Faithful Knowledge Graph Explanations for Commonsense Reasoning
2310.04910
0
0
📶
Abstract
The fusion of language models (LMs) and knowledge graphs (KGs) is widely used in commonsense question answering, but generating faithful explanations remains challenging. Current methods often overlook path decoding faithfulness, leading to divergence between graph encoder outputs and model predictions. We identify confounding effects and LM-KG misalignment as key factors causing spurious explanations. To address this, we introduce the LM-KG Fidelity metric to assess KG representation reliability and propose the LM-KG Distribution-aware Alignment (textit{LKDA}) algorithm to improve explanation faithfulness. Without ground truth, we evaluate KG explanations using the proposed Fidelity-Sparsity Trade-off Curve. Experiments on CommonsenseQA and OpenBookQA show that LKDA significantly enhances explanation fidelity and model performance, highlighting the need to address distributional misalignment for reliable commonsense reasoning.
Create account to get full access
Overview
- This paper explores the fusion of language models (LMs) and knowledge graphs (KGs) for commonsense question answering, focusing on the challenge of generating faithful explanations.
- The authors identify confounding effects and LM-KG misalignment as key factors leading to spurious explanations, where the outputs of the graph encoder do not align with the model's predictions.
- To address this issue, the researchers introduce the LM-KG Fidelity metric to assess KG representation reliability and propose the LM-KG Distribution-aware Alignment ([object Object]) algorithm to improve explanation faithfulness.
Plain English Explanation
Language models (LMs) and knowledge graphs (KGs) are often combined to help answer common sense questions, but generating clear and reliable explanations for the answers can be challenging. The researchers found that current methods often fail to properly connect the information in the KG with the LM's predictions, leading to explanations that don't really make sense.
They identified two key problems: confounding effects (where other factors influence the explanation) and LM-KG misalignment (where the LM and KG aren't properly aligned). To fix this, the researchers developed a new way to measure how reliable the KG representation is, called the LM-KG Fidelity metric. They also created a new algorithm called LKDA that helps better align the LM and KG, improving the faithfulness of the explanations.
Without having the "ground truth" explanation available, the researchers evaluated the KG explanations using a new method called the Fidelity-Sparsity Trade-off Curve. When tested on common sense question datasets, the LKDA approach significantly improved both the faithfulness of the explanations and the overall performance of the model. This highlights the importance of addressing the misalignment between LMs and KGs for building reliable common sense reasoning systems.
Technical Explanation
The paper focuses on the challenge of generating faithful explanations when fusing language models (LMs) and knowledge graphs (KGs) for commonsense question answering tasks. The authors identify two key issues that can lead to spurious explanations:
- Confounding effects: Factors other than the KG information can influence the model's predictions, leading to explanations that do not accurately reflect the reasoning process.
- LM-KG misalignment: The outputs of the graph encoder do not properly align with the model's predictions, causing a divergence between the KG-based explanation and the actual reasoning.
To address these problems, the researchers introduce the LM-KG Fidelity metric, which assesses the reliability of the KG representation. They also propose the LM-KG Distribution-aware Alignment (LKDA) algorithm, which aims to improve the faithfulness of the explanations by better aligning the LM and KG components.
Since ground truth explanations are not available, the authors evaluate the KG explanations using a novel Fidelity-Sparsity Trade-off Curve. This metric allows them to assess the balance between the faithfulness of the explanations (fidelity) and their conciseness (sparsity).
Experiments on the [object Object] and [object Object] datasets show that the LKDA approach significantly enhances the fidelity of the explanations and improves the overall model performance. This highlights the importance of addressing the distributional misalignment between LMs and KGs for reliable commonsense reasoning, as discussed in related work on [object Object] and [object Object].
Critical Analysis
The paper presents a novel approach to improving the faithfulness of explanations when fusing LMs and KGs for commonsense reasoning. The introduction of the LM-KG Fidelity metric and the LKDA algorithm are valuable contributions to the field, as they address important limitations in current methods.
However, the authors acknowledge that their approach does not provide ground truth explanations, and the evaluation using the Fidelity-Sparsity Trade-off Curve may not fully capture the quality of the explanations. Additionally, the paper does not explore the potential biases or inconsistencies that may exist in the underlying KGs, which could also impact the faithfulness of the explanations.
Further research could investigate ways to directly validate the explanations against human-generated ground truth, or to incorporate additional techniques to mitigate the effects of biases and inconsistencies in the KG data. Exploring the generalization of the LKDA approach to other reasoning tasks beyond commonsense question answering could also be a fruitful avenue for future work.
Conclusion
This paper tackles the important challenge of generating faithful explanations when combining language models and knowledge graphs for commonsense reasoning. By identifying key issues like confounding effects and LM-KG misalignment, the researchers have developed innovative solutions, including the LM-KG Fidelity metric and the LKDA algorithm, to improve the faithfulness of the explanations.
The empirical results on commonsense question answering tasks demonstrate the effectiveness of the LKDA approach, highlighting the significance of addressing distributional misalignment between LMs and KGs for reliable commonsense reasoning. This work represents an important step forward in enhancing the transparency and interpretability of hybrid AI systems that leverage both language understanding and structured knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
FiDeLiS: Faithful Reasoning in Large Language Model for Knowledge Graph Question Answering
Yuan Sui, Yufei He, Nian Liu, Xiaoxin He, Kun Wang, Bryan Hooi
0
0
While large language models (LLMs) have achieved significant success in various applications, they often struggle with hallucinations, especially in scenarios that require deep and responsible reasoning. These issues could be partially mitigate by integrating external knowledge graphs (KG) in LLM reasoning. However, the method of their incorporation is still largely unexplored. In this paper, we propose a retrieval-exploration interactive method, FiDelis to handle intermediate steps of reasoning grounded by KGs. Specifically, we propose Path-RAG module for recalling useful intermediate knowledge from KG for LLM reasoning. We incorporate the logic and common-sense reasoning of LLMs and topological connectivity of KGs into the knowledge retrieval process, which provides more accurate recalling performance. Furthermore, we propose to leverage deductive reasoning capabilities of LLMs as a better criterion to automatically guide the reasoning process in a stepwise and generalizable manner. Deductive verification serve as precise indicators for when to cease further reasoning, thus avoiding misleading the chains of reasoning and unnecessary computation. Extensive experiments show that our method, as a training-free method with lower computational cost and better generality outperforms the existing strong baselines in three benchmarks.
5/24/2024
🌀
An Enhanced Prompt-Based LLM Reasoning Scheme via Knowledge Graph-Integrated Collaboration
Yihao Li, Ru Zhang, Jianyi Liu
0
0
While Large Language Models (LLMs) demonstrate exceptional performance in a multitude of Natural Language Processing (NLP) tasks, they encounter challenges in practical applications, including issues with hallucinations, inadequate knowledge updating, and limited transparency in the reasoning process. To overcome these limitations, this study innovatively proposes a collaborative training-free reasoning scheme involving tight cooperation between Knowledge Graph (KG) and LLMs. This scheme first involves using LLMs to iteratively explore KG, selectively retrieving a task-relevant knowledge subgraph to support reasoning. The LLMs are then guided to further combine inherent implicit knowledge to reason on the subgraph while explicitly elucidating the reasoning process. Through such a cooperative approach, our scheme achieves more reliable knowledge-based reasoning and facilitates the tracing of the reasoning results. Experimental results show that our scheme significantly progressed across multiple datasets, notably achieving over a 10% improvement on the QALD10 dataset compared to the best baseline and the fine-tuned state-of-the-art (SOTA) work. Building on this success, this study hopes to offer a valuable reference for future research in the fusion of KG and LLMs, thereby enhancing LLMs' proficiency in solving complex issues.
6/13/2024

Direct Evaluation of Chain-of-Thought in Multi-hop Reasoning with Knowledge Graphs
Minh-Vuong Nguyen, Linhao Luo, Fatemeh Shiri, Dinh Phung, Yuan-Fang Li, Thuy-Trang Vu, Gholamreza Haffari
0
0
Large language models (LLMs) demonstrate strong reasoning abilities when prompted to generate chain-of-thought (CoT) explanations alongside answers. However, previous research on evaluating LLMs has solely focused on answer accuracy, neglecting the correctness of the generated CoT. In this paper, we delve deeper into the CoT reasoning capabilities of LLMs in multi-hop question answering by utilizing knowledge graphs (KGs). We propose a novel discriminative and generative CoT evaluation paradigm to assess LLMs' knowledge of reasoning and the accuracy of the generated CoT. Through experiments conducted on 5 different families of LLMs across 2 multi-hop question-answering datasets, we find that LLMs possess sufficient knowledge to perform reasoning. However, there exists a significant disparity between answer accuracy and faithfulness of the CoT reasoning generated by LLMs, indicating that they often arrive at correct answers through incorrect reasoning.
6/21/2024
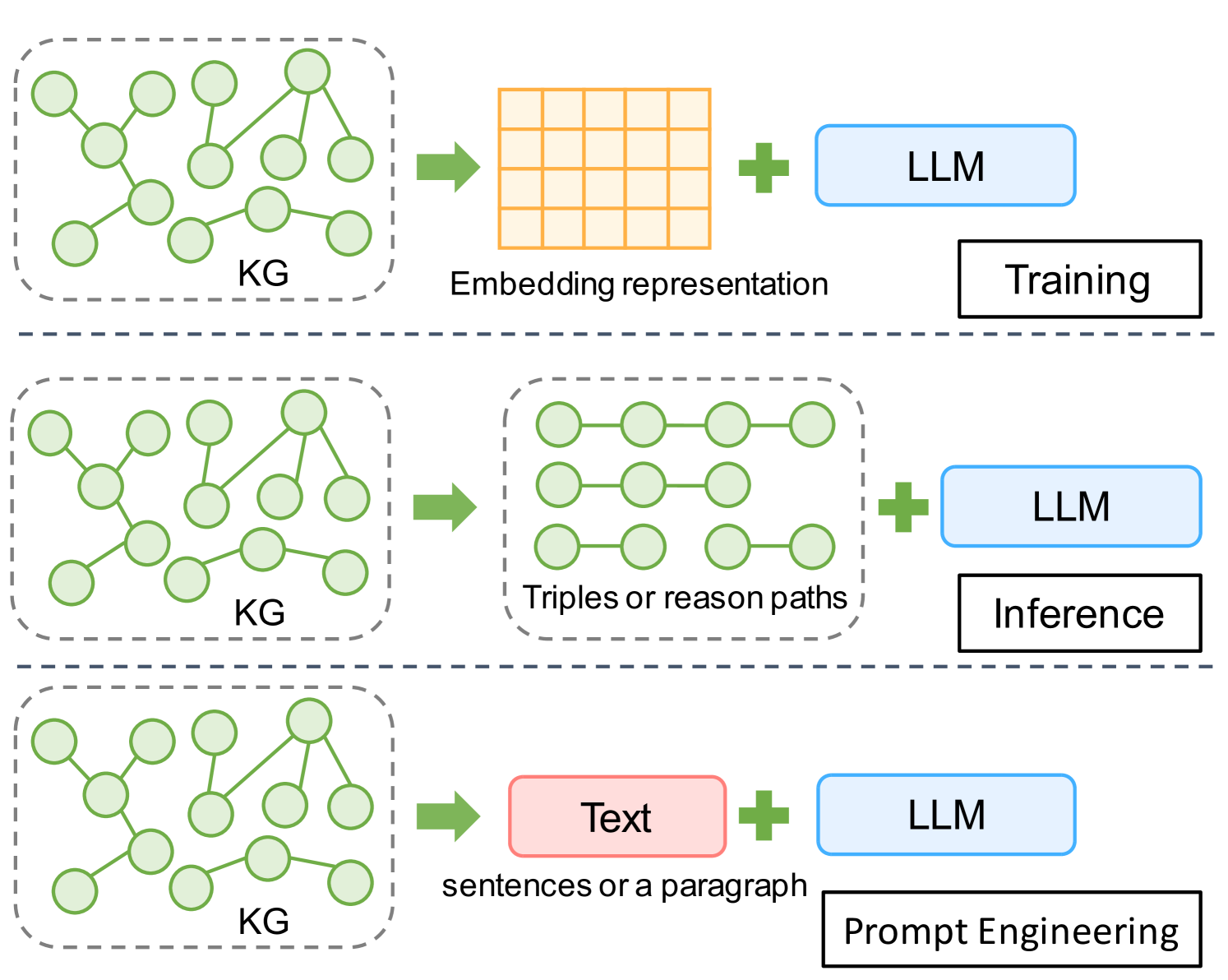
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024