FastLGS: Speeding up Language Embedded Gaussians with Feature Grid Mapping

0

Sign in to get full access
Overview
- This paper introduces FastLGS, a method for speeding up language-embedded Gaussians (LGS) by using a feature grid mapping approach.
- LGS is a technique for performing open-vocabulary detection, zero-shot learning, and semantic 3D field tasks.
- FastLGS aims to improve the efficiency of LGS by using a grid-based representation to speed up computations.
Plain English Explanation
The paper describes a new method called FastLGS that can make a type of machine learning model called language-embedded Gaussians (LGS) run faster. LGS models are used for tasks like open-vocabulary object detection, zero-shot learning, and creating semantic 3D maps.
The key idea in FastLGS is to represent the features used by the LGS model in a grid-like structure, rather than a more general format. This grid-based representation allows the computations needed for the LGS model to be performed more efficiently, speeding up the overall process. The paper shows that FastLGS can achieve significant speedups compared to the original LGS approach, while maintaining similar accuracy.
Technical Explanation
The paper introduces FastLGS, a method for improving the efficiency of language-embedded Gaussians (LGS), a technique used for tasks like open-vocabulary object detection, zero-shot learning, and semantic 3D field estimation.
The key innovation in FastLGS is the use of a feature grid mapping approach. Instead of representing features in a general format, FastLGS organizes them into a regular grid structure. This grid-based representation allows for more efficient computations when applying the LGS model, leading to significant speedups.
The paper presents a detailed evaluation of FastLGS on several benchmark datasets, comparing its performance to the original LGS approach. The results show that FastLGS can achieve up to 5x speedups while maintaining similar accuracy levels. The authors also analyze the impact of different grid resolutions and other hyperparameters on the performance of FastLGS.
Critical Analysis
The paper provides a compelling approach for improving the efficiency of LGS models, which are widely used for a variety of computer vision tasks. The use of a feature grid mapping is a clever optimization that leverages the inherent structure of the problem to enable faster computations.
One potential limitation of the FastLGS approach is that it may not be as flexible as the original LGS formulation, which can operate on more general feature representations. The grid-based approach may introduce some constraints or trade-offs that could impact the model's performance in certain scenarios.
Additionally, the paper does not explore the generalization of FastLGS to other types of models or tasks beyond the specific LGS use case. It would be interesting to see if the grid mapping technique could be applied more broadly to improve the efficiency of other machine learning models.
Overall, the FastLGS method presented in this paper is a valuable contribution to the field of efficient deep learning, and the authors' insights could inspire further research into specialized hardware or software optimizations for language-grounded computer vision models.
Conclusion
This paper introduces FastLGS, a method for speeding up language-embedded Gaussians (LGS) by using a feature grid mapping approach. LGS is a powerful technique for tasks like open-vocabulary object detection, zero-shot learning, and semantic 3D field estimation.
The key innovation in FastLGS is the use of a grid-based representation for the features used by the LGS model. This grid-based approach allows for more efficient computations, leading to significant speedups of up to 5x compared to the original LGS method, while maintaining similar accuracy levels.
The FastLGS technique presents an interesting optimization for LGS models and could have broader implications for improving the efficiency of language-grounded computer vision systems. Further research could explore the generalization of the grid mapping approach to other types of models and tasks beyond the specific use case presented in this paper.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FastLGS: Speeding up Language Embedded Gaussians with Feature Grid Mapping
Yuzhou Ji, He Zhu, Junshu Tang, Wuyi Liu, Zhizhong Zhang, Yuan Xie, Xin Tan
The semantically interactive radiance field has always been an appealing task for its potential to facilitate user-friendly and automated real-world 3D scene understanding applications. However, it is a challenging task to achieve high quality, efficiency and zero-shot ability at the same time with semantics in radiance fields. In this work, we present FastLGS, an approach that supports real-time open-vocabulary query within 3D Gaussian Splatting (3DGS) under high resolution. We propose the semantic feature grid to save multi-view CLIP features which are extracted based on Segment Anything Model (SAM) masks, and map the grids to low dimensional features for semantic field training through 3DGS. Once trained, we can restore pixel-aligned CLIP embeddings through feature grids from rendered features for open-vocabulary queries. Comparisons with other state-of-the-art methods prove that FastLGS can achieve the first place performance concerning both speed and accuracy, where FastLGS is 98x faster than LERF and 4x faster than LangSplat. Meanwhile, experiments show that FastLGS is adaptive and compatible with many downstream tasks, such as 3D segmentation and 3D object inpainting, which can be easily applied to other 3D manipulation systems.
Read more8/13/2024
✨
0
Feature 3DGS: Supercharging 3D Gaussian Splatting to Enable Distilled Feature Fields
Shijie Zhou, Haoran Chang, Sicheng Jiang, Zhiwen Fan, Zehao Zhu, Dejia Xu, Pradyumna Chari, Suya You, Zhangyang Wang, Achuta Kadambi
3D scene representations have gained immense popularity in recent years. Methods that use Neural Radiance fields are versatile for traditional tasks such as novel view synthesis. In recent times, some work has emerged that aims to extend the functionality of NeRF beyond view synthesis, for semantically aware tasks such as editing and segmentation using 3D feature field distillation from 2D foundation models. However, these methods have two major limitations: (a) they are limited by the rendering speed of NeRF pipelines, and (b) implicitly represented feature fields suffer from continuity artifacts reducing feature quality. Recently, 3D Gaussian Splatting has shown state-of-the-art performance on real-time radiance field rendering. In this work, we go one step further: in addition to radiance field rendering, we enable 3D Gaussian splatting on arbitrary-dimension semantic features via 2D foundation model distillation. This translation is not straightforward: naively incorporating feature fields in the 3DGS framework encounters significant challenges, notably the disparities in spatial resolution and channel consistency between RGB images and feature maps. We propose architectural and training changes to efficiently avert this problem. Our proposed method is general, and our experiments showcase novel view semantic segmentation, language-guided editing and segment anything through learning feature fields from state-of-the-art 2D foundation models such as SAM and CLIP-LSeg. Across experiments, our distillation method is able to provide comparable or better results, while being significantly faster to both train and render. Additionally, to the best of our knowledge, we are the first method to enable point and bounding-box prompting for radiance field manipulation, by leveraging the SAM model. Project website at: https://feature-3dgs.github.io/
Read more4/9/2024
0
RT-GS2: Real-Time Generalizable Semantic Segmentation for 3D Gaussian Representations of Radiance Fields
Mihnea-Bogdan Jurca, Remco Royen, Ion Giosan, Adrian Munteanu
Gaussian Splatting has revolutionized the world of novel view synthesis by achieving high rendering performance in real-time. Recently, studies have focused on enriching these 3D representations with semantic information for downstream tasks. In this paper, we introduce RT-GS2, the first generalizable semantic segmentation method employing Gaussian Splatting. While existing Gaussian Splatting-based approaches rely on scene-specific training, RT-GS2 demonstrates the ability to generalize to unseen scenes. Our method adopts a new approach by first extracting view-independent 3D Gaussian features in a self-supervised manner, followed by a novel View-Dependent / View-Independent (VDVI) feature fusion to enhance semantic consistency over different views. Extensive experimentation on three different datasets showcases RT-GS2's superiority over the state-of-the-art methods in semantic segmentation quality, exemplified by a 8.01% increase in mIoU on the Replica dataset. Moreover, our method achieves real-time performance of 27.03 FPS, marking an astonishing 901 times speedup compared to existing approaches. This work represents a significant advancement in the field by introducing, to the best of our knowledge, the first real-time generalizable semantic segmentation method for 3D Gaussian representations of radiance fields.
Read more9/2/2024
15
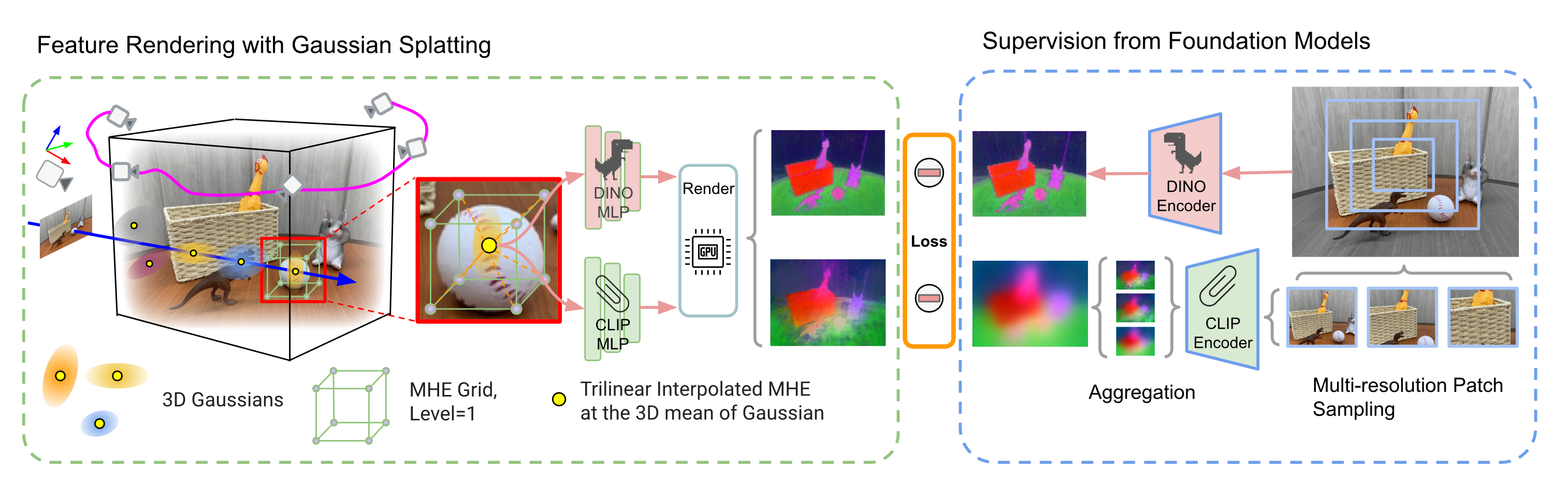
FMGS: Foundation Model Embedded 3D Gaussian Splatting for Holistic 3D Scene Understanding
Xingxing Zuo, Pouya Samangouei, Yunwen Zhou, Yan Di, Mingyang Li
Precisely perceiving the geometric and semantic properties of real-world 3D objects is crucial for the continued evolution of augmented reality and robotic applications. To this end, we present Foundation Model Embedded Gaussian Splatting (FMGS), which incorporates vision-language embeddings of foundation models into 3D Gaussian Splatting (GS). The key contribution of this work is an efficient method to reconstruct and represent 3D vision-language models. This is achieved by distilling feature maps generated from image-based foundation models into those rendered from our 3D model. To ensure high-quality rendering and fast training, we introduce a novel scene representation by integrating strengths from both GS and multi-resolution hash encodings (MHE). Our effective training procedure also introduces a pixel alignment loss that makes the rendered feature distance of the same semantic entities close, following the pixel-level semantic boundaries. Our results demonstrate remarkable multi-view semantic consistency, facilitating diverse downstream tasks, beating state-of-the-art methods by 10.2 percent on open-vocabulary language-based object detection, despite that we are 851X faster for inference. This research explores the intersection of vision, language, and 3D scene representation, paving the way for enhanced scene understanding in uncontrolled real-world environments. We plan to release the code on the project page.
Read more5/7/2024