Exposing Image Classifier Shortcuts with Counterfactual Frequency (CoF) Tables

0

Sign in to get full access
Overview
- This paper introduces a technique called Counterfactual Frequency (CoF) tables to expose the shortcuts used by image classifiers.
- CoF tables aggregate local explanations to identify features that are highly predictive but not actually relevant for the classification task.
- The authors demonstrate how CoF tables can uncover biases and flaws in image classifiers across multiple datasets and model architectures.
Plain English Explanation
Machine learning models like image classifiers can sometimes rely on "shortcuts" - features in the data that are highly correlated with the target classes, but not actually relevant for the task. This paper introduces a method called Counterfactual Frequency (CoF) tables to expose these shortcuts in image classifiers.
The key idea is to use local explanations - which explain the reasoning behind individual predictions - and aggregate them to identify features that are overly predictive but not truly meaningful. This process is similar to how one might generate counterfactual explanations to better understand an AI system's decision-making.
By surfacing these shortcuts, the CoF tables can help uncover biases and flaws in image classifiers across a variety of datasets and model architectures. This type of analysis can be valuable for improving the robustness and reliability of AI systems used in high-stakes applications.
Technical Explanation
The authors propose a method called Counterfactual Frequency (CoF) tables to expose the shortcuts used by image classifiers. CoF tables aggregate local explanations - which explain the reasoning behind individual predictions - to identify features that are highly predictive but not actually relevant for the classification task.
Specifically, the authors first generate local explanations for each image using a technique like LIME or Shapley values. They then compute the frequency with which each feature appears in the top-k most important features across all local explanations. Features that are highly predictive but not truly meaningful will have a high counterfactual frequency - meaning they appear often in the local explanations despite not being relevant to the task.
The authors demonstrate the effectiveness of CoF tables across multiple datasets (CIFAR-10, CelebA, and ImageNet) and model architectures (VGG, ResNet, and EfficientNet). They show how CoF tables can uncover biases and flaws in the classifiers, such as relying on spurious correlations like background textures or unintended object associations.
Critical Analysis
The paper provides a compelling approach for exposing the shortcuts used by image classifiers. The authors demonstrate the effectiveness of CoF tables across a variety of datasets and model architectures, showcasing its broad applicability.
One potential limitation of the method is that it relies on the quality of the local explanations generated. If the local explanation techniques themselves have biases or flaws, this could impact the accuracy of the CoF tables. Further research could explore ways to make the local explanation process more robust.
Additionally, while the paper focuses on image classifiers, the CoF table approach could potentially be extended to other types of machine learning models. Exploring the applicability of this technique to other domains could be an interesting area for future work.
Overall, the paper presents a valuable tool for understanding and improving the reliability of image classifiers, with broader implications for the responsible development of AI systems.
Conclusion
This paper introduces Counterfactual Frequency (CoF) tables, a technique for exposing the shortcuts used by image classifiers. By aggregating local explanations, CoF tables can identify features that are highly predictive but not actually relevant for the classification task, helping to uncover biases and flaws in the models.
The authors demonstrate the effectiveness of CoF tables across multiple datasets and model architectures, showcasing their broad applicability. This type of analysis can be valuable for improving the robustness and reliability of AI systems, especially in high-stakes applications where we want to ensure the models are basing their decisions on truly relevant features.
Overall, the paper presents a promising approach for enhancing the transparency and accountability of image classifiers, with potential implications for the responsible development of AI systems more broadly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exposing Image Classifier Shortcuts with Counterfactual Frequency (CoF) Tables
James Hinns, David Martens
The rise of deep learning in image classification has brought unprecedented accuracy but also highlighted a key issue: the use of 'shortcuts' by models. Such shortcuts are easy-to-learn patterns from the training data that fail to generalise to new data. Examples include the use of a copyright watermark to recognise horses, snowy background to recognise huskies, or ink markings to detect malignant skin lesions. The explainable AI (XAI) community has suggested using instance-level explanations to detect shortcuts without external data, but this requires the examination of many explanations to confirm the presence of such shortcuts, making it a labour-intensive process. To address these challenges, we introduce Counterfactual Frequency (CoF) tables, a novel approach that aggregates instance-based explanations into global insights, and exposes shortcuts. The aggregation implies the need for some semantic concepts to be used in the explanations, which we solve by labelling the segments of an image. We demonstrate the utility of CoF tables across several datasets, revealing the shortcuts learned from them.
Read more5/27/2024

0
Fast Diffusion-Based Counterfactuals for Shortcut Removal and Generation
Nina Weng, Paraskevas Pegios, Eike Petersen, Aasa Feragen, Siavash Bigdeli
Shortcut learning is when a model -- e.g. a cardiac disease classifier -- exploits correlations between the target label and a spurious shortcut feature, e.g. a pacemaker, to predict the target label based on the shortcut rather than real discriminative features. This is common in medical imaging, where treatment and clinical annotations correlate with disease labels, making them easy shortcuts to predict disease. We propose a novel detection and quantification of the impact of potential shortcut features via a fast diffusion-based counterfactual image generation that can synthetically remove or add shortcuts. Via a novel inpainting-based modification we spatially limit the changes made with no extra inference step, encouraging the removal of spatially constrained shortcut features while ensuring that the shortcut-free counterfactuals preserve their remaining image features to a high degree. Using these, we assess how shortcut features influence model predictions. This is enabled by our second contribution: An efficient diffusion-based counterfactual explanation method with significant inference speed-up at comparable image quality as state-of-the-art. We confirm this on two large chest X-ray datasets, a skin lesion dataset, and CelebA. Our code is publicly available at fastdime.compute.dtu.dk.
Read more7/18/2024
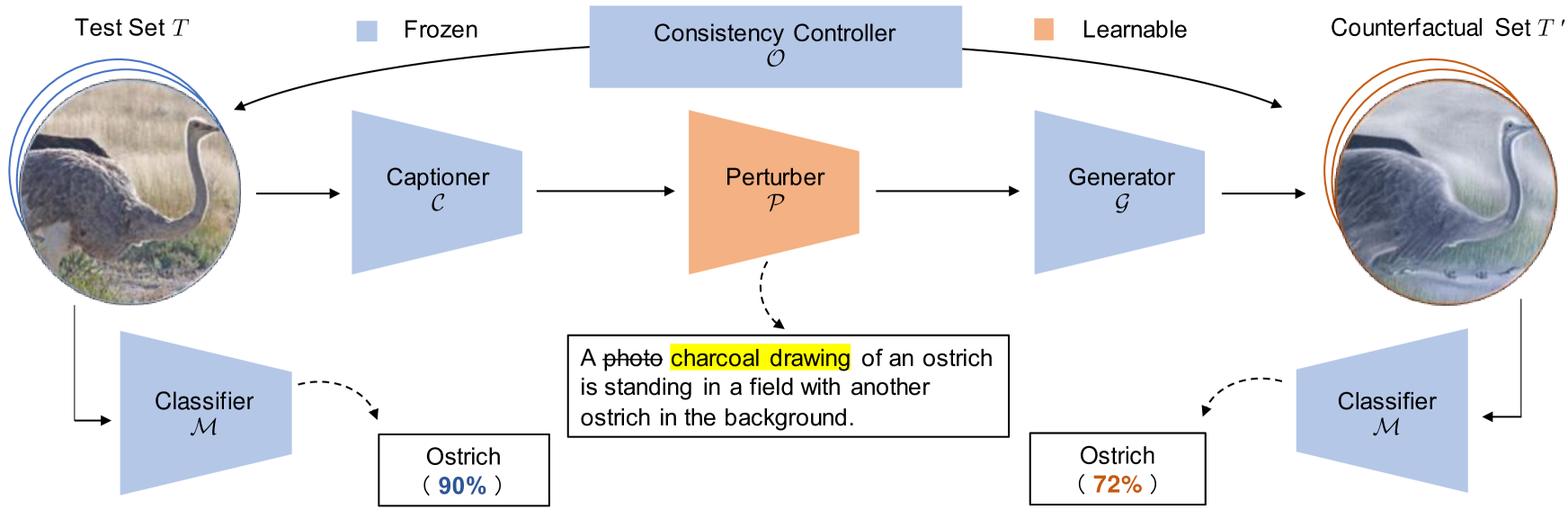
0
Reinforcing Pre-trained Models Using Counterfactual Images
Xiang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
This paper proposes a novel framework to reinforce classification models using language-guided generated counterfactual images. Deep learning classification models are often trained using datasets that mirror real-world scenarios. In this training process, because learning is based solely on correlations with labels, there is a risk that models may learn spurious relationships, such as an overreliance on features not central to the subject, like background elements in images. However, due to the black-box nature of the decision-making process in deep learning models, identifying and addressing these vulnerabilities has been particularly challenging. We introduce a novel framework for reinforcing the classification models, which consists of a two-stage process. First, we identify model weaknesses by testing the model using the counterfactual image dataset, which is generated by perturbed image captions. Subsequently, we employ the counterfactual images as an augmented dataset to fine-tune and reinforce the classification model. Through extensive experiments on several classification models across various datasets, we revealed that fine-tuning with a small set of counterfactual images effectively strengthens the model.
Read more6/21/2024
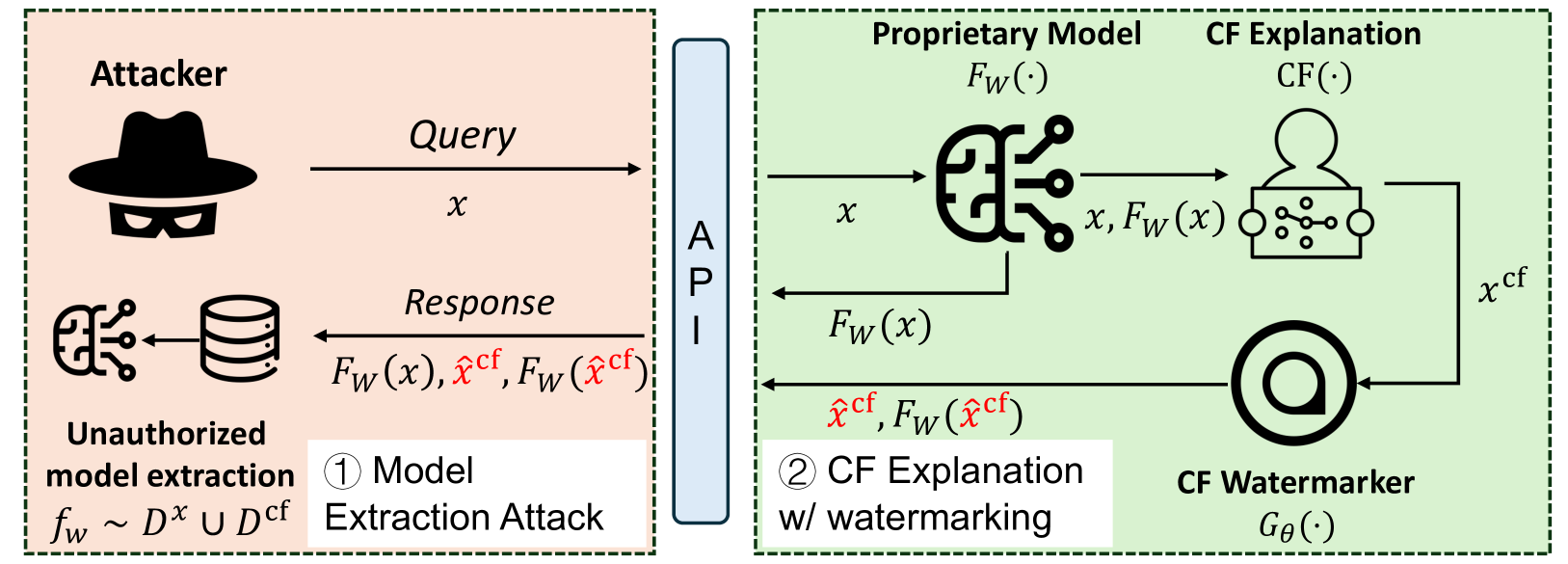
0
Watermarking Counterfactual Explanations
Hangzhi Guo, Amulya Yadav
The field of Explainable Artificial Intelligence (XAI) focuses on techniques for providing explanations to end-users about the decision-making processes that underlie modern-day machine learning (ML) models. Within the vast universe of XAI techniques, counterfactual (CF) explanations are often preferred by end-users as they help explain the predictions of ML models by providing an easy-to-understand & actionable recourse (or contrastive) case to individual end-users who are adversely impacted by predicted outcomes. However, recent studies have shown significant security concerns with using CF explanations in real-world applications; in particular, malicious adversaries can exploit CF explanations to perform query-efficient model extraction attacks on proprietary ML models. In this paper, we propose a model-agnostic watermarking framework (for adding watermarks to CF explanations) that can be leveraged to detect unauthorized model extraction attacks (which rely on the watermarked CF explanations). Our novel framework solves a bi-level optimization problem to embed an indistinguishable watermark into the generated CF explanation such that any future model extraction attacks that rely on these watermarked CF explanations can be detected using a null hypothesis significance testing (NHST) scheme, while ensuring that these embedded watermarks do not compromise the quality of the generated CF explanations. We evaluate this framework's performance across a diverse set of real-world datasets, CF explanation methods, and model extraction techniques, and show that our watermarking detection system can be used to accurately identify extracted ML models that are trained using the watermarked CF explanations. Our work paves the way for the secure adoption of CF explanations in real-world applications.
Read more5/30/2024