Recurrent Early Exits for Federated Learning with Heterogeneous Clients
2405.14791
0
0
🏋️
Abstract
Federated learning (FL) has enabled distributed learning of a model across multiple clients in a privacy-preserving manner. One of the main challenges of FL is to accommodate clients with varying hardware capacities; clients have differing compute and memory requirements. To tackle this challenge, recent state-of-the-art approaches leverage the use of early exits. Nonetheless, these approaches fall short of mitigating the challenges of joint learning multiple exit classifiers, often relying on hand-picked heuristic solutions for knowledge distillation among classifiers and/or utilizing additional layers for weaker classifiers. In this work, instead of utilizing multiple classifiers, we propose a recurrent early exit approach named ReeFL that fuses features from different sub-models into a single shared classifier. Specifically, we use a transformer-based early-exit module shared among sub-models to i) better exploit multi-layer feature representations for task-specific prediction and ii) modulate the feature representation of the backbone model for subsequent predictions. We additionally present a per-client self-distillation approach where the best sub-model is automatically selected as the teacher of the other sub-models at each client. Our experiments on standard image and speech classification benchmarks across various emerging federated fine-tuning baselines demonstrate ReeFL's effectiveness over previous works.
Create account to get full access
Overview
- Federated learning (FL) enables distributed training of a model across multiple clients while preserving privacy.
- One key challenge in FL is accommodating clients with varying hardware capabilities, as they have different compute and memory requirements.
- Recent approaches have used early exits to address this, but they struggle with jointly learning multiple exit classifiers and often rely on heuristic solutions for knowledge distillation.
Plain English Explanation
Federated learning is a way for different devices, like phones or computers, to work together to train a machine learning model without sharing the private data on each device. This is helpful because it allows training a model without sacrificing people's privacy.
One problem with federated learning is that the different devices might have very different hardware capabilities. Some devices might be faster or have more memory than others. This can make it hard to train the model effectively.
Recent methods have tried to solve this by using "early exits" - parts of the model that can make predictions before the full model is done processing. This allows slower devices to exit early and still contribute to the model. However, these methods have trouble coordinating the training of all the different exit parts, and often rely on manual tricks to make it work.
Instead of using multiple exit classifiers, the new approach called ReeFL uses a single shared classifier that combines features from different sub-models. It also has a way for each device to automatically select the best sub-model to learn from, without needing manual tuning.
Technical Explanation
ReeFL proposes a recurrent early exit approach that uses a single shared classifier, rather than multiple exit classifiers. This shared classifier approach aims to better exploit multi-layer feature representations for task-specific prediction and modulate the feature representation of the backbone model.
Additionally, ReeFL introduces a per-client self-distillation technique, where the best sub-model on each client is automatically selected as the "teacher" to guide the learning of the other sub-models. This personalized approach helps accommodate the hardware heterogeneity across clients.
The authors evaluate ReeFL on standard image and speech classification benchmarks, comparing it to various federated fine-tuning baselines and resource-aware FL methods. Their experiments demonstrate the effectiveness of ReeFL's recurrent early exit and self-distillation techniques compared to previous approaches.
Critical Analysis
The paper provides a novel approach to addressing the hardware heterogeneity challenge in federated learning, which is an important problem to solve. The use of a shared classifier and per-client self-distillation are interesting ideas that seek to improve upon prior early exit-based methods.
However, the paper does not deeply explore the limitations of the ReeFL approach. For example, it is unclear how the recurrent early exit module and self-distillation scale to very deep or complex models, or how they perform under more diverse hardware settings. Additionally, the computational and memory overhead of the shared classifier design is not analyzed in detail.
Further research could investigate the robustness of ReeFL to higher degrees of hardware heterogeneity, as well as its applicability to a wider range of federated learning scenarios, such as decentralized and unshared data archives. Exploring the trade-offs between the benefits of ReeFL and its potential drawbacks would also help provide a more holistic understanding of the approach.
Conclusion
The ReeFL approach presented in this paper offers a novel solution to the hardware heterogeneity challenge in federated learning. By using a shared classifier and per-client self-distillation, it aims to better accommodate clients with varying compute and memory capabilities. While the results are promising, further research is needed to fully understand the limitations and broader applicability of this technique. Overall, ReeFL represents an interesting step forward in making federated learning more robust and practical for real-world deployments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
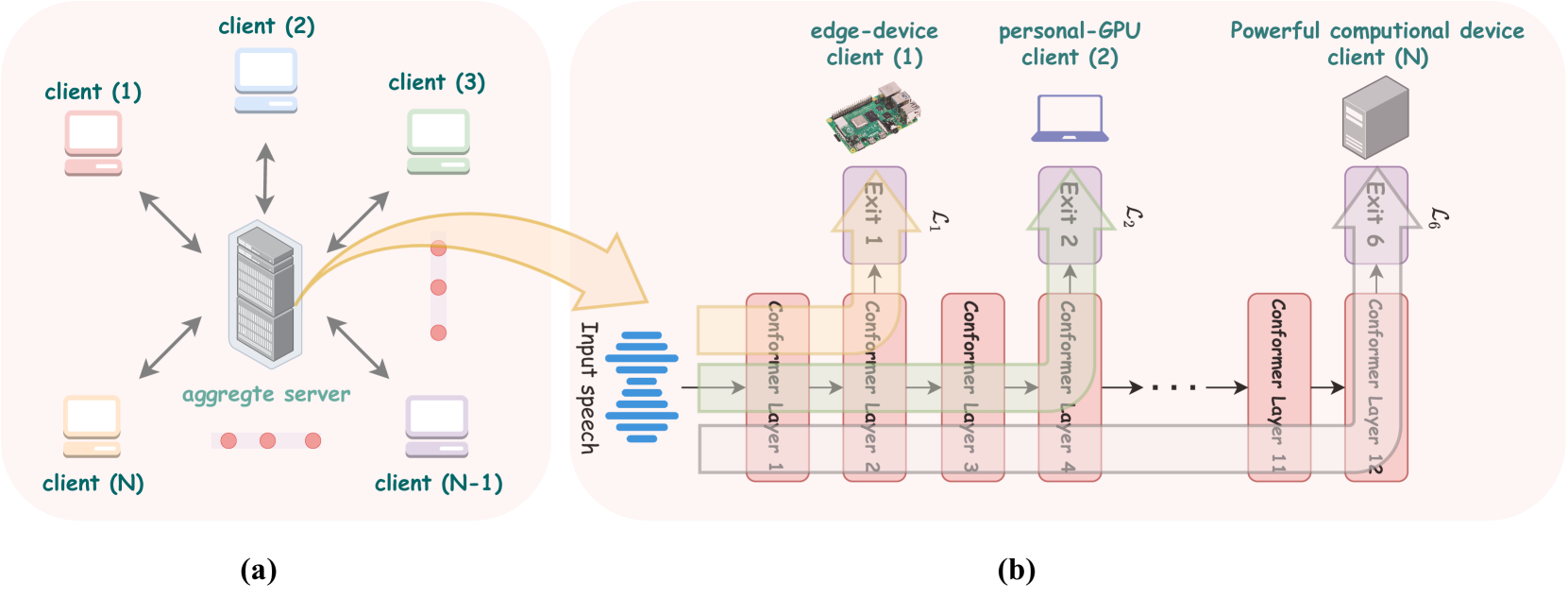
Federating Dynamic Models using Early-Exit Architectures for Automatic Speech Recognition on Heterogeneous Clients
Mohamed Nabih Ali, Alessio Brutti, Daniele Falavigna
0
0
Automatic speech recognition models require large amounts of speech recordings for training. However, the collection of such data often is cumbersome and leads to privacy concerns. Federated learning has been widely used as an effective decentralized technique that collaboratively learns a shared prediction model while keeping the data local on different clients. Unfortunately, client devices often feature limited computation and communication resources leading to practical difficulties for large models. In addition, the heterogeneity that characterizes edge devices makes it sub-optimal to generate a single model that fits all of them. Differently from the recent literature, where multiple models with different architectures are used, in this work, we propose using dynamical architectures which, employing early-exit solutions, can adapt their processing (i.e. traversed layers) depending on the input and on the operation conditions. This solution falls in the realm of partial training methods and brings two benefits: a single model is used on a variety of devices; federating the models after local training is straightforward. Experiments on public datasets show that our proposed approach is effective and can be combined with basic federated learning strategies.
5/28/2024
🤯
Federated Learning for Cooperative Inference Systems: The Case of Early Exit Networks
Caelin Kaplan, Tareq Si Salem, Angelo Rodio, Chuan Xu, Giovanni Neglia
0
0
As Internet of Things (IoT) technology advances, end devices like sensors and smartphones are progressively equipped with AI models tailored to their local memory and computational constraints. Local inference reduces communication costs and latency; however, these smaller models typically underperform compared to more sophisticated models deployed on edge servers or in the cloud. Cooperative Inference Systems (CISs) address this performance trade-off by enabling smaller devices to offload part of their inference tasks to more capable devices. These systems often deploy hierarchical models that share numerous parameters, exemplified by Deep Neural Networks (DNNs) that utilize strategies like early exits or ordered dropout. In such instances, Federated Learning (FL) may be employed to jointly train the models within a CIS. Yet, traditional training methods have overlooked the operational dynamics of CISs during inference, particularly the potential high heterogeneity in serving rates across clients. To address this gap, we propose a novel FL approach designed explicitly for use in CISs that accounts for these variations in serving rates. Our framework not only offers rigorous theoretical guarantees, but also surpasses state-of-the-art (SOTA) training algorithms for CISs, especially in scenarios where inference request rates or data availability are uneven among clients.
5/8/2024
FedTrans: Efficient Federated Learning Over Heterogeneous Clients via Model Transformation
Yuxuan Zhu, Jiachen Liu, Mosharaf Chowdhury, Fan Lai
0
0
Federated learning (FL) aims to train machine learning (ML) models across potentially millions of edge client devices. Yet, training and customizing models for FL clients is notoriously challenging due to the heterogeneity of client data, device capabilities, and the massive scale of clients, making individualized model exploration prohibitively expensive. State-of-the-art FL solutions personalize a globally trained model or concurrently train multiple models, but they often incur suboptimal model accuracy and huge training costs. In this paper, we introduce FedTrans, a multi-model FL training framework that automatically produces and trains high-accuracy, hardware-compatible models for individual clients at scale. FedTrans begins with a basic global model, identifies accuracy bottlenecks in model architectures during training, and then employs model transformation to derive new models for heterogeneous clients on the fly. It judiciously assigns models to individual clients while performing soft aggregation on multi-model updates to minimize total training costs. Our evaluations using realistic settings show that FedTrans improves individual client model accuracy by 14% - 72% while slashing training costs by 1.6X - 20X over state-of-the-art solutions.
4/29/2024
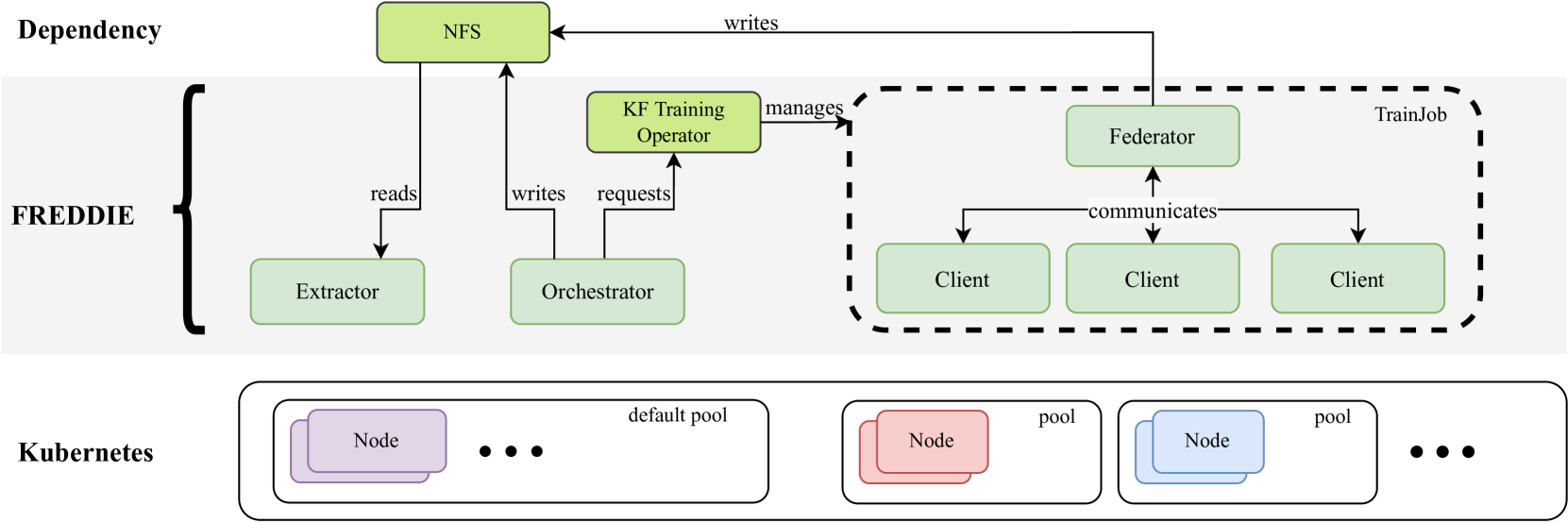
Parameterizing Federated Continual Learning for Reproducible Research
Bart Cox, Jeroen Galjaard, Aditya Shankar, J'er'emie Decouchant, Lydia Y. Chen
0
0
Federated Learning (FL) systems evolve in heterogeneous and ever-evolving environments that challenge their performance. Under real deployments, the learning tasks of clients can also evolve with time, which calls for the integration of methodologies such as Continual Learning. To enable research reproducibility, we propose a set of experimental best practices that precisely capture and emulate complex learning scenarios. Our framework, Freddie, is the first entirely configurable framework for Federated Continual Learning (FCL), and it can be seamlessly deployed on a large number of machines thanks to the use of Kubernetes and containerization. We demonstrate the effectiveness of Freddie on two use cases, (i) large-scale FL on CIFAR100 and (ii) heterogeneous task sequence on FCL, which highlight unaddressed performance challenges in FCL scenarios.
6/5/2024