FI-CBL: A Probabilistic Method for Concept-Based Learning with Expert Rules

0

Sign in to get full access
Overview
• This paper presents a new approach called FI-CBL (Fused Inference Concept-Based Learning) that combines expert rules with probabilistic machine learning to enable concept-based learning.
• FI-CBL aims to leverage expert domain knowledge in the form of rules to guide and improve the learning process, leading to more interpretable and reliable models.
Plain English Explanation
• Imagine you're trying to build an AI system to diagnose medical conditions. You could try to train the system on a large dataset of patient records, but it might be difficult for the AI to understand the underlying reasons for the diagnoses.
• Instead, FI-CBL allows you to incorporate expert knowledge, such as medical guidelines or decision rules, into the learning process. This helps the AI system better understand the key concepts and reasoning behind the diagnoses, making the results more interpretable and trustworthy.
• The key idea is to fuse the expert rules with probabilistic machine learning techniques. This allows the AI to learn from the data while also considering the expert knowledge, resulting in models that are both accurate and transparent.
Technical Explanation
• FI-CBL combines two main components: a set of expert-defined rules and a probabilistic machine learning model.
• The expert rules capture domain-specific knowledge, such as the relationships between symptoms, risk factors, and diagnoses. These rules are used to guide the learning process and constrain the model's predictions.
• The probabilistic machine learning model, on the other hand, learns from the available data to capture patterns and associations that may not be fully captured by the expert rules. The model is trained to balance the expert knowledge and the insights from the data.
• The authors demonstrate the effectiveness of FI-CBL on several real-world tasks, including disease diagnosis and product recommendation. They show that FI-CBL can outperform traditional machine learning approaches in terms of both accuracy and interpretability.
Critical Analysis
• One potential limitation of FI-CBL is that it relies on the availability of high-quality expert rules, which may not always be easy to obtain or formalize. The effectiveness of the approach may be sensitive to the quality and completeness of the expert knowledge.
• Additionally, the authors note that the computational complexity of FI-CBL can be higher than some other machine learning methods, which may be a consideration for real-time or resource-constrained applications.
• It would be interesting to see how FI-CBL compares to other concept-based learning approaches, such as Coarse-to-Fine Concept Bottleneck Models, Conceptual Learning via Embedding Approximations, or Stochastic Concept Bottleneck Models, in terms of performance, interpretability, and ease of use.
Conclusion
• FI-CBL provides a promising approach for combining expert knowledge and probabilistic machine learning to enable more interpretable and reliable concept-based learning.
• By leveraging expert rules to guide the learning process, FI-CBL can lead to models that are both accurate and transparent, which is particularly important in high-stakes domains like healthcare or finance.
• The authors have demonstrated the effectiveness of FI-CBL on several real-world tasks, and the approach has the potential to be a valuable tool in the growing field of interpretable and explainable AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FI-CBL: A Probabilistic Method for Concept-Based Learning with Expert Rules
Lev V. Utkin, Andrei V. Konstantinov, Stanislav R. Kirpichenko
A method for solving concept-based learning (CBL) problem is proposed. The main idea behind the method is to divide each concept-annotated image into patches, to transform the patches into embeddings by using an autoencoder, and to cluster the embeddings assuming that each cluster will mainly contain embeddings of patches with certain concepts. To find concepts of a new image, the method implements the frequentist inference by computing prior and posterior probabilities of concepts based on rates of patches from images with certain values of the concepts. Therefore, the proposed method is called the Frequentist Inference CBL (FI-CBL). FI-CBL allows us to incorporate the expert rules in the form of logic functions into the inference procedure. An idea behind the incorporation is to update prior and conditional probabilities of concepts to satisfy the rules. The method is transparent because it has an explicit sequence of probabilistic calculations and a clear frequency interpretation. Numerical experiments show that FI-CBL outperforms the concept bottleneck model in cases when the number of training data is small. The code of proposed algorithms is publicly available.
Read more7/1/2024
🌿
0
Coarse-to-Fine Concept Bottleneck Models
Konstantinos P. Panousis, Dino Ienco, Diego Marcos
Deep learning algorithms have recently gained significant attention due to their impressive performance. However, their high complexity and un-interpretable mode of operation hinders their confident deployment in real-world safety-critical tasks. This work targets ante hoc interpretability, and specifically Concept Bottleneck Models (CBMs). Our goal is to design a framework that admits a highly interpretable decision making process with respect to human understandable concepts, on two levels of granularity. To this end, we propose a novel two-level concept discovery formulation leveraging: (i) recent advances in vision-language models, and (ii) an innovative formulation for coarse-to-fine concept selection via data-driven and sparsity-inducing Bayesian arguments. Within this framework, concept information does not solely rely on the similarity between the whole image and general unstructured concepts; instead, we introduce the notion of concept hierarchy to uncover and exploit more granular concept information residing in patch-specific regions of the image scene. As we experimentally show, the proposed construction not only outperforms recent CBM approaches, but also yields a principled framework towards interpetability.
Read more6/28/2024

0
Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery
Sukrut Rao, Sweta Mahajan, Moritz Bohle, Bernt Schiele
Concept Bottleneck Models (CBMs) have recently been proposed to address the 'black-box' problem of deep neural networks, by first mapping images to a human-understandable concept space and then linearly combining concepts for classification. Such models typically require first coming up with a set of concepts relevant to the task and then aligning the representations of a feature extractor to map to these concepts. However, even with powerful foundational feature extractors like CLIP, there are no guarantees that the specified concepts are detectable. In this work, we leverage recent advances in mechanistic interpretability and propose a novel CBM approach -- called Discover-then-Name-CBM (DN-CBM) -- that inverts the typical paradigm: instead of pre-selecting concepts based on the downstream classification task, we use sparse autoencoders to first discover concepts learnt by the model, and then name them and train linear probes for classification. Our concept extraction strategy is efficient, since it is agnostic to the downstream task, and uses concepts already known to the model. We perform a comprehensive evaluation across multiple datasets and CLIP architectures and show that our method yields semantically meaningful concepts, assigns appropriate names to them that make them easy to interpret, and yields performant and interpretable CBMs. Code available at https://github.com/neuroexplicit-saar/discover-then-name.
Read more8/13/2024
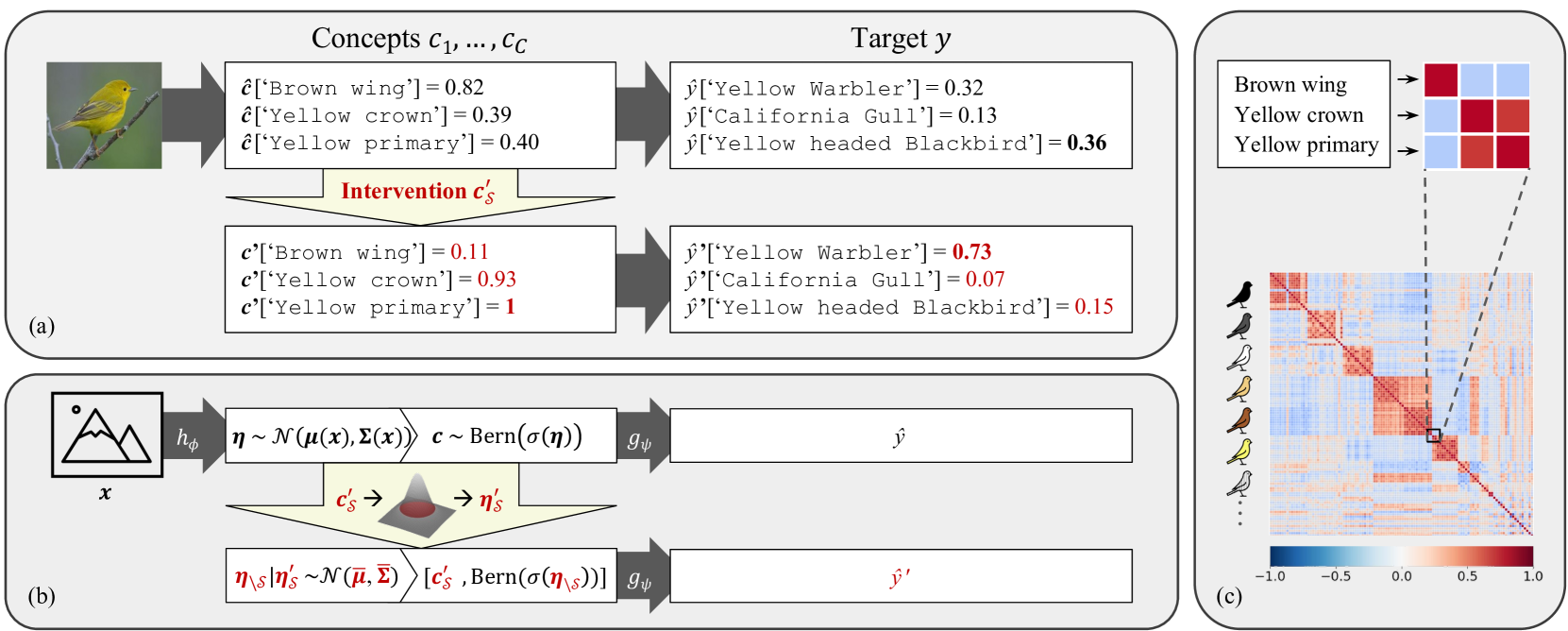
0
Stochastic Concept Bottleneck Models
Moritz Vandenhirtz, Sonia Laguna, Riv{c}ards Marcinkeviv{c}s, Julia E. Vogt
Concept Bottleneck Models (CBMs) have emerged as a promising interpretable method whose final prediction is based on intermediate, human-understandable concepts rather than the raw input. Through time-consuming manual interventions, a user can correct wrongly predicted concept values to enhance the model's downstream performance. We propose Stochastic Concept Bottleneck Models (SCBMs), a novel approach that models concept dependencies. In SCBMs, a single-concept intervention affects all correlated concepts, thereby improving intervention effectiveness. Unlike previous approaches that model the concept relations via an autoregressive structure, we introduce an explicit, distributional parameterization that allows SCBMs to retain the CBMs' efficient training and inference procedure. Additionally, we leverage the parameterization to derive an effective intervention strategy based on the confidence region. We show empirically on synthetic tabular and natural image datasets that our approach improves intervention effectiveness significantly. Notably, we showcase the versatility and usability of SCBMs by examining a setting with CLIP-inferred concepts, alleviating the need for manual concept annotations.
Read more6/28/2024