Spectral Mapping of Singing Voices: U-Net-Assisted Vocal Segmentation

0

Sign in to get full access
Overview
- This paper presents a novel approach for segmenting singing voices in audio recordings using a U-Net-based deep learning model.
- The goal is to accurately identify the regions of audio containing vocal performance, which is an important step for various music processing and analysis tasks.
- The proposed method outperforms traditional signal processing techniques and demonstrates the effectiveness of deep learning for this problem.
Plain English Explanation
Singing is an important part of many types of music, from pop songs to classical compositions. But when you have an audio recording with both singing and other sounds like instruments, it can be tricky to isolate just the vocal part. This paper introduces a new method using a deep learning model called U-Net to automatically detect and separate the singing voice from the rest of the audio.
The key idea is that the U-Net architecture, which is commonly used for image segmentation, can also be effective for segmenting the vocal regions in an audio spectrogram (a visual representation of the audio's frequency content over time). By training the U-Net model on examples of vocal and non-vocal audio, it can learn to accurately identify where the singing is happening, even in complex musical recordings.
This vocal segmentation technique could be useful for a variety of music applications, like isolating the lead vocal for remixing or analyzing a singer's performance. It outperforms traditional signal processing methods that rely on handcrafted features, demonstrating the power of deep learning to automatically learn the relevant patterns in the data.
Technical Explanation
The paper proposes a U-Net-based model for the task of singing voice segmentation in audio recordings. U-Net is a popular convolutional neural network architecture originally developed for image segmentation, but the authors show it can be adapted effectively for audio spectrograms as well.
The model takes a spectrogram of the input audio as its input and outputs a segmentation mask indicating which time-frequency bins correspond to the singing voice. This is trained on a dataset of vocal and non-vocal audio examples, allowing the network to learn the distinctive spectral patterns of the singing voice.
The authors experiment with different data augmentation techniques and loss functions to improve the model's performance. They also compare the U-Net approach to traditional signal processing baselines and show significant improvements in both frame-level and segment-level vocal detection accuracy.
Critical Analysis
The paper provides a compelling demonstration of how deep learning can advance the state-of-the-art in audio processing tasks like vocal segmentation. By adapting the U-Net architecture, the authors show it is possible to learn effective features directly from spectrograms without relying on handcrafted signal processing techniques.
That said, the dataset used for training and evaluation is relatively small, so further research would be needed to assess how well the approach generalizes to more diverse musical genres and recording conditions. There may also be room for improvement by incorporating additional musical knowledge or multimodal information beyond just the audio spectrogram.
Additionally, the paper does not provide much insight into the internal workings of the U-Net model or the specific acoustic cues it uses to detect the vocals. A more interpretable model architecture or analysis could yield interesting musicological insights.
Overall, this work represents a promising step forward in using deep learning for audio signal processing, and the authors have made their code publicly available to encourage further research in this direction.
Conclusion
This paper demonstrates an effective deep learning approach for the problem of singing voice segmentation in audio recordings. By adapting the U-Net architecture to operate on spectrograms, the authors develop a model that can accurately identify the regions of audio containing vocal performance, outperforming traditional signal processing techniques.
This technology could enable a variety of useful applications in music production, analysis, and understanding. While further research is needed to expand the capabilities of this approach, this work represents an important step forward in leveraging the power of deep learning for audio signal processing tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Spectral Mapping of Singing Voices: U-Net-Assisted Vocal Segmentation
Adam Sorrenti
Separating vocal elements from musical tracks is a longstanding challenge in audio signal processing. This study tackles the distinct separation of vocal components from musical spectrograms. We employ the Short Time Fourier Transform (STFT) to extract audio waves into detailed frequency-time spectrograms, utilizing the benchmark MUSDB18 dataset for music separation. Subsequently, we implement a UNet neural network to segment the spectrogram image, aiming to delineate and extract singing voice components accurately. We achieved noteworthy results in audio source separation using of our U-Net-based models. The combination of frequency-axis normalization with Min/Max scaling and the Mean Absolute Error (MAE) loss function achieved the highest Source-to-Distortion Ratio (SDR) of 7.1 dB, indicating a high level of accuracy in preserving the quality of the original signal during separation. This setup also recorded impressive Source-to-Interference Ratio (SIR) and Source-to-Artifact Ratio (SAR) scores of 25.2 dB and 7.2 dB, respectively. These values significantly outperformed other configurations, particularly those using Quantile-based normalization or a Mean Squared Error (MSE) loss function. Our source code, model weights, and demo material can be found at the project's GitHub repository: https://github.com/mbrotos/SoundSeg
Read more5/31/2024
🐍
0
Adversarial Multi-Task Learning for Disentangling Timbre and Pitch in Singing Voice Synthesis
Tae-Woo Kim, Min-Su Kang, Gyeong-Hoon Lee
Recently, deep learning-based generative models have been introduced to generate singing voices. One approach is to predict the parametric vocoder features consisting of explicit speech parameters. This approach has the advantage that the meaning of each feature is explicitly distinguished. Another approach is to predict mel-spectrograms for a neural vocoder. However, parametric vocoders have limitations of voice quality and the mel-spectrogram features are difficult to model because the timbre and pitch information are entangled. In this study, we propose a singing voice synthesis model with multi-task learning to use both approaches -- acoustic features for a parametric vocoder and mel-spectrograms for a neural vocoder. By using the parametric vocoder features as auxiliary features, the proposed model can efficiently disentangle and control the timbre and pitch components of the mel-spectrogram. Moreover, a generative adversarial network framework is applied to improve the quality of singing voices in a multi-singer model. Experimental results demonstrate that our proposed model can generate more natural singing voices than the single-task models, while performing better than the conventional parametric vocoder-based model.
Read more6/14/2024
🛸
0
Singer separation for karaoke content generation
Hsuan-Yu Lin, Xuanjun Chen, Jyh-Shing Roger Jang
Due to the rapid development of deep learning, we can now successfully separate singing voice from mono audio music. However, this separation can only extract human voices from other musical instruments, which is undesirable for karaoke content generation applications that only require the separation of lead singers. For this karaoke application, we need to separate the music containing male and female duets into two vocals, or extract a single lead vocal from the music containing vocal harmony. For this reason, we propose in this article to use a singer separation system, which generates karaoke content for one or two separated lead singers. In particular, we introduced three models for the singer separation task and designed an automatic model selection scheme to distinguish how many lead singers are in the song. We also collected a large enough data set, MIR-SingerSeparation, which has been publicly released to advance the frontier of this research. Our singer separation is most suitable for sentimental ballads and can be directly applied to karaoke content generation. As far as we know, this is the first singer-separation work for real-world karaoke applications.
Read more8/20/2024
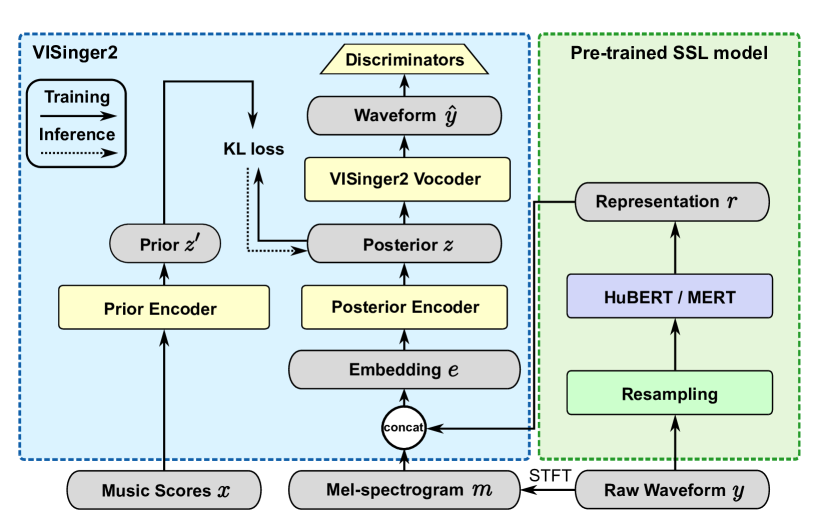
0
VISinger2+: End-to-End Singing Voice Synthesis Augmented by Self-Supervised Learning Representation
Yifeng Yu, Jiatong Shi, Yuning Wu, Shinji Watanabe
Singing Voice Synthesis (SVS) has witnessed significant advancements with the advent of deep learning techniques. However, a significant challenge in SVS is the scarcity of labeled singing voice data, which limits the effectiveness of supervised learning methods. In response to this challenge, this paper introduces a novel approach to enhance the quality of SVS by leveraging unlabeled data from pre-trained self-supervised learning models. Building upon the existing VISinger2 framework, this study integrates additional spectral feature information into the system to enhance its performance. The integration aims to harness the rich acoustic features from the pre-trained models, thereby enriching the synthesis and yielding a more natural and expressive singing voice. Experimental results in various corpora demonstrate the efficacy of this approach in improving the overall quality of synthesized singing voices in both objective and subjective metrics.
Read more6/14/2024