Finding Blind Spots in Evaluator LLMs with Interpretable Checklists

0
Sign in to get full access
Overview
- This paper investigates the blind spots of large language models (LLMs) used as evaluators, and proposes the use of interpretable checklists to identify these issues.
- LLMs are increasingly being used to evaluate the outputs of other AI systems, but their own biases and limitations can lead to inconsistent or unreliable evaluations.
- The researchers develop a framework for creating interpretable checklists that can uncover the blind spots of evaluator LLMs, allowing for more robust and transparent model evaluation.
Plain English Explanation
Large language models (LLMs) like GPT-3 are very good at understanding and generating human-like text. But these models can also have hidden biases and weaknesses that aren't always obvious. This paper looks at using LLMs to evaluate the outputs of other AI systems, and how we can find the "blind spots" in these evaluator LLMs.
The key idea is to use interpretable checklists - a set of targeted questions or prompts that can reveal the limitations of an evaluator LLM. For example, a checklist might ask the LLM to analyze text with certain political views, or to handle tricky grammatical constructions. By looking at how the LLM responds to these targeted prompts, researchers can uncover areas where the evaluator model is making mistakes or struggling.
This allows for more robust and transparent model evaluation. Instead of just relying on the LLM's overall score or judgement, we can dig deeper and understand the specific reasons why it may be giving unreliable or biased evaluations in certain cases. This is an important step towards building AI systems that are more reliable and trustworthy.
Technical Explanation
The paper proposes a framework for creating interpretable checklists to uncover the blind spots of LLMs used as evaluators. The key steps are:
-
Identify Potential Blind Spots: The researchers first identify potential areas where the evaluator LLM may struggle, such as handling complex linguistic structures, evaluating sensitive topics, or dealing with noisy or adversarial inputs.
-
Develop Interpretable Checklists: Based on the identified blind spots, they create a set of targeted prompts or questions that can probe the LLM's capabilities in those areas. These checklists are designed to be interpretable, meaning the responses can be easily analyzed to understand the model's reasoning.
-
Evaluate the Evaluator: The LLM evaluator is tested on the interpretable checklists, and its performance is analyzed to uncover blind spots. This could include looking at accuracy, consistency, or the model's own confidence in its judgements.
The paper demonstrates this approach on several evaluator LLMs, including GPT-3 and InstructGPT. The results show that the checklists can effectively identify areas where the evaluator models struggle, such as handling negation, irony, or sensitive political topics.
Critical Analysis
The paper provides a valuable framework for assessing the reliability and robustness of LLMs used as evaluators. By uncovering their blind spots through interpretable checklists, it helps address concerns around the factual consistency and reliability of LLMs.
However, the paper also acknowledges some limitations. The checklists themselves may not cover all possible blind spots, and there could be blind spots in the checklist creation process. Additionally, the approach relies on the interpretability of the checklists, which may be challenging to achieve for more complex LLM behaviors.
Further research could explore ways to automate the checklist creation process, or to develop more comprehensive evaluation frameworks that combine checklists with other techniques like open-ended factuality evaluation. Nonetheless, this paper represents an important step towards building more trustworthy and transparent AI evaluation systems.
Conclusion
This paper presents a framework for using interpretable checklists to uncover the blind spots of LLMs used as evaluators. By probing the models with targeted prompts, researchers can gain a better understanding of the LLMs' limitations and biases, allowing for more robust and reliable model evaluation.
As LLMs become more widely used in critical applications, it is crucial to develop tools and techniques to assess their reliability and trustworthiness. The approach described in this paper is a valuable contribution towards this goal, and could have significant implications for the development of safer and more transparent AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Finding Blind Spots in Evaluator LLMs with Interpretable Checklists
Sumanth Doddapaneni, Mohammed Safi Ur Rahman Khan, Sshubam Verma, Mitesh M. Khapra
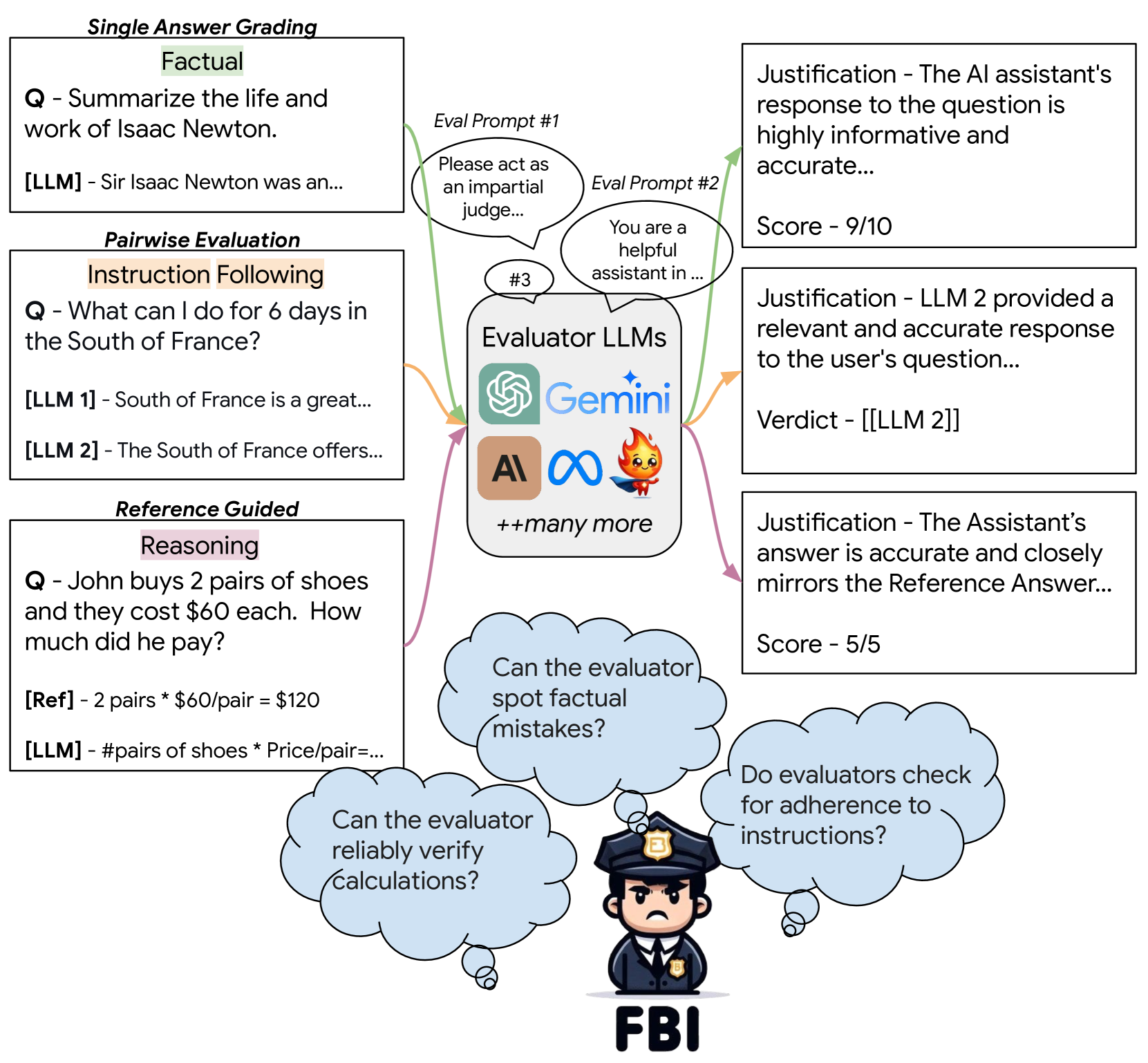
Large Language Models (LLMs) are increasingly relied upon to evaluate text outputs of other LLMs, thereby influencing leaderboards and development decisions. However, concerns persist over the accuracy of these assessments and the potential for misleading conclusions. In this work, we investigate the effectiveness of LLMs as evaluators for text generation tasks. We propose FBI, a novel framework designed to examine the proficiency of Evaluator LLMs in assessing four critical abilities in other LLMs: factual accuracy, instruction following, coherence in long-form writing, and reasoning proficiency. By introducing targeted perturbations in answers generated by LLMs, that clearly impact one of these key capabilities, we test whether an Evaluator LLM can detect these quality drops. By creating a total of 2400 perturbed answers covering 22 perturbation categories, we conduct a comprehensive study using different evaluation strategies on five prominent LLMs commonly used as evaluators in the literature. Our findings reveal significant shortcomings in current Evaluator LLMs, which failed to identify quality drops in over 50% of cases on average. Single-answer and pairwise evaluations demonstrated notable limitations, whereas reference-based evaluations showed comparatively better performance. These results underscore the unreliable nature of current Evaluator LLMs and advocate for cautious implementation in practical applications. Code and data are available at https://github.com/AI4Bharat/FBI.
Read more6/21/2024
0
Large Language Models are Inconsistent and Biased Evaluators
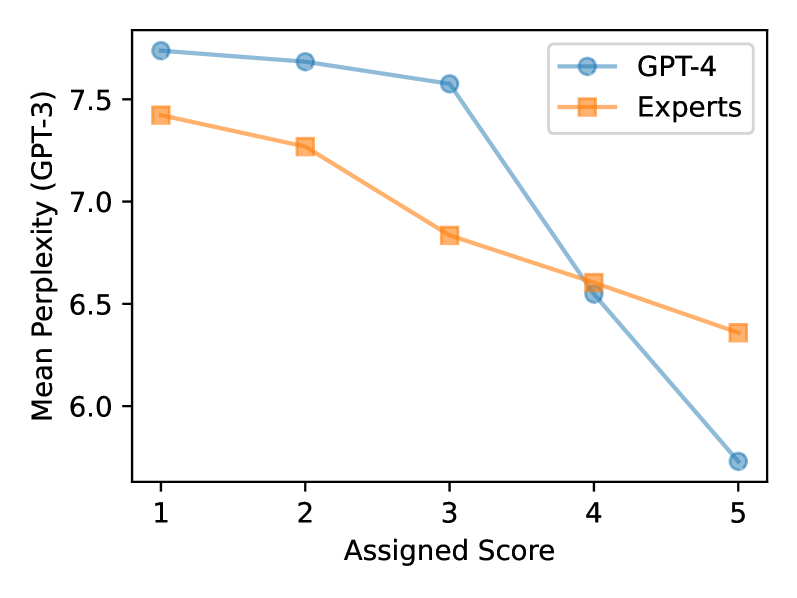
Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
Read more5/6/2024
📶
0
Enhancing Trust in LLMs: Algorithms for Comparing and Interpreting LLMs
Nik Bear Brown
This paper surveys evaluation techniques to enhance the trustworthiness and understanding of Large Language Models (LLMs). As reliance on LLMs grows, ensuring their reliability, fairness, and transparency is crucial. We explore algorithmic methods and metrics to assess LLM performance, identify weaknesses, and guide development towards more trustworthy applications. Key evaluation metrics include Perplexity Measurement, NLP metrics (BLEU, ROUGE, METEOR, BERTScore, GLEU, Word Error Rate, Character Error Rate), Zero-Shot and Few-Shot Learning Performance, Transfer Learning Evaluation, Adversarial Testing, and Fairness and Bias Evaluation. We introduce innovative approaches like LLMMaps for stratified evaluation, Benchmarking and Leaderboards for competitive assessment, Stratified Analysis for in-depth understanding, Visualization of Blooms Taxonomy for cognitive level accuracy distribution, Hallucination Score for quantifying inaccuracies, Knowledge Stratification Strategy for hierarchical analysis, and Machine Learning Models for Hierarchy Generation. Human Evaluation is highlighted for capturing nuances that automated metrics may miss. These techniques form a framework for evaluating LLMs, aiming to enhance transparency, guide development, and establish user trust. Future papers will describe metric visualization and demonstrate each approach on practical examples.
Read more6/5/2024
🎯
0
F-Eval: Assessing Fundamental Abilities with Refined Evaluation Methods
Yu Sun, Keyu Chen, Shujie Wang, Peiji Li, Qipeng Guo, Hang Yan, Xipeng Qiu, Xuanjing Huang, Dahua Lin
Large language models (LLMs) garner significant attention for their unprecedented performance, leading to an increasing number of researches evaluating LLMs. However, these evaluation benchmarks are limited to assessing the instruction-following capabilities, overlooking the fundamental abilities that emerge during the pre-training stage. Previous subjective evaluation methods mainly reply on scoring by API models. However, in the absence of references, large models have shown limited ability to discern subtle differences. To bridge the gap, we propose F-Eval, a bilingual evaluation benchmark to evaluate the fundamental abilities, including expression, commonsense and logic. The tasks in F-Eval include multi-choice objective tasks, open-ended objective tasks, reference-based subjective tasks and reference-free subjective tasks. For reference-free subjective tasks, we devise new evaluation methods, serving as alternatives to scoring by API models. We conduct evaluations on 13 advanced LLMs. Results show that our evaluation methods show higher correlation coefficients and larger distinction than other evaluators. Additionally, we discuss the influence of different model sizes, dimensions, and normalization methods. We anticipate that F-Eval will facilitate the study of LLMs' fundamental abilities.
Read more8/21/2024