Faster Cascades via Speculative Decoding

0

Sign in to get full access
Overview
- The paper explores a technique called "speculative decoding" to speed up the inference process of large language models (LLMs) in cascaded architectures.
- Cascaded architectures use multiple models in a sequence to perform complex tasks, but this can lead to slow inference times.
- The proposed speculative decoding approach aims to reduce the inference cost by making predictions about the next model's input before it is available.
Plain English Explanation
The paper describes a way to make large language models more efficient when they are used in a sequence, or "cascade," to perform complex tasks.
Imagine you have a set of models that work together - one model might identify the topic of a piece of text, then another model generates a summary, and a third model checks the grammar. This cascade of models can be powerful, but it can also be slow, because each model has to wait for the previous one to finish before it can start.
The researchers propose a technique called "speculative decoding" to speed this up. The idea is that the later models in the cascade can make an educated guess about what the input will be, and start processing it before the actual input is ready. This allows the models to work in parallel, reducing the overall time it takes to get the final result.
The speculative decoding approach is like a chess player trying to anticipate their opponent's next move - if they can make a good guess, they can start planning their response ahead of time. Similarly, the language models can try to guess what the next input will be, and start processing it, saving time in the overall process.
The researchers show that this technique can significantly reduce the inference cost of these cascaded language models, making them more efficient and practical to use in real-world applications.
Technical Explanation
The paper introduces a technique called "speculative decoding" to improve the efficiency of large language model (LLM) inference in cascaded architectures. In a cascaded architecture, multiple models are used in sequence to perform complex tasks, such as topic identification, summarization, and grammar checking.
The key insight of speculative decoding is that later models in the cascade can make an informed guess about their input before it is actually available from the previous model. By speculating about this future input, the later models can start processing it in parallel, reducing the overall inference time.
The authors propose two speculative decoding strategies:
- Token-level speculative decoding, where the later model predicts the likely token-level outputs of the previous model.
- Multimodal speculative decoding, where the later model uses additional modalities (e.g., images) to anticipate its input.
The researchers evaluate these speculative decoding techniques on various cascaded language model architectures and find that they can significantly reduce the overall inference cost compared to a traditional cascaded approach. This improvement in efficiency could make these cascaded LLM systems more practical and accessible for real-world applications.
Critical Analysis
The paper makes a compelling case for the benefits of speculative decoding in improving the efficiency of cascaded language model architectures. The proposed techniques are well-designed and the experimental results are convincing.
However, the authors do not extensively discuss potential limitations or caveats of their approach. For example, the accuracy of the speculative predictions may degrade for longer cascades or more complex tasks, which could reduce the overall benefits. Additionally, the computational and memory overhead of the speculative decoding process itself is not thoroughly analyzed.
Further research could explore the trade-offs between the performance gains and the additional computational costs introduced by the speculative decoding mechanisms. It would also be interesting to see how these techniques perform in real-world applications with diverse data and task requirements.
Overall, the paper presents a promising direction for improving the efficiency of cascaded language model architectures, but additional exploration of the approach's limitations and practical considerations would strengthen the contribution.
Conclusion
The paper introduces a novel technique called "speculative decoding" to improve the efficiency of large language model inference in cascaded architectures. By allowing later models in the cascade to anticipate their inputs, the approach enables parallel processing and reduces the overall inference time.
The researchers demonstrate the effectiveness of their techniques through extensive experiments, showing significant reductions in inference cost compared to traditional cascaded approaches. This improvement in efficiency could make these powerful language model systems more practical and accessible for real-world applications.
While the paper does not fully address potential limitations, the speculative decoding concept represents an important step forward in optimizing the performance of complex, multi-stage machine learning pipelines. As language models continue to grow in scale and complexity, techniques like this will be crucial for unlocking their full potential in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Faster Cascades via Speculative Decoding
Harikrishna Narasimhan, Wittawat Jitkrittum, Ankit Singh Rawat, Seungyeon Kim, Neha Gupta, Aditya Krishna Menon, Sanjiv Kumar
Cascades and speculative decoding are two common approaches to improving language models' inference efficiency. Both approaches involve interleaving models of different sizes, but via fundamentally distinct mechanisms: cascades employ a deferral rule that invokes the larger model only for hard inputs, while speculative decoding uses speculative execution to primarily invoke the larger model in parallel verification mode. These mechanisms offer different benefits: empirically, cascades are often capable of yielding better quality than even the larger model, while theoretically, speculative decoding offers a guarantee of quality-neutrality. In this paper, we leverage the best of both these approaches by designing new speculative cascading techniques that implement their deferral rule through speculative execution. We characterize the optimal deferral rule for our speculative cascades, and employ a plug-in approximation to the optimal rule. Through experiments with T5 models on benchmark language tasks, we show that the proposed approach yields better cost-quality trade-offs than cascading and speculative decoding baselines.
Read more5/30/2024
0
Decoding Speculative Decoding
Minghao Yan, Saurabh Agarwal, Shivaram Venkataraman
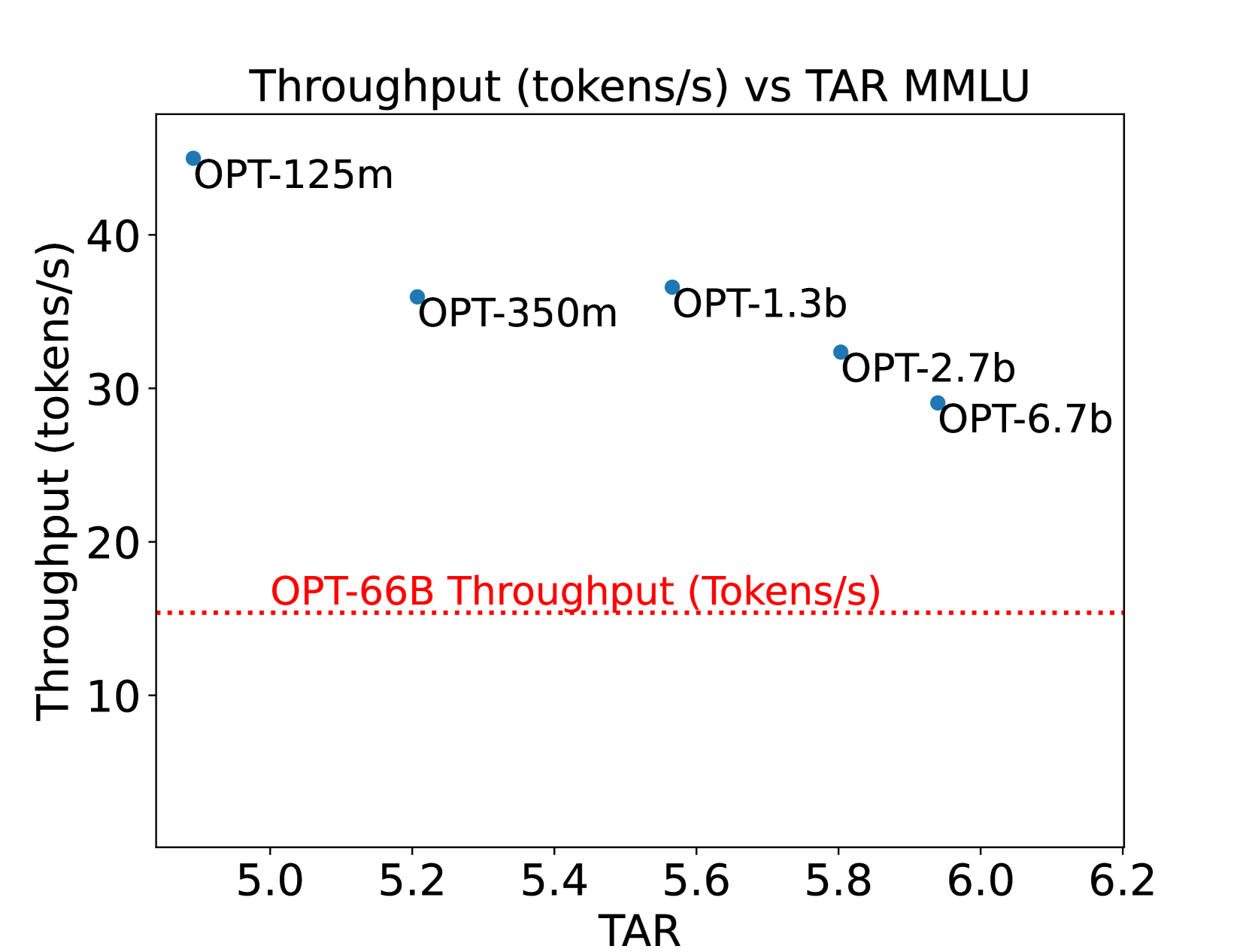
Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without sacrificing quality. When performing inference, speculative decoding uses a smaller draft model to generate speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. In this work, we perform a detailed study comprising over 350 experiments with LLaMA-65B and OPT-66B using speculative decoding and delineate the factors that affect the performance gain provided by speculative decoding. Our experiments indicate that the performance of speculative decoding depends heavily on the latency of the draft model, and the draft model's capability in language modeling does not correlate strongly with its performance in speculative decoding. Based on these insights we explore a new design space for draft models and design hardware-efficient draft models for speculative decoding. Our newly designed draft model for LLaMA-65B can provide 111% higher throughput than existing draft models and can generalize further to the LLaMA-2 model family and supervised fine-tuned models.
Read more8/13/2024
💬
0
Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding
Heming Xia, Zhe Yang, Qingxiu Dong, Peiyi Wang, Yongqi Li, Tao Ge, Tianyu Liu, Wenjie Li, Zhifang Sui
To mitigate the high inference latency stemming from autoregressive decoding in Large Language Models (LLMs), Speculative Decoding has emerged as a novel decoding paradigm for LLM inference. In each decoding step, this method first drafts several future tokens efficiently and then verifies them in parallel. Unlike autoregressive decoding, Speculative Decoding facilitates the simultaneous decoding of multiple tokens per step, thereby accelerating inference. This paper presents a comprehensive overview and analysis of this promising decoding paradigm. We begin by providing a formal definition and formulation of Speculative Decoding. Then, we organize in-depth discussions on its key facets, such as drafter selection and verification strategies. Furthermore, we present a comparative analysis of leading methods under third-party testing environments. We aim for this work to serve as a catalyst for further research on Speculative Decoding, ultimately contributing to more efficient LLM inference.
Read more6/5/2024

0
Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion
Jacob K Christopher, Brian R Bartoldson, Bhavya Kailkhura, Ferdinando Fioretto
Speculative decoding has emerged as a widely adopted method to accelerate large language model inference without sacrificing the quality of the model outputs. While this technique has facilitated notable speed improvements by enabling parallel sequence verification, its efficiency remains inherently limited by the reliance on incremental token generation in existing draft models. To overcome this limitation, this paper proposes an adaptation of speculative decoding which uses discrete diffusion models to generate draft sequences. This allows parallelization of both the drafting and verification steps, providing significant speed-ups to the inference process. Our proposed approach, Speculative Diffusion Decoding (SpecDiff), is validated on standard language generation benchmarks and empirically demonstrated to provide a up to 8.7x speed-up over standard generation processes and up to 2.5x speed-up over existing speculative decoding approaches.
Read more8/20/2024