Investigating Wit, Creativity, and Detectability of Large Language Models in Domain-Specific Writing Style Adaptation of Reddit's Showerthoughts
2405.01660
3
0
💬
Abstract
Recent Large Language Models (LLMs) have shown the ability to generate content that is difficult or impossible to distinguish from human writing. We investigate the ability of differently-sized LLMs to replicate human writing style in short, creative texts in the domain of Showerthoughts, thoughts that may occur during mundane activities. We compare GPT-2 and GPT-Neo fine-tuned on Reddit data as well as GPT-3.5 invoked in a zero-shot manner, against human-authored texts. We measure human preference on the texts across the specific dimensions that account for the quality of creative, witty texts. Additionally, we compare the ability of humans versus fine-tuned RoBERTa classifiers to detect AI-generated texts. We conclude that human evaluators rate the generated texts slightly worse on average regarding their creative quality, but they are unable to reliably distinguish between human-written and AI-generated texts. We further provide a dataset for creative, witty text generation based on Reddit Showerthoughts posts.
Create account to get full access
Overview
- This research examines the ability of large language models (LLMs) to generate content that is difficult for humans to distinguish from human-written texts.
- The authors focus on the domain of "Showerthoughts" - short, creative, and witty thoughts that may occur during everyday activities.
- They compare the performance of different LLM models, including GPT-2, GPT-Neo, and GPT-3.5, in generating texts that mimic human-written Showerthoughts.
- The study also investigates the ability of human evaluators and fine-tuned RoBERTa classifiers to detect AI-generated texts.
- The researchers provide a dataset of Reddit Showerthoughts posts to support further research in this area.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly good at generating text that can be hard to distinguish from human writing. In this study, the researchers wanted to see how well these LLMs could create short, creative "Showerthoughts" - the kind of quirky, witty observations that people might have while doing everyday tasks like showering.
The researchers took a few different LLM models, including GPT-2, GPT-Neo, and GPT-3.5, and had them try to generate Showerthought-style texts. They then showed these texts, along with some real human-written Showerthoughts, to people and asked them to rate the creativity and quality of the texts. They also tested whether humans or AI classifiers could reliably tell the difference between the human-written and AI-generated texts.
Overall, the researchers found that the LLM-generated texts were rated slightly lower in quality compared to the human-written ones. But importantly, the human evaluators were not able to consistently tell the difference between the two. The AI classifiers also struggled to reliably detect the AI-generated texts.
The researchers also provided a dataset of real Reddit Showerthoughts posts, which could be useful for future research in this area, such as analyzing how large language models process narrative or adapting fake news detection to the era of large language models.
Technical Explanation
The researchers focused on the task of generating short, creative "Showerthought" texts - the kind of insightful or witty observations that people might have during mundane activities. They compared the performance of several different LLM models in this domain:
- GPT-2 and GPT-Neo models that were fine-tuned on Reddit data
- GPT-3.5 used in a zero-shot manner (without fine-tuning)
The researchers evaluated the generated texts on several dimensions of creative quality, such as originality, humor, and insightfulness. They had human evaluators rate the texts and also tested whether humans or fine-tuned RoBERTa classifiers could reliably distinguish the AI-generated texts from human-written ones.
The results showed that the human evaluators rated the LLM-generated texts slightly lower on average compared to the human-written texts. However, the humans were not able to consistently tell the difference between the two, even when explicitly asked to do so. The RoBERTa classifiers also struggled to reliably detect the AI-generated texts, suggesting that the models were quite effective at imitating human writing style.
The researchers also provide a dataset of real Reddit Showerthoughts posts, which could be useful for further research, such as developing generalized strategies to decipher textual authenticity or characterizing the creative process of humans versus large language models.
Critical Analysis
The researchers acknowledge several limitations of their study. First, they only evaluated the LLM-generated texts on a specific type of short, creative writing (Showerthoughts), so the results may not generalize to other domains or longer-form content. Additionally, the human evaluation was limited to ratings on specific dimensions, and the researchers did not investigate more nuanced ways that humans might be able to detect AI-generated texts.
Another potential issue is that the fine-tuning and zero-shot approaches used for the different LLMs may not be directly comparable, as they involve different levels of model customization and training data. It would be interesting to see how the models perform under more standardized conditions.
Finally, the researchers do not discuss the potential societal implications of their findings, such as the risks of AI-generated content being used to spread misinformation or manipulate public discourse. Further research is needed to understand the broader implications of these capabilities.
Overall, this study provides valuable insights into the current state of LLM-generated creative writing and the challenges of detecting AI-generated content. However, ongoing work is needed to develop more robust detection methods and to thoughtfully consider the ethical and societal implications of these rapidly advancing technologies.
Conclusion
This research explores the ability of large language models (LLMs) to generate short, creative texts that are difficult for humans to distinguish from human-written content. The researchers focused on the domain of "Showerthoughts" - the kind of witty, insightful observations that people might have during everyday activities.
By comparing the performance of different LLM models, including GPT-2, GPT-Neo, and GPT-3.5, the researchers found that the AI-generated texts were rated slightly lower in quality by human evaluators compared to human-written Showerthoughts. However, the humans were unable to reliably detect which texts were AI-generated, and even fine-tuned RoBERTa classifiers struggled to consistently identify the machine-generated content.
These findings have important implications for the current state of large language models and the challenges of detecting AI-generated content. As these technologies continue to advance, it will be crucial to develop more robust detection methods and to carefully consider the societal impacts, such as the potential for AI-generated content to be used to spread misinformation.
The researchers' provision of a dataset of real Reddit Showerthoughts posts is also a valuable contribution that could support further research in this area, such as analyzing how large language models process narrative or adapting fake news detection to the era of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Few-Shot Detection of Machine-Generated Text using Style Representations
Rafael Rivera Soto, Kailin Koch, Aleem Khan, Barry Chen, Marcus Bishop, Nicholas Andrews
0
0
The advent of instruction-tuned language models that convincingly mimic human writing poses a significant risk of abuse. However, such abuse may be counteracted with the ability to detect whether a piece of text was composed by a language model rather than a human author. Some previous approaches to this problem have relied on supervised methods by training on corpora of confirmed human- and machine- written documents. Unfortunately, model under-specification poses an unavoidable challenge for neural network-based detectors, making them brittle in the face of data shifts, such as the release of newer language models producing still more fluent text than the models used to train the detectors. Other approaches require access to the models that may have generated a document in question, which is often impractical. In light of these challenges, we pursue a fundamentally different approach not relying on samples from language models of concern at training time. Instead, we propose to leverage representations of writing style estimated from human-authored text. Indeed, we find that features effective at distinguishing among human authors are also effective at distinguishing human from machine authors, including state-of-the-art large language models like Llama-2, ChatGPT, and GPT-4. Furthermore, given a handful of examples composed by each of several specific language models of interest, our approach affords the ability to predict which model generated a given document. The code and data to reproduce our experiments are available at https://github.com/LLNL/LUAR/tree/main/fewshot_iclr2024.
5/9/2024
🔎
Deepfake Text Detection in the Wild
Yafu Li, Qintong Li, Leyang Cui, Wei Bi, Zhilin Wang, Longyue Wang, Linyi Yang, Shuming Shi, Yue Zhang
0
0
Large language models (LLMs) have achieved human-level text generation, emphasizing the need for effective AI-generated text detection to mitigate risks like the spread of fake news and plagiarism. Existing research has been constrained by evaluating detection methods on specific domains or particular language models. In practical scenarios, however, the detector faces texts from various domains or LLMs without knowing their sources. To this end, we build a comprehensive testbed by gathering texts from diverse human writings and texts generated by different LLMs. Empirical results show challenges in distinguishing machine-generated texts from human-authored ones across various scenarios, especially out-of-distribution. These challenges are due to the decreasing linguistic distinctions between the two sources. Despite challenges, the top-performing detector can identify 86.54% out-of-domain texts generated by a new LLM, indicating the feasibility for application scenarios. We release our resources at https://github.com/yafuly/MAGE.
5/22/2024
Who Writes the Review, Human or AI?
Panagiotis C. Theocharopoulos, Spiros V. Georgakopoulos, Sotiris K. Tasoulis, Vassilis P. Plagianakos
0
0
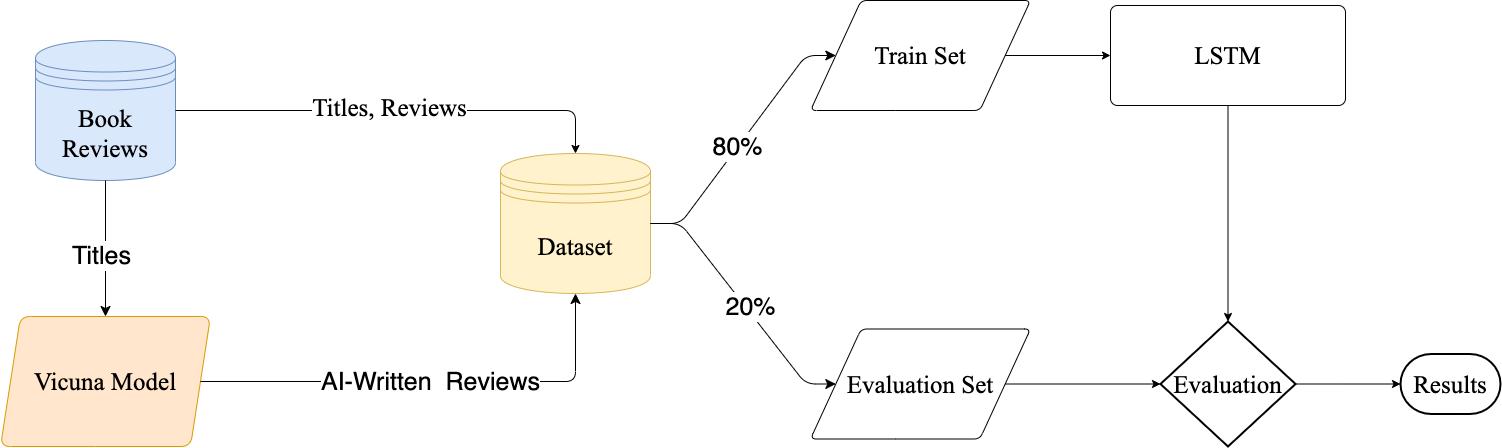
With the increasing use of Artificial Intelligence in Natural Language Processing, concerns have been raised regarding the detection of AI-generated text in various domains. This study aims to investigate this issue by proposing a methodology to accurately distinguish AI-generated and human-written book reviews. Our approach utilizes transfer learning, enabling the model to identify generated text across different topics while improving its ability to detect variations in writing style and vocabulary. To evaluate the effectiveness of the proposed methodology, we developed a dataset consisting of real book reviews and AI-generated reviews using the recently proposed Vicuna open-source language model. The experimental results demonstrate that it is feasible to detect the original source of text, achieving an accuracy rate of 96.86%. Our efforts are oriented toward the exploration of the capabilities and limitations of Large Language Models in the context of text identification. Expanding our knowledge in these aspects will be valuable for effectively navigating similar models in the future and ensuring the integrity and authenticity of human-generated content.
5/31/2024
🔗
Human-interpretable clustering of short-text using large language models
Justin K. Miller, Tristram J. Alexander
0
0
Large language models have seen extraordinary growth in popularity due to their human-like content generation capabilities. We show that these models can also be used to successfully cluster human-generated content, with success defined through the measures of distinctiveness and interpretability. This success is validated by both human reviewers and ChatGPT, providing an automated means to close the 'validation gap' that has challenged short-text clustering. Comparing the machine and human approaches we identify the biases inherent in each, and question the reliance on human-coding as the 'gold standard'. We apply our methodology to Twitter bios and find characteristic ways humans describe themselves, agreeing well with prior specialist work, but with interesting differences characteristic of the medium used to express identity.
5/14/2024