Extraction of Research Objectives, Machine Learning Model Names, and Dataset Names from Academic Papers and Analysis of Their Interrelationships Using LLM and Network Analysis

0
Sign in to get full access
Overview
- Extracts research objectives, machine learning model names, and dataset names from academic papers
- Analyzes the interrelationships between these elements using large language models (LLMs) and network analysis
- Aims to provide insights into the connections between research goals, models, and datasets in the literature
Plain English Explanation
This paper presents a method for extracting key information from academic research papers, including the research objectives, the names of machine learning models used, and the datasets analyzed. The researchers then use large language models and network analysis to explore the relationships between these different elements.
The goal is to gain a better understanding of how researchers are approaching various problems, what models and datasets they are using, and how these different components are connected. By analyzing these connections, the researchers hope to uncover insights that could inform future research directions and collaborations.
For example, the analysis might reveal that certain machine learning models are commonly used to address particular research objectives, or that certain datasets are particularly well-suited for certain types of problems. This information could help researchers identify relevant prior work and find opportunities for synergies between different research efforts.
Technical Explanation
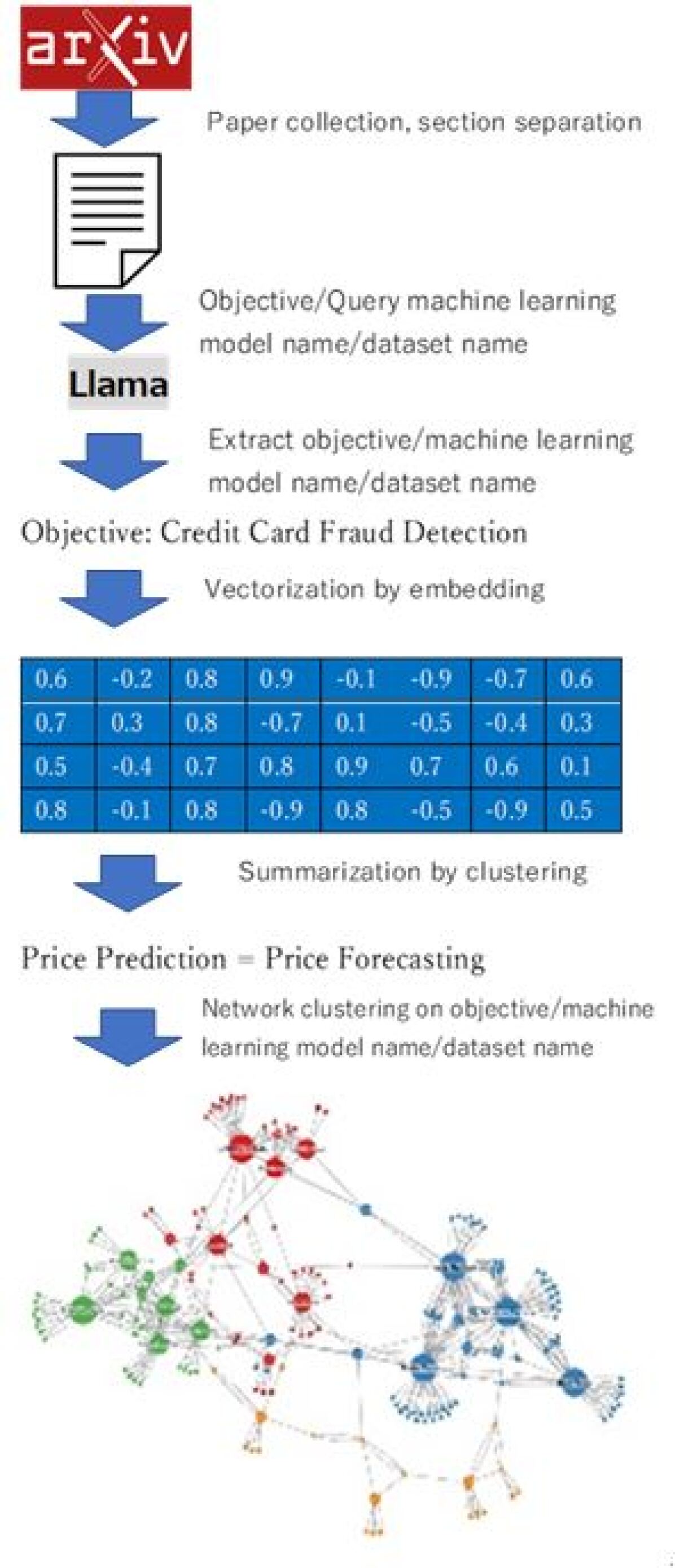
The researchers develop a pipeline that first extracts research objectives, machine learning model names, and dataset names from the text of academic papers using a large language model (LLM) trained for named entity recognition and relation extraction. They then use network analysis techniques to explore the interrelationships between these elements, identifying common patterns and connections.
The extraction process involves fine-tuning a pre-trained LLM on a corpus of manually annotated papers to enable the model to accurately identify the relevant entities and relationships. The network analysis component builds graphs that represent the co-occurrences and connections between the extracted elements, allowing the researchers to identify clusters, hubs, and other structural features that provide insights into the underlying patterns in the literature.
Critical Analysis
The researchers acknowledge several limitations of their approach, including the potential for errors or biases in the entity extraction process, the challenge of handling ambiguous or context-dependent relationships, and the fact that their analysis is restricted to the specific set of papers included in the study.
Additionally, the researchers note that their approach may not capture the full complexity of the relationships between research goals, models, and datasets, and that further research may be needed to develop more sophisticated analytical techniques and to incorporate additional contextual information into the analysis.
Conclusion
This paper presents a novel approach for extracting and analyzing key information from academic literature, with the goal of gaining insights into the connections between research objectives, machine learning models, and datasets. The findings could inform future research directions and foster collaboration within the scientific community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Extraction of Research Objectives, Machine Learning Model Names, and Dataset Names from Academic Papers and Analysis of Their Interrelationships Using LLM and Network Analysis
S. Nishio, H. Nonaka, N. Tsuchiya, A. Migita, Y. Banno, T. Hayashi, H. Sakaji, T. Sakumoto, K. Watabe
Machine learning is widely utilized across various industries. Identifying the appropriate machine learning models and datasets for specific tasks is crucial for the effective industrial application of machine learning. However, this requires expertise in both machine learning and the relevant domain, leading to a high learning cost. Therefore, research focused on extracting combinations of tasks, machine learning models, and datasets from academic papers is critically important, as it can facilitate the automatic recommendation of suitable methods. Conventional information extraction methods from academic papers have been limited to identifying machine learning models and other entities as named entities. To address this issue, this study proposes a methodology extracting tasks, machine learning methods, and dataset names from scientific papers and analyzing the relationships between these information by using LLM, embedding model, and network clustering. The proposed method's expression extraction performance, when using Llama3, achieves an F-score exceeding 0.8 across various categories, confirming its practical utility. Benchmarking results on financial domain papers have demonstrated the effectiveness of this method, providing insights into the use of the latest datasets, including those related to ESG (Environmental, Social, and Governance) data.
Read more8/23/2024

0
Exploring the Latest LLMs for Leaderboard Extraction
Salomon Kabongo, Jennifer D'Souza, Soren Auer
The rapid advancements in Large Language Models (LLMs) have opened new avenues for automating complex tasks in AI research. This paper investigates the efficacy of different LLMs-Mistral 7B, Llama-2, GPT-4-Turbo and GPT-4.o in extracting leaderboard information from empirical AI research articles. We explore three types of contextual inputs to the models: DocTAET (Document Title, Abstract, Experimental Setup, and Tabular Information), DocREC (Results, Experiments, and Conclusions), and DocFULL (entire document). Our comprehensive study evaluates the performance of these models in generating (Task, Dataset, Metric, Score) quadruples from research papers. The findings reveal significant insights into the strengths and limitations of each model and context type, providing valuable guidance for future AI research automation efforts.
Read more7/10/2024
0
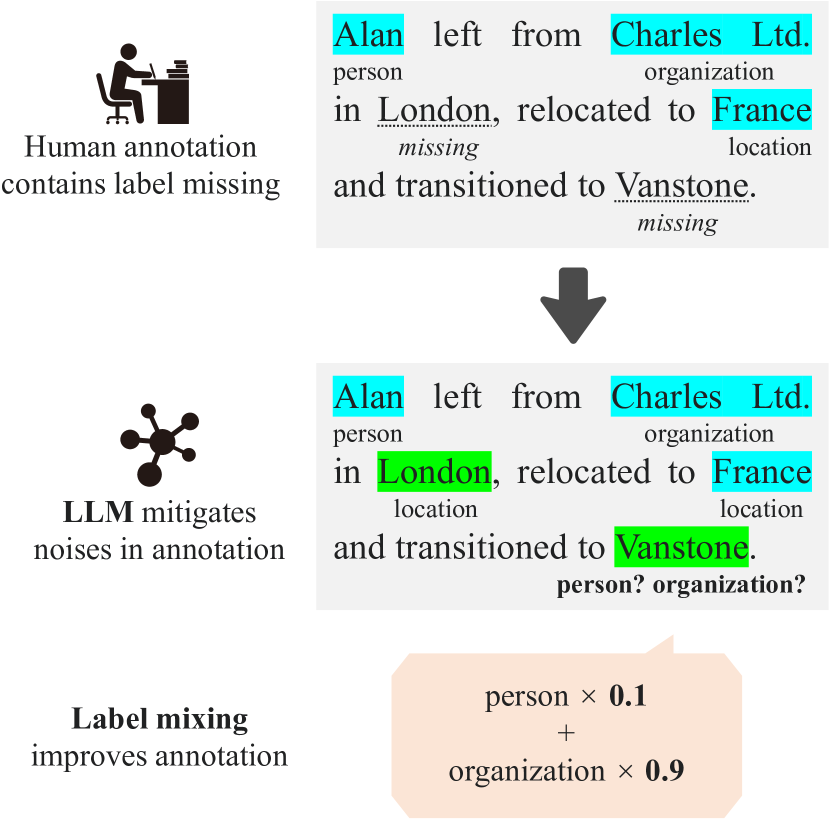
Augmenting NER Datasets with LLMs: Towards Automated and Refined Annotation
Yuji Naraki, Ryosuke Yamaki, Yoshikazu Ikeda, Takafumi Horie, Hiroki Naganuma
In the field of Natural Language Processing (NLP), Named Entity Recognition (NER) is recognized as a critical technology, employed across a wide array of applications. Traditional methodologies for annotating datasets for NER models are challenged by high costs and variations in dataset quality. This research introduces a novel hybrid annotation approach that synergizes human effort with the capabilities of Large Language Models (LLMs). This approach not only aims to ameliorate the noise inherent in manual annotations, such as omissions, thereby enhancing the performance of NER models, but also achieves this in a cost-effective manner. Additionally, by employing a label mixing strategy, it addresses the issue of class imbalance encountered in LLM-based annotations. Through an analysis across multiple datasets, this method has been consistently shown to provide superior performance compared to traditional annotation methods, even under constrained budget conditions. This study illuminates the potential of leveraging LLMs to improve dataset quality, introduces a novel technique to mitigate class imbalances, and demonstrates the feasibility of achieving high-performance NER in a cost-effective way.
Read more4/3/2024
0
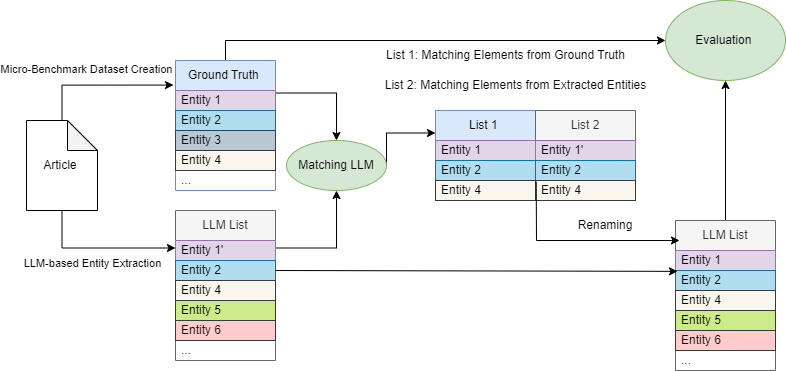
New!Entity Extraction from High-Level Corruption Schemes via Large Language Models
Panagiotis Koletsis, Panagiotis-Konstantinos Gemos, Christos Chronis, Iraklis Varlamis, Vasilis Efthymiou, Georgios Th. Papadopoulos
The rise of financial crime that has been observed in recent years has created an increasing concern around the topic and many people, organizations and governments are more and more frequently trying to combat it. Despite the increase of interest in this area, there is a lack of specialized datasets that can be used to train and evaluate works that try to tackle those problems. This article proposes a new micro-benchmark dataset for algorithms and models that identify individuals and organizations, and their multiple writings, in news articles, and presents an approach that assists in its creation. Experimental efforts are also reported, using this dataset, to identify individuals and organizations in financial-crime-related articles using various low-billion parameter Large Language Models (LLMs). For these experiments, standard metrics (Accuracy, Precision, Recall, F1 Score) are reported and various prompt variants comprising the best practices of prompt engineering are tested. In addition, to address the problem of ambiguous entity mentions, a simple, yet effective LLM-based disambiguation method is proposed, ensuring that the evaluation aligns with reality. Finally, the proposed approach is compared against a widely used state-of-the-art open-source baseline, showing the superiority of the proposed method.
Read more9/24/2024