Fine-tuning Reinforcement Learning Models is Secretly a Forgetting Mitigation Problem

0
🏅
Sign in to get full access
Overview
- Fine-tuning is a widely used technique that allows transferring pre-trained capabilities to new tasks.
- Applying fine-tuning to reinforcement learning (RL) models remains challenging.
- This work identifies a specific issue that can arise: forgetting of pre-trained capabilities on parts of the state space not visited during fine-tuning.
- The paper shows this problem is common and can be catastrophic, but that standard knowledge retention techniques can mitigate it.
- The authors demonstrate state-of-the-art results on the challenging NetHack environment by addressing this issue.
Plain English Explanation
When training machine learning models, it's often beneficial to start with a model that has already been trained on a large amount of data, a process known as pre-training. This pre-trained model can then be fine-tuned on a specific task, allowing it to quickly learn and perform well on that task.
However, the authors of this paper found that fine-tuning can be particularly challenging for reinforcement learning (RL) models. The issue is that the fine-tuned model can sometimes "forget" the capabilities it had learned during the initial pre-training phase, but only on parts of the problem space that it doesn't encounter during the fine-tuning process.
Imagine a robot that has been pre-trained to navigate a variety of environments. When you try to fine-tune it to perform a specific task in a new environment, the robot may forget how to navigate parts of that new environment that it doesn't explore during the fine-tuning process. As a result, it may not be able to take full advantage of the capabilities it had learned earlier.
The authors show that this "forgetting" problem is quite common and can be severe, dramatically reducing the benefits of pre-training. However, they also found that using standard techniques for retaining knowledge, such as continual learning, can help mitigate this issue.
By addressing this problem, the authors were able to achieve a new state-of-the-art result on the challenging NetHack environment, improving the previous best score by a significant margin. This demonstrates the importance of understanding and addressing such fine-tuning challenges, especially in complex reinforcement learning problems.
Technical Explanation
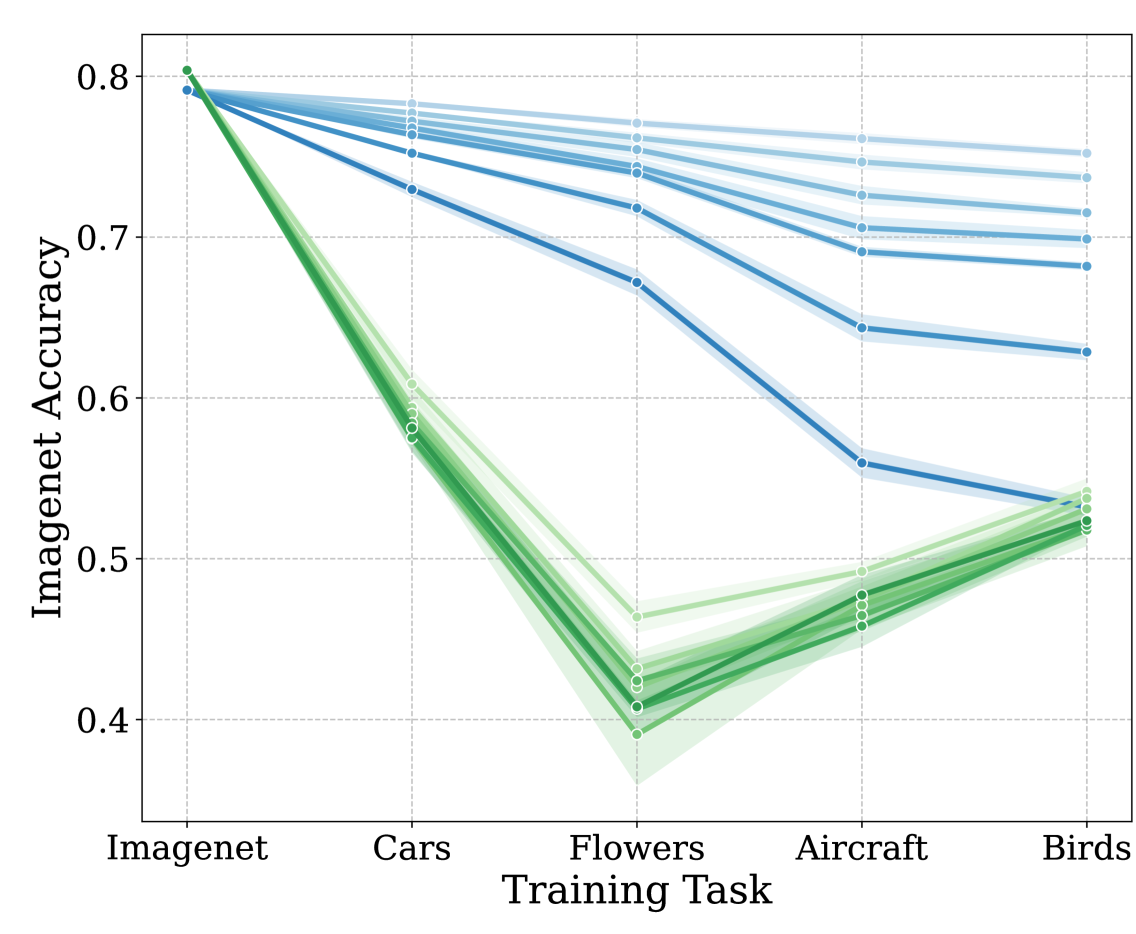
The paper focuses on the problem of forgetting pre-trained capabilities when fine-tuning reinforcement learning (RL) models. The authors hypothesize that this issue arises due to the interplay between actions and observations in the RL setting, where the fine-tuned model may not explore the entire state space of the downstream task, leading to a deterioration of performance on the unvisited regions.
To investigate this, the authors conduct a detailed empirical analysis on the challenging NetHack and Montezuma's Revenge environments. They show that this forgetting problem is indeed common and, in many cases, catastrophic, leading to a significant loss of the anticipated transfer benefits from pre-training.
The authors then explore the use of standard knowledge retention techniques, such as continual learning and parameter-efficient fine-tuning, to mitigate the forgetting problem. Their results demonstrate that these techniques can effectively preserve the pre-trained capabilities and allow the model to take full advantage of the pre-training, leading to state-of-the-art performance on the NetHack environment.
Specifically, in the Human Monk scenario of NetHack, the authors achieve a new state-of-the-art score of over 10,000 points, a significant improvement over the previous best score of 5,000 points.
Critical Analysis
The paper presents a well-designed and thorough empirical analysis of the forgetting problem in fine-tuning RL models. The authors clearly identify the issue, provide a detailed explanation of its causes, and demonstrate its severity across multiple challenging environments.
One potential limitation of the study is the focus on only two specific environments, NetHack and Montezuma's Revenge. While these are well-known benchmark tasks, it would be valuable to see the authors' insights applied to a broader range of RL domains to further validate the generalizability of their findings.
Additionally, while the authors demonstrate the effectiveness of standard knowledge retention techniques in mitigating the forgetting problem, it would be interesting to see if there are any novel, RL-specific approaches that could provide even greater benefits. Half-fine-tuning or other parameter-efficient fine-tuning methods may be worth exploring in this context.
Overall, this paper makes a valuable contribution by shedding light on an important challenge in fine-tuning RL models and providing practical solutions to address it. The authors' findings have the potential to significantly improve the effectiveness of transfer learning in reinforcement learning applications.
Conclusion
This paper identifies a critical issue in fine-tuning reinforcement learning (RL) models: the forgetting of pre-trained capabilities on parts of the state space not visited during the fine-tuning process. Through a detailed empirical analysis, the authors demonstrate that this problem is common and can be catastrophic, severely reducing the benefits of pre-training.
By employing standard knowledge retention techniques, the authors are able to mitigate this forgetting problem and achieve state-of-the-art results on the challenging NetHack environment. This work highlights the importance of addressing fine-tuning challenges, especially in complex RL domains, to fully leverage the power of pre-trained models and advance the field of reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Fine-tuning Reinforcement Learning Models is Secretly a Forgetting Mitigation Problem
Maciej Wo{l}czyk, Bart{l}omiej Cupia{l}, Mateusz Ostaszewski, Micha{l} Bortkiewicz, Micha{l} Zajk{a}c, Razvan Pascanu, {L}ukasz Kuci'nski, Piotr Mi{l}o's
Fine-tuning is a widespread technique that allows practitioners to transfer pre-trained capabilities, as recently showcased by the successful applications of foundation models. However, fine-tuning reinforcement learning (RL) models remains a challenge. This work conceptualizes one specific cause of poor transfer, accentuated in the RL setting by the interplay between actions and observations: forgetting of pre-trained capabilities. Namely, a model deteriorates on the state subspace of the downstream task not visited in the initial phase of fine-tuning, on which the model behaved well due to pre-training. This way, we lose the anticipated transfer benefits. We identify conditions when this problem occurs, showing that it is common and, in many cases, catastrophic. Through a detailed empirical analysis of the challenging NetHack and Montezuma's Revenge environments, we show that standard knowledge retention techniques mitigate the problem and thus allow us to take full advantage of the pre-trained capabilities. In particular, in NetHack, we achieve a new state-of-the-art for neural models, improving the previous best score from $5$K to over $10$K points in the Human Monk scenario.
Read more7/18/2024
🏅
0
Fine-tuning can cripple your foundation model; preserving features may be the solution
Jishnu Mukhoti, Yarin Gal, Philip H. S. Torr, Puneet K. Dokania
Pre-trained foundation models, due to their enormous capacity and exposure to vast amounts of data during pre-training, are known to have learned plenty of real-world concepts. An important step in making these pre-trained models effective on downstream tasks is to fine-tune them on related datasets. While various fine-tuning methods have been devised and have been shown to be highly effective, we observe that a fine-tuned model's ability to recognize concepts on tasks $textit{different}$ from the downstream one is reduced significantly compared to its pre-trained counterpart. This is an undesirable effect of fine-tuning as a substantial amount of resources was used to learn these pre-trained concepts in the first place. We call this phenomenon ''concept forgetting'' and via experiments show that most end-to-end fine-tuning approaches suffer heavily from this side effect. To this end, we propose a simple fix to this problem by designing a new fine-tuning method called $textit{LDIFS}$ (short for $ell_2$ distance in feature space) that, while learning new concepts related to the downstream task, allows a model to preserve its pre-trained knowledge as well. Through extensive experiments on 10 fine-tuning tasks we show that $textit{LDIFS}$ significantly reduces concept forgetting. Additionally, we show that LDIFS is highly effective in performing continual fine-tuning on a sequence of tasks as well, in comparison with both fine-tuning as well as continual learning baselines.
Read more7/2/2024
0
An Empirical Analysis of Forgetting in Pre-trained Models with Incremental Low-Rank Updates
Albin Soutif--Cormerais, Simone Magistri, Joost van de Weijer, Andew D. Bagdanov
Broad, open source availability of large pretrained foundation models on the internet through platforms such as HuggingFace has taken the world of practical deep learning by storm. A classical pipeline for neural network training now typically consists of finetuning these pretrained network on a small target dataset instead of training from scratch. In the case of large models this can be done even on modest hardware using a low rank training technique known as Low-Rank Adaptation (LoRA). While Low Rank training has already been studied in the continual learning setting, existing works often consider storing the learned adapter along with the existing model but rarely attempt to modify the weights of the pretrained model by merging the LoRA with the existing weights after finishing the training of each task. In this article we investigate this setting and study the impact of LoRA rank on the forgetting of the pretraining foundation task and on the plasticity and forgetting of subsequent ones. We observe that this rank has an important impact on forgetting of both the pretraining and downstream tasks. We also observe that vision transformers finetuned in that way exhibit a sort of ``contextual'' forgetting, a behaviour that we do not observe for residual networks and that we believe has not been observed yet in previous continual learning works.
Read more5/29/2024
0
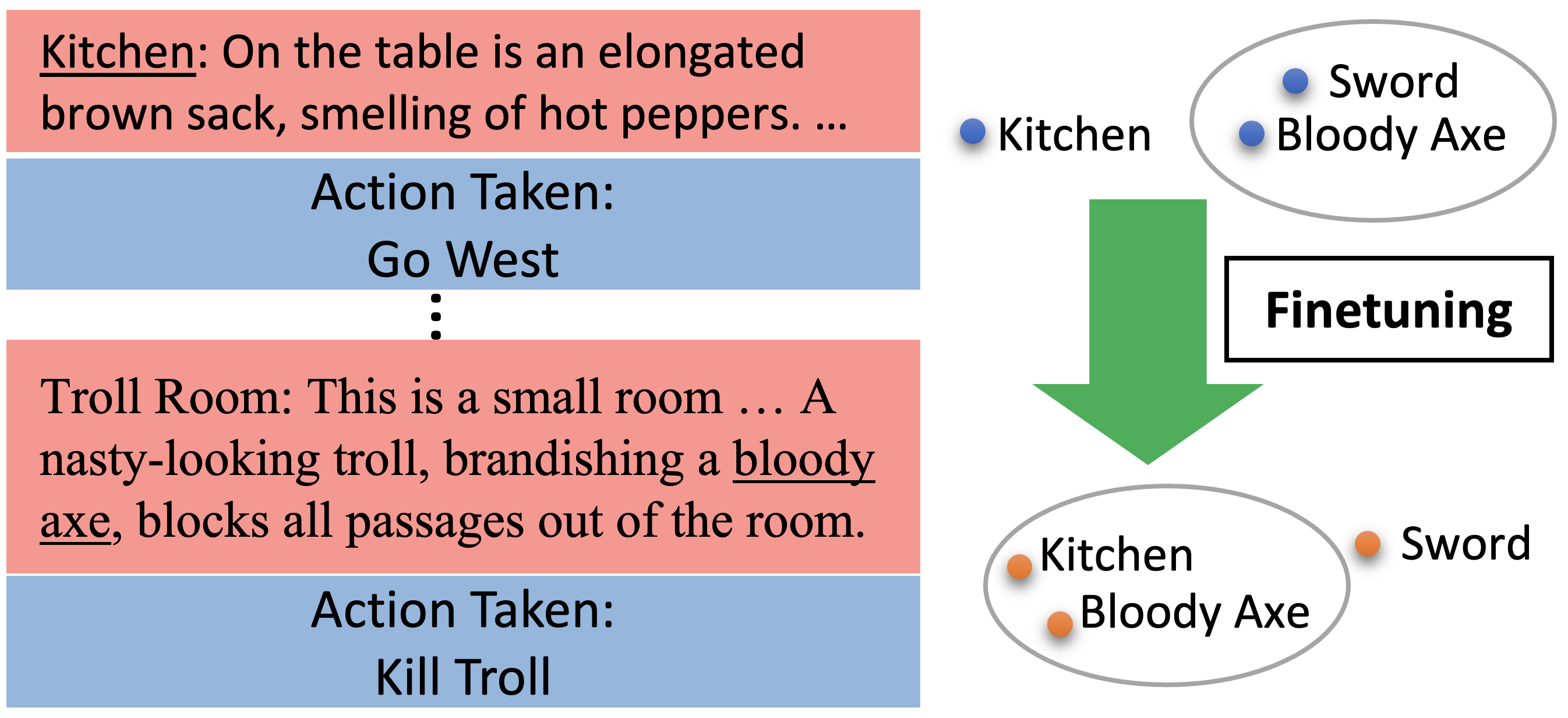
On the Effects of Fine-tuning Language Models for Text-Based Reinforcement Learning
Mauricio Gruppi, Soham Dan, Keerthiram Murugesan, Subhajit Chaudhury
Text-based reinforcement learning involves an agent interacting with a fictional environment using observed text and admissible actions in natural language to complete a task. Previous works have shown that agents can succeed in text-based interactive environments even in the complete absence of semantic understanding or other linguistic capabilities. The success of these agents in playing such games suggests that semantic understanding may not be important for the task. This raises an important question about the benefits of LMs in guiding the agents through the game states. In this work, we show that rich semantic understanding leads to efficient training of text-based RL agents. Moreover, we describe the occurrence of semantic degeneration as a consequence of inappropriate fine-tuning of language models in text-based reinforcement learning (TBRL). Specifically, we describe the shift in the semantic representation of words in the LM, as well as how it affects the performance of the agent in tasks that are semantically similar to the training games. We believe these results may help develop better strategies to fine-tune agents in text-based RL scenarios.
Read more4/17/2024