Linguistic Structure from a Bottleneck on Sequential Information Processing

0

Sign in to get full access
Overview
- This paper explores how a bottleneck in the sequential processing of information can lead to the emergence of linguistic structure.
- The researchers use a computational model to investigate how constraints on information processing can give rise to hierarchical and compositional language-like structures.
- The findings suggest that the way humans process information sequentially may be a key driver in the development of language and its characteristic properties.
Plain English Explanation
The paper looks at how the way our brains process information in a step-by-step fashion can shape the structure of language. The researchers used a computer simulation to model this process and see how certain constraints on how information is processed could result in language-like structures emerging.
The key idea is that the fact that we can only take in and process information one piece at a time, rather than all at once, may be an important factor in why human language has the properties it does - like being hierarchical (with words, phrases, and sentences) and composed of smaller building blocks that can be combined in different ways.
The researchers found that by imposing this type of sequential processing constraint in their model, they were able to see the development of language-like structures, suggesting this could be a crucial reason why human language has the structure it does. This provides insights into the origins and evolution of language as a cognitive capability.
Technical Explanation
The paper presents a computational model that explores how a bottleneck on the sequential processing of information can lead to the emergence of linguistic structure, such as hierarchical and compositional properties.
The model consists of an agent that observes a sequence of input symbols and tries to compress this information into a fixed-size "bottleneck" representation. Through this compression process, the agent must discover efficient ways to represent the sequential structure of the input, giving rise to language-like properties.
The researchers analyze the information-theoretic properties of the agent's internal representations and find that they exhibit systematic expression of independent components, akin to the compositionality observed in natural languages. They also observe the development of hierarchical structure, with higher-level units composed of lower-level building blocks.
These findings suggest that the sequential nature of human information processing, and the constraints this imposes, may be a key driver in the development of the structural properties of language, as described in related work and other studies.
Critical Analysis
The paper provides a compelling computational model for how the constraints of sequential information processing could lead to the emergence of linguistic structure. However, the model is highly abstracted and simplified, and it remains to be seen how well these insights translate to the complexity of natural language acquisition and use.
Additionally, the paper does not address other important factors that likely play a role in the development of language, such as social interaction, embodied cognition, and the biological and neural mechanisms underlying language processing. Further research is needed to better understand the interplay of these various components in the origins and evolution of language.
Conclusion
This paper presents a novel computational model that suggests the sequential nature of human information processing may be a key factor in the emergence of the structural properties of language, such as hierarchy and compositionality. By imposing constraints on how information is processed, the model is able to capture the development of language-like structures, providing insights into the cognitive foundations of language.
While the model is a simplification of the complex reality of language, the findings highlight the importance of considering the role of information processing constraints in shaping the evolution and structure of human language. This work contributes to our understanding of the origins and cognitive basis of this fundamental human capability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Linguistic Structure from a Bottleneck on Sequential Information Processing
Richard Futrell, Michael Hahn
Human language is a unique form of communication in the natural world, distinguished by its structured nature. Most fundamentally, it is systematic, meaning that signals can be broken down into component parts that are individually meaningful -- roughly, words -- which are combined in a regular way to form sentences. Furthermore, the way in which these parts are combined maintains a kind of locality: words are usually concatenated together, and they form contiguous phrases, keeping related parts of sentences close to each other. We address the challenge of understanding how these basic properties of language arise from broader principles of efficient communication under information processing constraints. Here we show that natural-language-like systematicity arises from minimization of excess entropy, a measure of statistical complexity that represents the minimum amount of information necessary for predicting the future of a sequence based on its past. In simulations, we show that codes that minimize excess entropy factorize their source distributions into approximately independent components, and then express those components systematically and locally. Next, in a series of massively cross-linguistic corpus studies, we show that human languages are structured to have low excess entropy at the level of phonology, morphology, syntax, and semantics. Our result suggests that human language performs a sequential generalization of Independent Components Analysis on the statistical distribution over meanings that need to be expressed. It establishes a link between the statistical and algebraic structure of human language, and reinforces the idea that the structure of human language may have evolved to minimize cognitive load while maximizing communicative expressiveness.
Read more5/21/2024
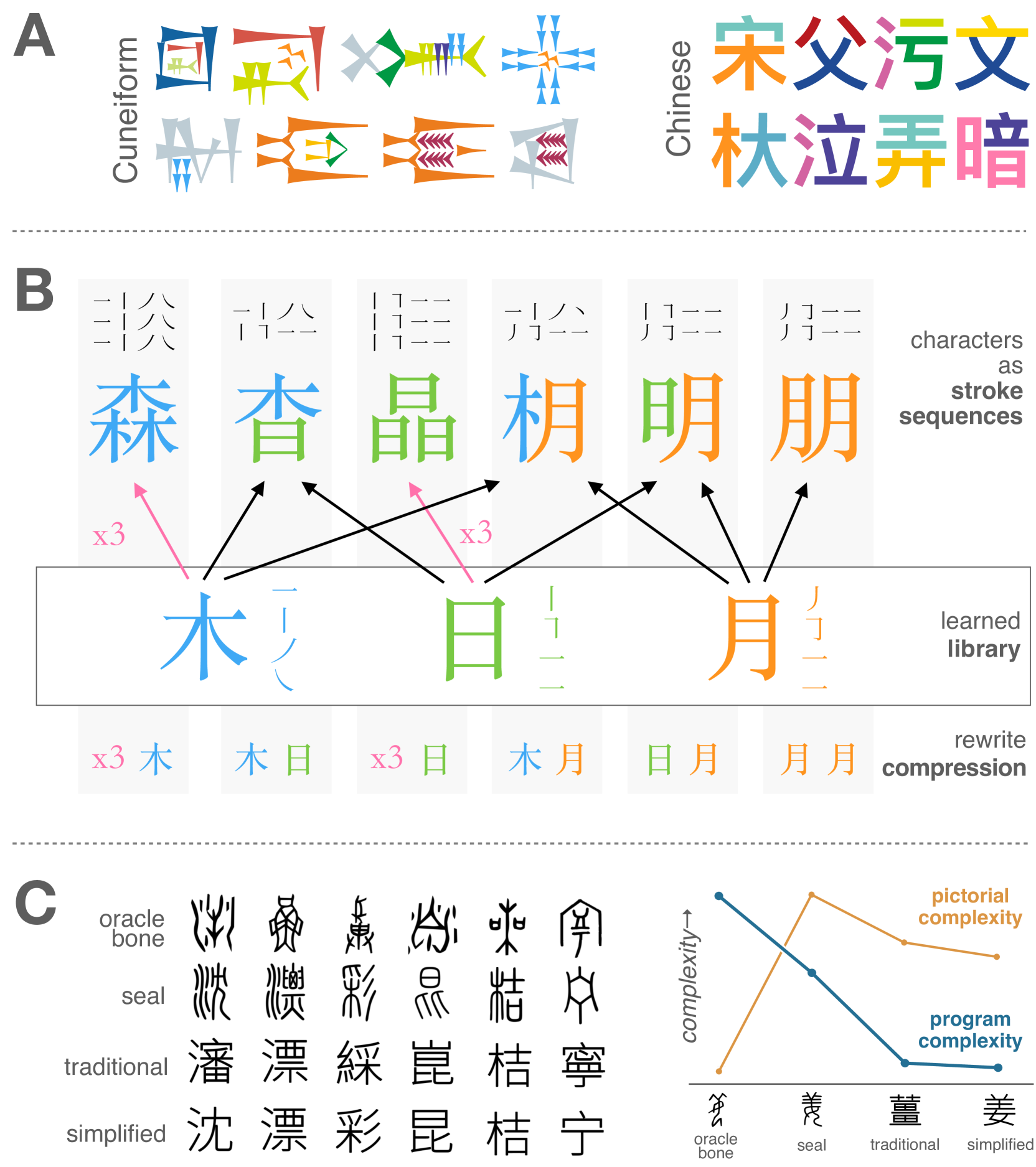
0
Finding structure in logographic writing with library learning
Guangyuan Jiang, Matthias Hofer, Jiayuan Mao, Lionel Wong, Joshua B. Tenenbaum, Roger P. Levy
One hallmark of human language is its combinatoriality -- reusing a relatively small inventory of building blocks to create a far larger inventory of increasingly complex structures. In this paper, we explore the idea that combinatoriality in language reflects a human inductive bias toward representational efficiency in symbol systems. We develop a computational framework for discovering structure in a writing system. Built on top of state-of-the-art library learning and program synthesis techniques, our computational framework discovers known linguistic structures in the Chinese writing system and reveals how the system evolves towards simplification under pressures for representational efficiency. We demonstrate how a library learning approach, utilizing learned abstractions and compression, may help reveal the fundamental computational principles that underlie the creation of combinatorial structures in human cognition, and offer broader insights into the evolution of efficient communication systems.
Read more5/14/2024

0
An information-theoretic model of shallow and deep language comprehension
Jiaxuan Li, Richard Futrell
A large body of work in psycholinguistics has focused on the idea that online language comprehension can be shallow or `good enough': given constraints on time or available computation, comprehenders may form interpretations of their input that are plausible but inaccurate. However, this idea has not yet been linked with formal theories of computation under resource constraints. Here we use information theory to formulate a model of language comprehension as an optimal trade-off between accuracy and processing depth, formalized as bits of information extracted from the input, which increases with processing time. The model provides a measure of processing effort as the change in processing depth, which we link to EEG signals and reading times. We validate our theory against a large-scale dataset of garden path sentence reading times, and EEG experiments featuring N400, P600 and biphasic ERP effects. By quantifying the timecourse of language processing as it proceeds from shallow to deep, our model provides a unified framework to explain behavioral and neural signatures of language comprehension.
Read more5/15/2024
📈
0
Vectoring Languages
Joseph Chen
Recent breakthroughs in large language models (LLM) have stirred up global attention, and the research has been accelerating non-stop since then. Philosophers and psychologists have also been researching the structure of language for decades, but they are having a hard time finding a theory that directly benefits from the breakthroughs of LLMs. In this article, we propose a novel structure of language that reflects well on the mechanisms behind language models and go on to show that this structure is also better at capturing the diverse nature of language compared to previous methods. An analogy of linear algebra is adapted to strengthen the basis of this perspective. We further argue about the difference between this perspective and the design philosophy for current language models. Lastly, we discuss how this perspective can lead us to research directions that may accelerate the improvements of science fastest.
Read more7/17/2024