Fine-grained Hallucination Detection and Mitigation in Long-form Question Answering

0

Sign in to get full access
Overview
• This paper focuses on the problem of hallucination in large language models (LLMs) for long-form question answering tasks.
• Hallucination refers to the generation of factually incorrect or nonsensical information by LLMs, which can be a significant issue in applications where reliable and truthful answers are crucial.
• The researchers propose a fine-grained hallucination detection and mitigation approach to address this problem, aiming to identify and filter out hallucinated content in LLM-generated responses.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes produce information that is factually incorrect or nonsensical, a phenomenon known as "hallucination." This can be a significant problem in applications where reliable and truthful answers are essential, such as question-answering tasks.
To address this issue, the researchers in this paper have developed a new approach that can detect and mitigate hallucinations in LLM-generated responses. Their method involves analyzing the LLM output at a fine-grained level, identifying specific parts of the response that may be hallucinated, and then filtering out or correcting those problematic sections.
By using this fine-grained hallucination detection and mitigation technique, the researchers aim to improve the overall accuracy and trustworthiness of LLM-based question-answering systems, making them more reliable for real-world applications.
Technical Explanation
The paper presents a fine-grained hallucination detection and mitigation approach for long-form question answering with large language models (LLMs). The researchers first develop a hallucination detection model that can identify specific spans within the LLM-generated response that are likely to be hallucinated. This is done by training a classification model to distinguish between hallucinated and non-hallucinated text segments.
To mitigate the hallucinated content, the researchers propose two strategies: a policy-based approach that uses fine-grained knowledge feedback and a faithful fine-tuning method that helps the LLM learn to avoid hallucination. These techniques aim to selectively correct or mask the identified hallucinated segments, while preserving the non-hallucinated parts of the response.
The researchers evaluate their approach on several long-form question answering benchmarks, demonstrating improved performance and reduced hallucination compared to baseline LLM models. Their work contributes to the broader effort to robustly discern reliable answers from large language models and detect and mitigate hallucination in large vision-language models.
Critical Analysis
The paper presents a well-designed and comprehensive approach to addressing the hallucination problem in LLMs for long-form question answering. The fine-grained hallucination detection and mitigation techniques demonstrate promising results, suggesting that this approach could be valuable for real-world applications where reliable and truthful answers are crucial.
However, the researchers acknowledge that their methods may not completely eliminate hallucination, and there is still room for improvement. For example, the hallucination detection model may not always be able to accurately identify all hallucinated content, and the mitigation strategies may not be able to fully correct or mask all instances of hallucination.
Additionally, the paper focuses on long-form question answering, but the hallucination problem is likely to be present in other LLM-based applications as well. Further research may be needed to explore the generalizability of the proposed techniques to a wider range of tasks and domains.
Conclusion
This paper presents a significant contribution to the growing body of work on addressing the hallucination problem in large language models. By developing a fine-grained hallucination detection and mitigation approach, the researchers have made progress towards building more reliable and trustworthy LLM-based systems for long-form question answering and potentially other applications.
The insights and techniques from this research could have far-reaching implications, as the ability to accurately detect and mitigate hallucinations in LLMs is crucial for realizing the full potential of these powerful AI models in real-world settings where truthful and reliable information is of the utmost importance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fine-grained Hallucination Detection and Mitigation in Long-form Question Answering
Rachneet Sachdeva, Yixiao Song, Mohit Iyyer, Iryna Gurevych
Long-form question answering (LFQA) aims to provide thorough and in-depth answers to complex questions, enhancing comprehension. However, such detailed responses are prone to hallucinations and factual inconsistencies, challenging their faithful evaluation. This work introduces HaluQuestQA, the first hallucination dataset with localized error annotations for human-written and model-generated LFQA answers. HaluQuestQA comprises 698 QA pairs with 4.7k span-level error annotations for five different error types by expert annotators, along with preference judgments. Using our collected data, we thoroughly analyze the shortcomings of long-form answers and find that they lack comprehensiveness and provide unhelpful references. We train an automatic feedback model on this dataset that predicts error spans with incomplete information and provides associated explanations. Finally, we propose a prompt-based approach, Error-informed refinement, that uses signals from the learned feedback model to refine generated answers, which we show reduces hallucination and improves answer quality. Furthermore, humans find answers generated by our approach comprehensive and highly prefer them (84%) over the baseline answers.
Read more7/17/2024

0
Fine-grained Hallucination Detection and Editing for Language Models
Abhika Mishra, Akari Asai, Vidhisha Balachandran, Yizhong Wang, Graham Neubig, Yulia Tsvetkov, Hannaneh Hajishirzi
Large language models (LMs) are prone to generate factual errors, which are often called hallucinations. In this paper, we introduce a comprehensive taxonomy of hallucinations and argue that hallucinations manifest in diverse forms, each requiring varying degrees of careful assessments to verify factuality. We propose a novel task of automatic fine-grained hallucination detection and construct a new evaluation benchmark, FavaBench, that includes about one thousand fine-grained human judgments on three LM outputs across various domains. Our analysis reveals that ChatGPT and Llama2-Chat (70B, 7B) exhibit diverse types of hallucinations in the majority of their outputs in information-seeking scenarios. We train FAVA, a retrieval-augmented LM by carefully creating synthetic data to detect and correct fine-grained hallucinations. On our benchmark, our automatic and human evaluations show that FAVA significantly outperforms ChatGPT and GPT-4 on fine-grained hallucination detection, and edits suggested by FAVA improve the factuality of LM-generated text.
Read more8/14/2024

0
New!HALO: Hallucination Analysis and Learning Optimization to Empower LLMs with Retrieval-Augmented Context for Guided Clinical Decision Making
Sumera Anjum, Hanzhi Zhang, Wenjun Zhou, Eun Jin Paek, Xiaopeng Zhao, Yunhe Feng
Large language models (LLMs) have significantly advanced natural language processing tasks, yet they are susceptible to generating inaccurate or unreliable responses, a phenomenon known as hallucination. In critical domains such as health and medicine, these hallucinations can pose serious risks. This paper introduces HALO, a novel framework designed to enhance the accuracy and reliability of medical question-answering (QA) systems by focusing on the detection and mitigation of hallucinations. Our approach generates multiple variations of a given query using LLMs and retrieves relevant information from external open knowledge bases to enrich the context. We utilize maximum marginal relevance scoring to prioritize the retrieved context, which is then provided to LLMs for answer generation, thereby reducing the risk of hallucinations. The integration of LangChain further streamlines this process, resulting in a notable and robust increase in the accuracy of both open-source and commercial LLMs, such as Llama-3.1 (from 44% to 65%) and ChatGPT (from 56% to 70%). This framework underscores the critical importance of addressing hallucinations in medical QA systems, ultimately improving clinical decision-making and patient care. The open-source HALO is available at: https://github.com/ResponsibleAILab/HALO.
Read more9/17/2024
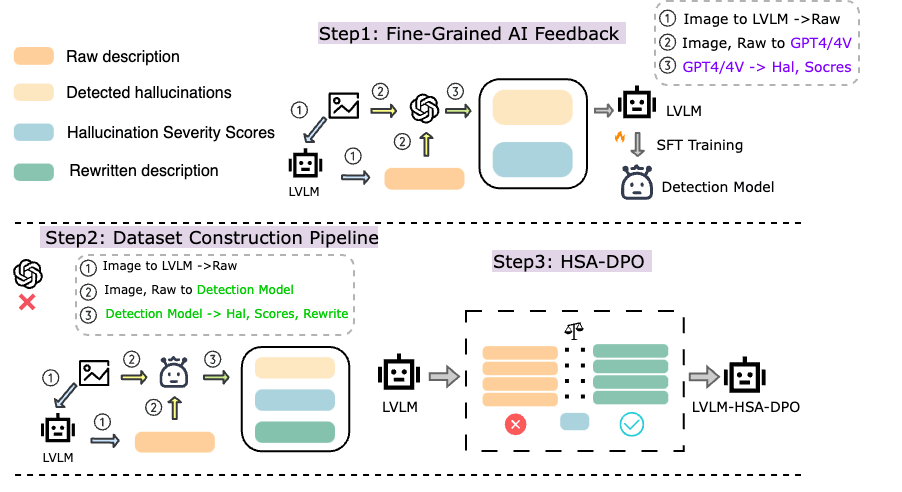
0
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
Read more4/23/2024