Federating Dynamic Models using Early-Exit Architectures for Automatic Speech Recognition on Heterogeneous Clients

0
Sign in to get full access
Overview
- The paper explores a federated learning approach for Automatic Speech Recognition (ASR) that uses early-exit architectures to improve performance on heterogeneous client devices.
- It proposes a method to dynamically federate multiple ASR models with different complexities, allowing clients to exit the model early based on their computational capabilities.
- The goal is to balance the trade-off between model accuracy and inference time, enabling efficient ASR on a wide range of client devices.
Plain English Explanation
Automatic Speech Recognition (ASR) is the technology that allows computers to understand and transcribe human speech. When using ASR in real-world applications, such as voice assistants or translation services, it's important to consider the varying computational capabilities of the devices that will be running the ASR models.
The paper presents a Federated Learning approach to address this challenge. Federated Learning is a technique where a central model is trained across multiple devices, without the need to share the users' raw data. This is particularly useful for privacy-sensitive applications.
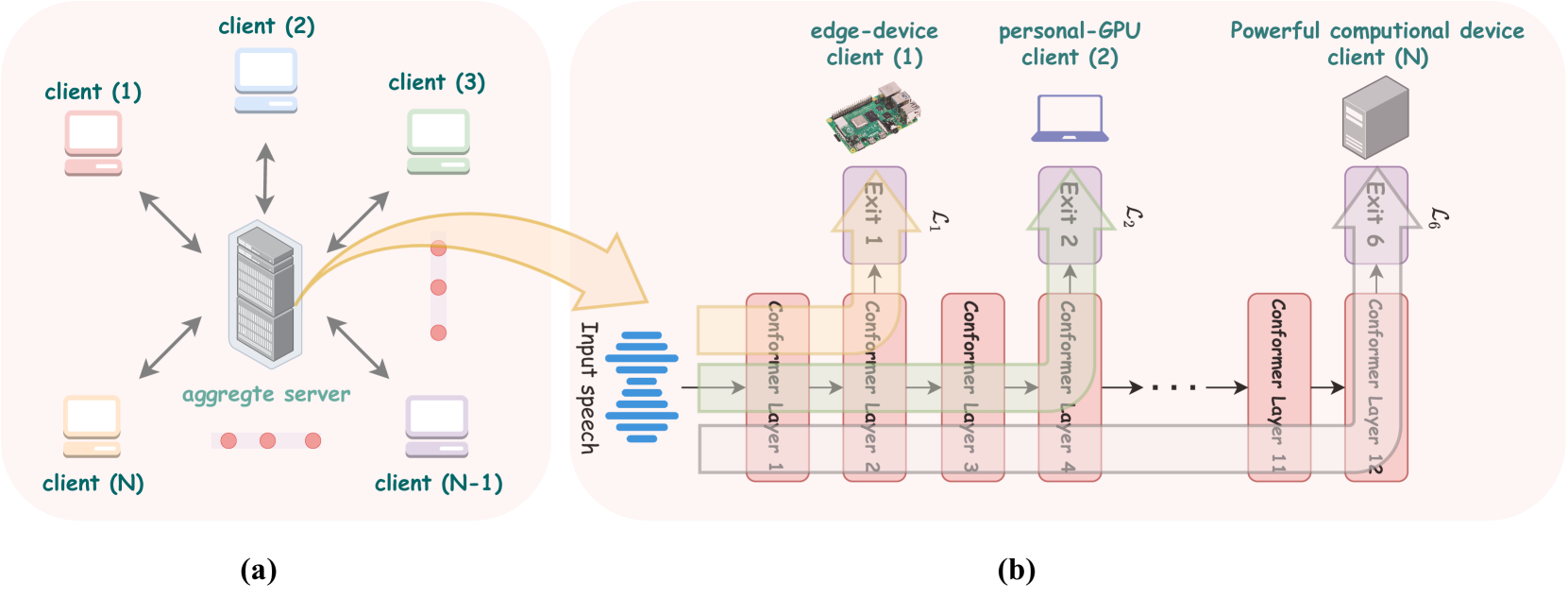
The key innovation in this paper is the use of Early-Exit Architectures. These are neural network models that are designed to produce a result at different stages of the computation, allowing the system to "exit" the model early if the intermediate result is already good enough. This is especially beneficial for devices with limited processing power, as they can complete the task more efficiently without running the full, computationally-intensive model.
The proposed method federates multiple ASR models with different complexities, allowing each client device to select the model that best matches its capabilities. This dynamic model selection helps to balance the trade-off between accuracy and inference time, ensuring that ASR can be performed efficiently on a wide range of client devices, from powerful servers to resource-constrained smartphones.
Technical Explanation
The paper introduces a Federated Learning approach for Automatic Speech Recognition (ASR) that leverages early-exit architectures to improve performance on heterogeneous client devices.
The key components of the proposed method are:
-
Early-Exit Architectures: The ASR models are designed with multiple intermediate output layers, allowing the system to produce a result before the full model computation is completed. This enables clients to exit the model early based on their computational resources, trading off accuracy for inference speed.
-
Dynamic Model Federating: The system federates multiple ASR models with different complexities, creating a pool of models that can be selectively deployed to client devices. Clients can choose the model that best matches their hardware capabilities, optimizing the balance between accuracy and inference time.
-
Federated Learning: The ASR models are trained in a federated manner, where the central model is updated based on the gradients computed on client devices. This allows the models to be personalized to individual users' speech patterns without compromising their privacy.
The paper evaluates the proposed approach on a large-scale ASR dataset, comparing it to traditional federated learning and static model deployment strategies. The results demonstrate that the dynamic model selection enabled by early-exit architectures can significantly improve the inference efficiency on heterogeneous client devices, without substantially compromising the overall model accuracy.
Critical Analysis
The paper presents a compelling approach to address the challenge of deploying ASR models on a wide range of client devices with varying computational capabilities. The use of early-exit architectures and dynamic model federating is a novel and promising solution that could have broad applications in other domains beyond ASR.
However, the paper does not fully explore the potential limitations and trade-offs of the proposed method. For example, the impact of the early-exit thresholds on model accuracy and the robustness of the dynamic model selection process are not extensively analyzed. Additionally, the paper does not discuss potential issues related to the federated learning setup, such as the effects of client device heterogeneity, communication costs, or data distribution skew.
Further research could be conducted to investigate these aspects more deeply, as well as to explore the application of the proposed techniques to other types of deep learning models and tasks. Additionally, it would be valuable to see how the method performs in real-world deployments, with a more diverse set of client devices and usage patterns.
Conclusion
The paper presents a novel Federated Learning approach for Automatic Speech Recognition that leverages early-exit architectures and dynamic model federating to improve inference efficiency on heterogeneous client devices. By allowing clients to select the most appropriate ASR model based on their computational capabilities, the proposed method can effectively balance the trade-off between model accuracy and inference time.
This research contributes to the growing field of Federated Learning and efficient deep learning inference on edge devices, with potential applications in a wide range of real-world scenarios where Automatic Speech Recognition is required, such as voice assistants, translation services, and smart home devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Federating Dynamic Models using Early-Exit Architectures for Automatic Speech Recognition on Heterogeneous Clients
Mohamed Nabih Ali, Alessio Brutti, Daniele Falavigna
Automatic speech recognition models require large amounts of speech recordings for training. However, the collection of such data often is cumbersome and leads to privacy concerns. Federated learning has been widely used as an effective decentralized technique that collaboratively learns a shared prediction model while keeping the data local on different clients. Unfortunately, client devices often feature limited computation and communication resources leading to practical difficulties for large models. In addition, the heterogeneity that characterizes edge devices makes it sub-optimal to generate a single model that fits all of them. Differently from the recent literature, where multiple models with different architectures are used, in this work, we propose using dynamical architectures which, employing early-exit solutions, can adapt their processing (i.e. traversed layers) depending on the input and on the operation conditions. This solution falls in the realm of partial training methods and brings two benefits: a single model is used on a variety of devices; federating the models after local training is straightforward. Experiments on public datasets show that our proposed approach is effective and can be combined with basic federated learning strategies.
Read more5/28/2024
🏋️
0
Recurrent Early Exits for Federated Learning with Heterogeneous Clients
Royson Lee, Javier Fernandez-Marques, Shell Xu Hu, Da Li, Stefanos Laskaridis, {L}ukasz Dudziak, Timothy Hospedales, Ferenc Husz'ar, Nicholas D. Lane
Federated learning (FL) has enabled distributed learning of a model across multiple clients in a privacy-preserving manner. One of the main challenges of FL is to accommodate clients with varying hardware capacities; clients have differing compute and memory requirements. To tackle this challenge, recent state-of-the-art approaches leverage the use of early exits. Nonetheless, these approaches fall short of mitigating the challenges of joint learning multiple exit classifiers, often relying on hand-picked heuristic solutions for knowledge distillation among classifiers and/or utilizing additional layers for weaker classifiers. In this work, instead of utilizing multiple classifiers, we propose a recurrent early exit approach named ReeFL that fuses features from different sub-models into a single shared classifier. Specifically, we use a transformer-based early-exit module shared among sub-models to i) better exploit multi-layer feature representations for task-specific prediction and ii) modulate the feature representation of the backbone model for subsequent predictions. We additionally present a per-client self-distillation approach where the best sub-model is automatically selected as the teacher of the other sub-models at each client. Our experiments on standard image and speech classification benchmarks across various emerging federated fine-tuning baselines demonstrate ReeFL's effectiveness over previous works.
Read more5/28/2024

0
Exploring System-Heterogeneous Federated Learning with Dynamic Model Selection
Dixi Yao
Federated learning is a distributed learning paradigm in which multiple mobile clients train a global model while keeping data local. These mobile clients can have various available memory and network bandwidth. However, to achieve the best global model performance, how we can utilize available memory and network bandwidth to the maximum remains an open challenge. In this paper, we propose to assign each client a subset of the global model, having different layers and channels on each layer. To realize that, we design a constrained model search process with early stop to improve efficiency of finding the models from such a very large space; and a data-free knowledge distillation mechanism to improve the global model performance when aggregating models of such different structures. For fair and reproducible comparison between different solutions, we develop a new system, which can directly allocate different memory and bandwidth to each client according to memory and bandwidth logs collected on mobile devices. The evaluation shows that our solution can have accuracy increase ranging from 2.43% to 15.81% and provide 5% to 40% more memory and bandwidth utilization with negligible extra running time, comparing to existing state-of-the-art system-heterogeneous federated learning methods under different available memory and bandwidth, non-i.i.d.~datasets, image and text tasks.
Read more9/16/2024

0
Federated Learning with Flexible Architectures
Jong-Ik Park, Carlee Joe-Wong
Traditional federated learning (FL) methods have limited support for clients with varying computational and communication abilities, leading to inefficiencies and potential inaccuracies in model training. This limitation hinders the widespread adoption of FL in diverse and resource-constrained environments, such as those with client devices ranging from powerful servers to mobile devices. To address this need, this paper introduces Federated Learning with Flexible Architectures (FedFA), an FL training algorithm that allows clients to train models of different widths and depths. Each client can select a network architecture suitable for its resources, with shallower and thinner networks requiring fewer computing resources for training. Unlike prior work in this area, FedFA incorporates the layer grafting technique to align clients' local architectures with the largest network architecture in the FL system during model aggregation. Layer grafting ensures that all client contributions are uniformly integrated into the global model, thereby minimizing the risk of any individual client's data skewing the model's parameters disproportionately and introducing security benefits. Moreover, FedFA introduces the scalable aggregation method to manage scale variations in weights among different network architectures. Experimentally, FedFA outperforms previous width and depth flexible aggregation strategies. Furthermore, FedFA demonstrates increased robustness against performance degradation in backdoor attack scenarios compared to earlier strategies.
Read more6/17/2024