Mitigating Open-Vocabulary Caption Hallucinations

0

Sign in to get full access
Overview
- This paper introduces MOCHa, a multi-objective reinforcement learning framework for mitigating caption hallucinations in image captioning models.
- Hallucinations refer to the generation of irrelevant or incorrect text in image captions, which is a common issue with these models.
- MOCHa aims to address this problem by training the captioning model to optimize for both caption quality and hallucination reduction.
Plain English Explanation
The paper proposes a new approach called MOCHa (Multi-Objective Reinforcement mitigating Caption Hallucinations) to improve image captioning models. These models are used to automatically generate text descriptions of images, but they can sometimes produce irrelevant or incorrect information, known as "hallucinations."
The key idea behind MOCHa is to train the captioning model to have two goals: 1) generate high-quality, accurate captions, and 2) avoid generating hallucinations. This is achieved through a multi-objective reinforcement learning approach, where the model is rewarded for both caption quality and hallucination reduction during training.
By optimizing for these two objectives simultaneously, the model learns to balance generating informative captions while also avoiding the inclusion of irrelevant or made-up details. This helps to produce more reliable and trustworthy image captions, which is important for applications like visual question answering, open-world object detection, and medical imaging.
Technical Explanation
The MOCHa framework is built on top of a standard image captioning model, which takes an input image and generates a corresponding text description. To address the hallucination issue, MOCHa introduces two additional components:
-
Hallucination Detector: This is a module that learns to identify hallucinated text in the generated captions. It provides a signal to the captioning model about which parts of the caption are likely to be hallucinations.
-
Multi-Objective Reward: During training, the captioning model is optimized using a reward function that combines two objectives: 1) maximizing the quality of the generated captions, and 2) minimizing the amount of hallucinated text. This encourages the model to balance these two goals.
The authors evaluate MOCHa on several benchmark image captioning datasets, including COCO and Conceptual Captions. The results show that MOCHa is able to significantly reduce the amount of hallucinated text in the generated captions, while maintaining high caption quality compared to baseline models.
Critical Analysis
The MOCHa framework represents a promising approach to mitigating hallucinations in image captioning models. By jointly optimizing for caption quality and hallucination reduction, it addresses a key limitation of many existing captioning models, which can sometimes generate irrelevant or fabricated information.
However, the paper does not provide a detailed analysis of the types of hallucinations that MOCHa is able to address. It would be valuable to understand the specific failure modes that the model can mitigate, as well as any remaining limitations or challenges. Additionally, the authors could explore the transferability of the MOCHa approach to other language generation tasks, such as text summarization or question answering, where hallucination is also a significant issue.
Conclusion
The MOCHa framework introduced in this paper represents an important step forward in addressing the problem of hallucinations in image captioning models. By jointly optimizing for caption quality and hallucination reduction, it produces more reliable and trustworthy image descriptions, with potential applications in a wide range of domains. The multi-objective reinforcement learning approach provides a general framework that could be adapted and extended to tackle hallucination challenges in other language generation tasks as well.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mitigating Open-Vocabulary Caption Hallucinations
Assaf Ben-Kish, Moran Yanuka, Morris Alper, Raja Giryes, Hadar Averbuch-Elor
While recent years have seen rapid progress in image-conditioned text generation, image captioning still suffers from the fundamental issue of hallucinations, namely, the generation of spurious details that cannot be inferred from the given image. Existing methods largely use closed-vocabulary object lists to mitigate or evaluate hallucinations in image captioning, ignoring the long-tailed nature of hallucinations that occur in practice. To this end, we propose a framework for addressing hallucinations in image captioning in the open-vocabulary setting. Our framework includes a new benchmark, OpenCHAIR, that leverages generative foundation models to evaluate open-vocabulary object hallucinations for image captioning, surpassing the popular and similarly-sized CHAIR benchmark in both diversity and accuracy. Furthermore, to mitigate open-vocabulary hallucinations without using a closed object list, we propose MOCHa, an approach harnessing advancements in reinforcement learning. Our multi-objective reward function explicitly targets the trade-off between fidelity and adequacy in generations without requiring any strong supervision. MOCHa improves a large variety of image captioning models, as captured by our OpenCHAIR benchmark and other existing metrics. We will release our code and models.
Read more4/22/2024

0
ALOHa: A New Measure for Hallucination in Captioning Models
Suzanne Petryk, David M. Chan, Anish Kachinthaya, Haodi Zou, John Canny, Joseph E. Gonzalez, Trevor Darrell
Despite recent advances in multimodal pre-training for visual description, state-of-the-art models still produce captions containing errors, such as hallucinating objects not present in a scene. The existing prominent metric for object hallucination, CHAIR, is limited to a fixed set of MS COCO objects and synonyms. In this work, we propose a modernized open-vocabulary metric, ALOHa, which leverages large language models (LLMs) to measure object hallucinations. Specifically, we use an LLM to extract groundable objects from a candidate caption, measure their semantic similarity to reference objects from captions and object detections, and use Hungarian matching to produce a final hallucination score. We show that ALOHa correctly identifies 13.6% more hallucinated objects than CHAIR on HAT, a new gold-standard subset of MS COCO Captions annotated for hallucinations, and 30.8% more on nocaps, where objects extend beyond MS COCO categories. Our code is available at https://davidmchan.github.io/aloha/.
Read more4/4/2024

0
A Unified Hallucination Mitigation Framework for Large Vision-Language Models
Yue Chang, Liqiang Jing, Xiaopeng Zhang, Yue Zhang
Hallucination is a common problem for Large Vision-Language Models (LVLMs) with long generations which is difficult to eradicate. The generation with hallucinations is partially inconsistent with the image content. To mitigate hallucination, current studies either focus on the process of model inference or the results of model generation, but the solutions they design sometimes do not deal appropriately with various types of queries and the hallucinations of the generations about these queries. To accurately deal with various hallucinations, we present a unified framework, Dentist, for hallucination mitigation. The core step is to first classify the queries, then perform different processes of hallucination mitigation based on the classification result, just like a dentist first observes the teeth and then makes a plan. In a simple deployment, Dentist can classify queries as perception or reasoning and easily mitigate potential hallucinations in answers which has been demonstrated in our experiments. On MMbench, we achieve a 13.44%/10.2%/15.8% improvement in accuracy on Image Quality, a Coarse Perception visual question answering (VQA) task, over the baseline InstructBLIP/LLaVA/VisualGLM.
Read more9/26/2024
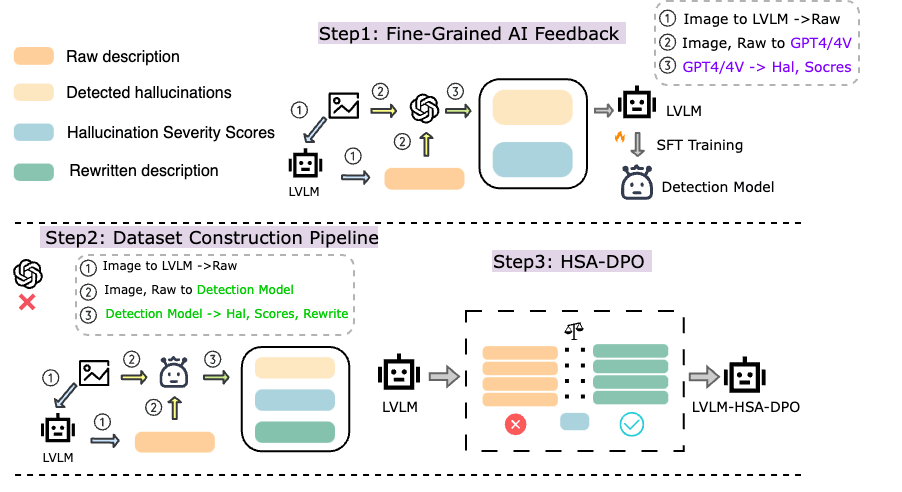
0
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
Read more4/23/2024