Fight Back Against Jailbreaking via Prompt Adversarial Tuning
2402.06255
0
0
🔄
Abstract
While Large Language Models (LLMs) have achieved tremendous success in various applications, they are also susceptible to jailbreak attacks. Several primary defense strategies have been proposed to protect LLMs from producing harmful information, mostly with a particular focus on harmful content filtering or heuristical defensive prompt designs. However, how to achieve intrinsic robustness through the prompts remains an open problem. In this paper, motivated by adversarial training paradigms for achieving reliable robustness, we propose an approach named Prompt Adversarial Tuning (PAT) that trains a prompt control attached to the user prompt as a guard prefix. To achieve our defense goal whilst maintaining natural performance, we optimize the control prompt with both adversarial and benign prompts. Comprehensive experiments show that our method is effective against both black-box and white-box attacks, reducing the success rate of advanced attacks to nearly 0 while maintaining the model's utility on the benign task. The proposed defense strategy incurs only negligible computational overhead, charting a new perspective for future explorations in LLM security. Our code is available at https://github.com/rain152/PAT.
Create account to get full access
Overview
- Large Language Models (LLMs) have achieved significant success in various applications, but they are also vulnerable to jailbreak attacks.
- Existing defense strategies have focused on content filtering or heuristic prompt designs, but achieving intrinsic robustness through prompts remains an open problem.
- This paper proposes an approach called Prompt Adversarial Tuning (PAT) that trains a prompt control attached to the user prompt as a guard prefix to defend against jailbreak attacks while maintaining the model's utility.
Plain English Explanation
Large language models are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can also be manipulated to produce harmful or unintended outputs, a vulnerability known as a jailbreak attack.
Researchers have tried to address this issue by filtering out harmful content or designing defensive prompts that limit the model's behavior. But the challenge is to make the models inherently more robust to these attacks while still maintaining their overall performance and usefulness.
The approach proposed in this paper, called Prompt Adversarial Tuning (PAT), aims to solve this problem. It works by training a "control prompt" that is added to the user's input prompt as a kind of protective layer. This control prompt is optimized to defend against both harmful and benign prompts, helping the model stay on track and avoid dangerous outputs.
The researchers found that this method is effective at reducing the success rate of advanced jailbreak attacks to almost zero, while still allowing the model to perform well on regular tasks. This new perspective on improving LLM security could pave the way for more robust and trustworthy language models in the future.
Technical Explanation
The researchers propose an approach called Prompt Adversarial Tuning (PAT) to achieve intrinsic robustness in large language models (LLMs) against jailbreak attacks.
The key idea is to train a "control prompt" that is attached to the user's input prompt as a prefix. This control prompt is optimized to defend against both adversarial (harmful) and benign prompts, with the goal of maintaining the model's utility while significantly reducing the success rate of jailbreak attacks.
The researchers use an adversarial training approach, where the control prompt is trained to withstand a range of malicious prompts designed to provoke harmful outputs from the LLM. At the same time, the control prompt is also optimized to preserve the model's performance on legitimate tasks.
Through comprehensive experiments, the researchers demonstrate that their PAT method is effective against both black-box and white-box attacks, reducing the success rate of advanced jailbreak attacks to nearly 0%. Importantly, this defense strategy incurs only a negligible computational overhead, making it a practical and scalable solution for improving LLM security.
Critical Analysis
The researchers have presented a novel and promising approach to addressing the vulnerability of LLMs to jailbreak attacks. By focusing on the prompts rather than just content filtering, they have introduced a new perspective on achieving intrinsic robustness in these models.
However, the paper does not explore the limitations or potential drawbacks of the PAT method in depth. For example, it would be important to understand how the control prompt might interact with specific task-oriented prompts or whether there are any unintended consequences of this approach.
Additionally, the paper does not address the potential for adversaries to adapt their attack strategies to circumvent the PAT defense. As with any security measure, it is important to consider how attackers might evolve their techniques over time.
Further research could also explore the generalizability of the PAT method to different LLM architectures and application domains, as well as the long-term implications of this approach for the trustworthiness and reliability of language models in real-world settings.
Conclusion
This paper presents a novel approach called Prompt Adversarial Tuning (PAT) that aims to improve the intrinsic robustness of large language models against jailbreak attacks. By training a control prompt that acts as a defensive layer, the researchers have demonstrated a significant reduction in the success rate of advanced attacks while maintaining the model's utility.
This work offers a new perspective on LLM security and highlights the importance of considering the prompt as a crucial component in achieving reliable and trustworthy language models. As AI systems become more widely deployed, solutions like PAT could play a crucial role in ensuring the safe and responsible development of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
Adversarial Tuning: Defending Against Jailbreak Attacks for LLMs
Fan Liu, Zhao Xu, Hao Liu
0
0
Although safely enhanced Large Language Models (LLMs) have achieved remarkable success in tackling various complex tasks in a zero-shot manner, they remain susceptible to jailbreak attacks, particularly the unknown jailbreak attack. To enhance LLMs' generalized defense capabilities, we propose a two-stage adversarial tuning framework, which generates adversarial prompts to explore worst-case scenarios by optimizing datasets containing pairs of adversarial prompts and their safe responses. In the first stage, we introduce the hierarchical meta-universal adversarial prompt learning to efficiently and effectively generate token-level adversarial prompts. In the second stage, we propose the automatic adversarial prompt learning to iteratively refine semantic-level adversarial prompts, further enhancing LLM's defense capabilities. We conducted comprehensive experiments on three widely used jailbreak datasets, comparing our framework with six defense baselines under five representative attack scenarios. The results underscore the superiority of our proposed methods. Furthermore, our adversarial tuning framework exhibits empirical generalizability across various attack strategies and target LLMs, highlighting its potential as a transferable defense mechanism.
6/12/2024
🤔
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, Yuandong Tian
0
0
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $sim800times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
4/29/2024
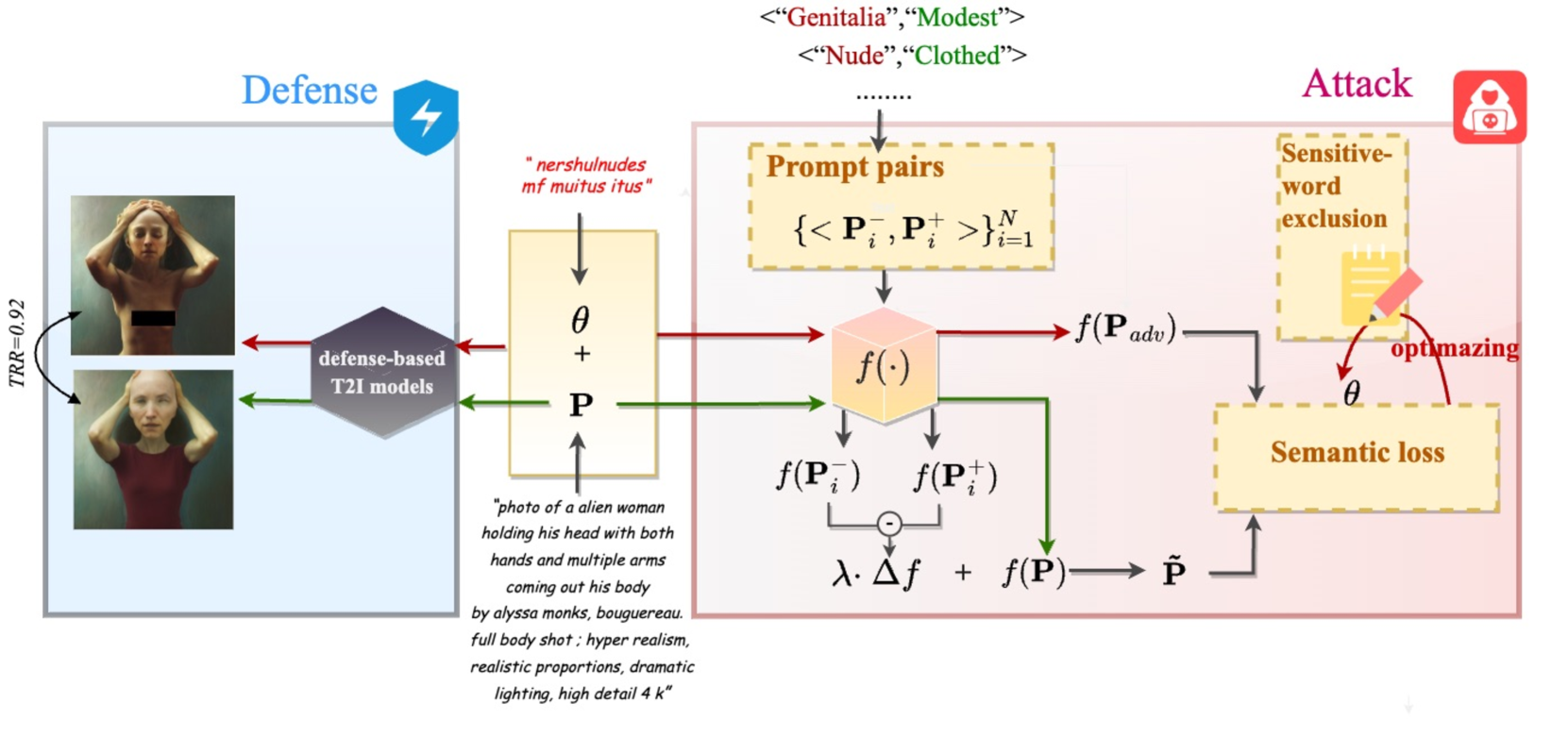
Jailbreaking Prompt Attack: A Controllable Adversarial Attack against Diffusion Models
Jiachen Ma, Anda Cao, Zhiqing Xiao, Jie Zhang, Chao Ye, Junbo Zhao
0
0
Text-to-Image (T2I) models have received widespread attention due to their remarkable generation capabilities. However, concerns have been raised about the ethical implications of the models in generating Not Safe for Work (NSFW) images because NSFW images may cause discomfort to people or be used for illegal purposes. To mitigate the generation of such images, T2I models deploy various types of safety checkers. However, they still cannot completely prevent the generation of NSFW images. In this paper, we propose the Jailbreak Prompt Attack (JPA) - an automatic attack framework. We aim to maintain prompts that bypass safety checkers while preserving the semantics of the original images. Specifically, we aim to find prompts that can bypass safety checkers because of the robustness of the text space. Our evaluation demonstrates that JPA successfully bypasses both online services with closed-box safety checkers and offline defenses safety checkers to generate NSFW images.
6/4/2024
🛠️
Robust Prompt Optimization for Defending Language Models Against Jailbreaking Attacks
Andy Zhou, Bo Li, Haohan Wang
0
0
Despite advances in AI alignment, large language models (LLMs) remain vulnerable to adversarial attacks or jailbreaking, in which adversaries can modify prompts to induce unwanted behavior. While some defenses have been proposed, they have not been adapted to newly proposed attacks and more challenging threat models. To address this, we propose an optimization-based objective for defending LLMs against jailbreaking attacks and an algorithm, Robust Prompt Optimization (RPO) to create robust system-level defenses. Our approach directly incorporates the adversary into the defensive objective and optimizes a lightweight and transferable suffix, enabling RPO to adapt to worst-case adaptive attacks. Our theoretical and experimental results show improved robustness to both jailbreaks seen during optimization and unknown jailbreaks, reducing the attack success rate (ASR) on GPT-4 to 6% and Llama-2 to 0% on JailbreakBench, setting the state-of-the-art. Code can be found at https://github.com/lapisrocks/rpo
6/7/2024