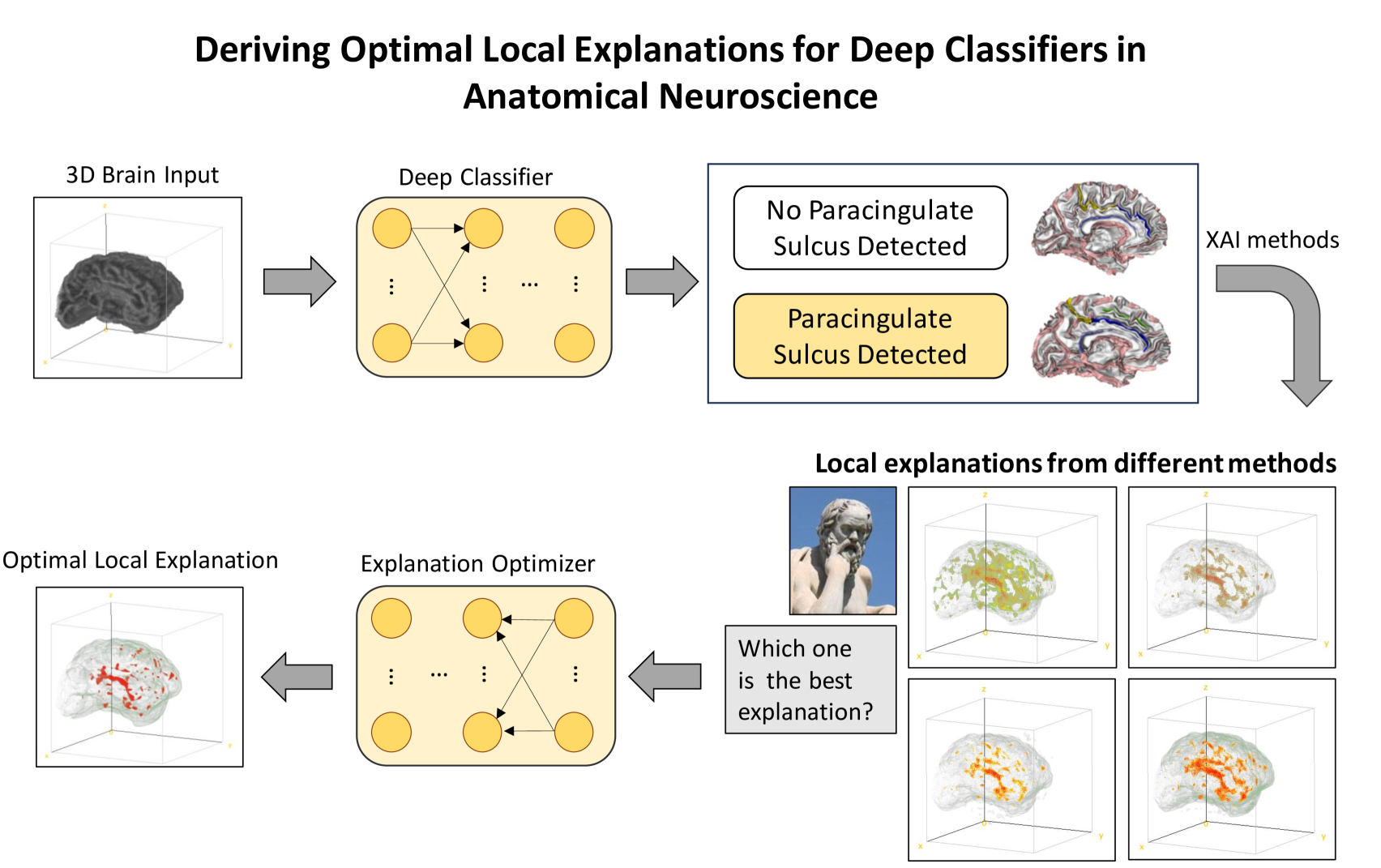
0
Solving the enigma: Deriving optimal explanations of deep networks
Michail Mamalakis, Antonios Mamalakis, Ingrid Agartz, Lynn Egeland M{o}rch-Johnsen, Graham Murray, John Suckling, Pietro Lio
The accelerated progress of artificial intelligence (AI) has popularized deep learning models across domains, yet their inherent opacity poses challenges, notably in critical fields like healthcare, medicine and the geosciences. Explainable AI (XAI) has emerged to shed light on these black box models, helping decipher their decision making process. Nevertheless, different XAI methods yield highly different explanations. This inter-method variability increases uncertainty and lowers trust in deep networks' predictions. In this study, for the first time, we propose a novel framework designed to enhance the explainability of deep networks, by maximizing both the accuracy and the comprehensibility of the explanations. Our framework integrates various explanations from established XAI methods and employs a non-linear explanation optimizer to construct a unique and optimal explanation. Through experiments on multi-class and binary classification tasks in 2D object and 3D neuroscience imaging, we validate the efficacy of our approach. Our explanation optimizer achieved superior faithfulness scores, averaging 155% and 63% higher than the best performing XAI method in the 3D and 2D applications, respectively. Additionally, our approach yielded lower complexity, increasing comprehensibility. Our results suggest that optimal explanations based on specific criteria are derivable and address the issue of inter-method variability in the current XAI literature.
Read more5/17/2024

0
Multilevel Interpretability Of Artificial Neural Networks: Leveraging Framework And Methods From Neuroscience
Zhonghao He, Jascha Achterberg, Katie Collins, Kevin Nejad, Danyal Akarca, Yinzhu Yang, Wes Gurnee, Ilia Sucholutsky, Yuhan Tang, Rebeca Ianov, George Ogden, Chole Li, Kai Sandbrink, Stephen Casper, Anna Ivanova, Grace W. Lindsay
As deep learning systems are scaled up to many billions of parameters, relating their internal structure to external behaviors becomes very challenging. Although daunting, this problem is not new: Neuroscientists and cognitive scientists have accumulated decades of experience analyzing a particularly complex system - the brain. In this work, we argue that interpreting both biological and artificial neural systems requires analyzing those systems at multiple levels of analysis, with different analytic tools for each level. We first lay out a joint grand challenge among scientists who study the brain and who study artificial neural networks: understanding how distributed neural mechanisms give rise to complex cognition and behavior. We then present a series of analytical tools that can be used to analyze biological and artificial neural systems, organizing those tools according to Marr's three levels of analysis: computation/behavior, algorithm/representation, and implementation. Overall, the multilevel interpretability framework provides a principled way to tackle neural system complexity; links structure, computation, and behavior; clarifies assumptions and research priorities at each level; and paves the way toward a unified effort for understanding intelligent systems, may they be biological or artificial.
Read more8/27/2024

0
The future of human-centric eXplainable Artificial Intelligence (XAI) is not post-hoc explanations
Vinitra Swamy, Jibril Frej, Tanja Kaser
Explainable Artificial Intelligence (XAI) plays a crucial role in enabling human understanding and trust in deep learning systems. As models get larger, more ubiquitous, and pervasive in aspects of daily life, explainability is necessary to minimize adverse effects of model mistakes. Unfortunately, current approaches in human-centric XAI (e.g. predictive tasks in healthcare, education, or personalized ads) tend to rely on a single post-hoc explainer, whereas recent work has identified systematic disagreement between post-hoc explainers when applied to the same instances of underlying black-box models. In this paper, we therefore present a call for action to address the limitations of current state-of-the-art explainers. We propose a shift from post-hoc explainability to designing interpretable neural network architectures. We identify five needs of human-centric XAI (real-time, accurate, actionable, human-interpretable, and consistent) and propose two schemes for interpretable-by-design neural network workflows (adaptive routing with InterpretCC and temporal diagnostics with I2MD). We postulate that the future of human-centric XAI is neither in explaining black-boxes nor in reverting to traditional, interpretable models, but in neural networks that are intrinsically interpretable.
Read more5/29/2024