On the Value of Labeled Data and Symbolic Methods for Hidden Neuron Activation Analysis
2404.13567
0
0

Abstract
A major challenge in Explainable AI is in correctly interpreting activations of hidden neurons: accurate interpretations would help answer the question of what a deep learning system internally detects as relevant in the input, demystifying the otherwise black-box nature of deep learning systems. The state of the art indicates that hidden node activations can, in some cases, be interpretable in a way that makes sense to humans, but systematic automated methods that would be able to hypothesize and verify interpretations of hidden neuron activations are underexplored. This is particularly the case for approaches that can both draw explanations from substantial background knowledge, and that are based on inherently explainable (symbolic) methods. In this paper, we introduce a novel model-agnostic post-hoc Explainable AI method demonstrating that it provides meaningful interpretations. Our approach is based on using a Wikipedia-derived concept hierarchy with approximately 2 million classes as background knowledge, and utilizes OWL-reasoning-based Concept Induction for explanation generation. Additionally, we explore and compare the capabilities of off-the-shelf pre-trained multimodal-based explainable methods. Our results indicate that our approach can automatically attach meaningful class expressions as explanations to individual neurons in the dense layer of a Convolutional Neural Network. Evaluation through statistical analysis and degree of concept activation in the hidden layer show that our method provides a competitive edge in both quantitative and qualitative aspects compared to prior work.
Create account to get full access
Overview
- This paper explores the value of labeled data and symbolic methods for analyzing the hidden neuron activations in convolutional neural networks (CNNs).
- The researchers investigate how labeled data and symbolic knowledge can provide insights into the internal workings of CNNs, which are often considered "black boxes."
- The paper presents a framework for interpreting and explaining the concepts learned by hidden neurons in CNN-based models.
Plain English Explanation
The paper discusses ways to better understand how convolutional neural networks (CNNs) work under the hood. CNNs are a type of deep learning model that are very powerful at tasks like image recognition, but they can also be a bit of a "black box" - it's not always clear how they arrive at their decisions.
The researchers explore two approaches that can help shed light on the inner workings of CNNs. The first is using labeled data, which means data that has been manually categorized or annotated. The researchers show how this labeled data can provide insights into what the different neurons in a CNN are "learning" and "detecting" as they process images.
The second approach is using symbolic methods, which involves incorporating structured knowledge (like concepts defined in a knowledge graph) into the analysis of the CNN. This allows the researchers to go beyond just looking at the raw neuron activations and to start understanding the higher-level "concepts" that the CNN has learned.
By combining these two approaches - labeled data and symbolic knowledge - the paper presents a framework for interpreting and explaining the inner workings of CNN-based models in a more transparent and meaningful way. This could be useful for things like understanding explainability in AI, disentangling neural network predictions, and evaluating whether AI systems are truly "explainable".
Technical Explanation
The paper introduces a framework for Concept Activation Vector (CAV) analysis, which uses both labeled data and symbolic knowledge to interpret the hidden neuron activations in a CNN.
The key steps are:
- Labeled Data: The researchers first collect a set of images labeled with various concepts (e.g. "dog", "tree", "car"). They then use these labeled images to identify which neurons in the CNN are most strongly activated by each concept.
- Symbolic Knowledge: The researchers also leverage a knowledge graph that defines relationships between different concepts. This allows them to go beyond just looking at individual neuron activations and to understand how the CNN is representing higher-level conceptual knowledge.
- CAV Analysis: By combining the labeled data and symbolic knowledge, the researchers can perform a Concept Activation Vector (CAV) analysis. This allows them to quantify how strongly each hidden neuron in the CNN is associated with different semantic concepts.
The paper demonstrates the effectiveness of this framework through experiments on several CNN-based models and image classification tasks. The results show that the CAV analysis provides meaningful insights into the internal representations learned by the CNNs, going beyond just looking at their input-output behavior.
Critical Analysis
The paper presents a compelling approach for interpreting the inner workings of CNN-based models, but there are a few caveats and limitations to consider:
- Dependence on Labeled Data: The framework relies heavily on having a comprehensive set of labeled training data. In real-world scenarios, obtaining high-quality labeled data can be challenging and expensive.
- Scope of Symbolic Knowledge: The paper uses a pre-defined knowledge graph to incorporate conceptual knowledge, but the coverage and quality of this knowledge graph may be limited. Expanding the scope of the symbolic knowledge could be an area for future research.
- Generalization to Other Model Types: While the paper focuses on CNNs, it would be interesting to see if the CAV analysis framework could be extended to other types of neural network architectures, such as transformers or generative models.
Overall, the paper makes a strong case for the value of combining labeled data and symbolic methods to better understand and interpret the internal representations of CNN-based models. This work could have important implications for improving the transparency and explainability of AI systems.
Conclusion
This paper presents a novel framework for analyzing the hidden neuron activations in convolutional neural networks (CNNs) by leveraging both labeled data and symbolic knowledge. The key insights are:
- Using labeled data can provide valuable information about the specific concepts that different neurons in a CNN are responsive to.
- Incorporating structured, symbolic knowledge (e.g. via a knowledge graph) can further enhance the interpretability of the CNN's internal representations.
- The Concept Activation Vector (CAV) analysis framework proposed in the paper allows for a more comprehensive and meaningful understanding of how CNNs work under the hood.
This work has important implications for improving the transparency and explainability of AI systems, which is a crucial challenge as these models become more widely deployed. By shedding light on the inner workings of CNNs, the techniques described in this paper could help build greater trust and accountability in AI-powered applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
Error-margin Analysis for Hidden Neuron Activation Labels
Abhilekha Dalal, Rushrukh Rayan, Pascal Hitzler
0
0
Understanding how high-level concepts are represented within artificial neural networks is a fundamental challenge in the field of artificial intelligence. While existing literature in explainable AI emphasizes the importance of labeling neurons with concepts to understand their functioning, they mostly focus on identifying what stimulus activates a neuron in most cases, this corresponds to the notion of recall in information retrieval. We argue that this is only the first-part of a two-part job, it is imperative to also investigate neuron responses to other stimuli, i.e., their precision. We call this the neuron labels error margin.
5/17/2024
Explaining Explainability: Understanding Concept Activation Vectors
Angus Nicolson, Lisa Schut, J. Alison Noble, Yarin Gal
0
0
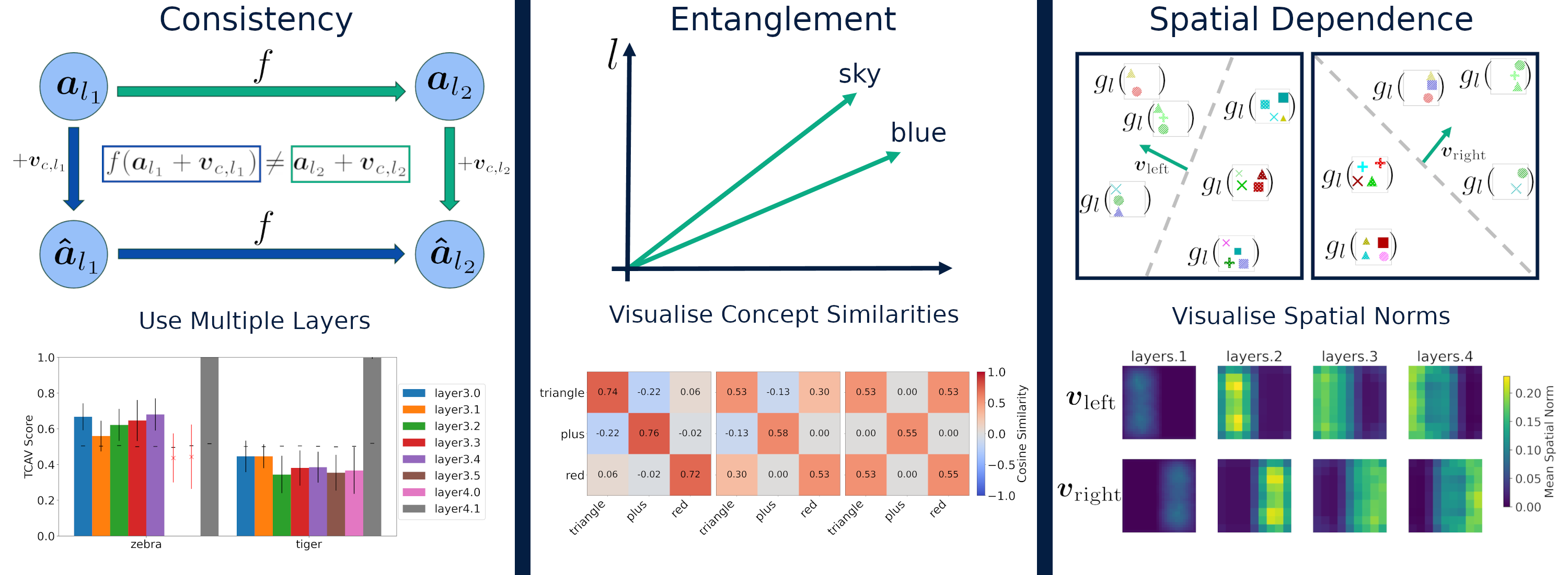
Recent interpretability methods propose using concept-based explanations to translate the internal representations of deep learning models into a language that humans are familiar with: concepts. This requires understanding which concepts are present in the representation space of a neural network. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs. CAVs may be: (1) inconsistent between layers, (2) entangled with different concepts, and (3) spatially dependent. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how they affect the derived explanations, and provide recommendations to minimise their impact. Understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on ImageNet and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.
4/8/2024
From Neural Activations to Concepts: A Survey on Explaining Concepts in Neural Networks
Jae Hee Lee, Sergio Lanza, Stefan Wermter
0
0
In this paper, we review recent approaches for explaining concepts in neural networks. Concepts can act as a natural link between learning and reasoning: once the concepts are identified that a neural learning system uses, one can integrate those concepts with a reasoning system for inference or use a reasoning system to act upon them to improve or enhance the learning system. On the other hand, knowledge can not only be extracted from neural networks but concept knowledge can also be inserted into neural network architectures. Since integrating learning and reasoning is at the core of neuro-symbolic AI, the insights gained from this survey can serve as an important step towards realizing neuro-symbolic AI based on explainable concepts.
5/6/2024

On GNN explanability with activation rules
Luca Veyrin-Forrer, Ataollah Kamal, Stefan Duffner, Marc Plantevit, C'eline Robardet
0
0
GNNs are powerful models based on node representation learning that perform particularly well in many machine learning problems related to graphs. The major obstacle to the deployment of GNNs is mostly a problem of societal acceptability and trustworthiness, properties which require making explicit the internal functioning of such models. Here, we propose to mine activation rules in the hidden layers to understand how the GNNs perceive the world. The problem is not to discover activation rules that are individually highly discriminating for an output of the model. Instead, the challenge is to provide a small set of rules that cover all input graphs. To this end, we introduce the subjective activation pattern domain. We define an effective and principled algorithm to enumerate activations rules in each hidden layer. The proposed approach for quantifying the interest of these rules is rooted in information theory and is able to account for background knowledge on the input graph data. The activation rules can then be redescribed thanks to pattern languages involving interpretable features. We show that the activation rules provide insights on the characteristics used by the GNN to classify the graphs. Especially, this allows to identify the hidden features built by the GNN through its different layers. Also, these rules can subsequently be used for explaining GNN decisions. Experiments on both synthetic and real-life datasets show highly competitive performance, with up to 200% improvement in fidelity on explaining graph classification over the SOTA methods.
6/18/2024