First Activations Matter: Training-Free Methods for Dynamic Activation in Large Language Models

0

Sign in to get full access
Overview
- The paper explores training-free methods for dynamic activation in large language models (LLMs).
- It investigates the importance of initial activations in LLMs and proposes techniques to leverage this information.
- The methods aim to improve the efficiency and performance of LLMs without requiring additional training.
Plain English Explanation
Large language models (LLMs) have become increasingly powerful, but they can also be computationally expensive and resource-intensive. The paper explores ways to make LLMs more efficient without having to retrain them from scratch.
The key insight is that the initial activations of an LLM, before any input is processed, can contain important information that is often overlooked. By intelligently leveraging these "first activations," the researchers developed techniques that can improve the efficiency and performance of LLMs without requiring additional training.
For example, one approach involves selectively activating only the most relevant neurons in the model based on the initial activations. This can reduce the computational load while maintaining the model's performance. Another technique dynamically adjusts the activation thresholds during inference to adapt to the specific input, further optimizing the model's efficiency.
The paper also explores how the distribution of initial activations can reveal insights about the model's structure and behavior, which can inform strategies for improving its performance.
By focusing on the often-overlooked first activations, this research opens up new avenues for enhancing LLMs without the need for costly retraining. This could lead to more accessible and efficient AI systems that can benefit a wider range of applications and users.
Technical Explanation
The paper starts by highlighting the importance of the initial activations in LLMs, which are the activations of the model's neurons before any input is processed. The researchers hypothesize that these initial activations can contain valuable information that is often overlooked but could be leveraged to improve the efficiency and performance of LLMs.
To explore this, the authors propose several training-free methods that dynamically adapt the activation patterns of LLMs during inference. One approach involves selectively activating only the most relevant neurons based on the initial activations, reducing the computational load while maintaining performance. Another technique dynamically adjusts the activation thresholds to adapt to the specific input, further optimizing the model's efficiency.
The paper also investigates how the distribution of initial activations can reveal insights about the model's structure and behavior, which can inform strategies for improving its performance. For example, the researchers analyze the sparsity and distribution of initial activations and explore how these patterns can be used to guide the selective activation of neurons.
Through extensive experiments on various LLM architectures and benchmarks, the researchers demonstrate the effectiveness of their training-free dynamic activation methods. The proposed techniques consistently improve the efficiency of the models, often with minimal impact on their performance, opening up new possibilities for enhancing the deployment and use of large language models.
Critical Analysis
The paper presents a compelling approach to improving the efficiency of LLMs without the need for costly retraining. By focusing on the often-overlooked initial activations, the researchers have uncovered a valuable source of information that can be leveraged to optimize model performance.
One potential limitation of the proposed methods is that they may not be as effective for all types of LLMs or tasks. The researchers acknowledge that the performance gains may vary depending on the specific model architecture and the complexity of the task. Further research is needed to understand the broader applicability and limitations of these techniques.
Additionally, the paper does not explore the potential impact of these dynamic activation methods on the interpretability and explainability of LLMs. As these models become more widely deployed, there is an increasing need to understand their inner workings and decision-making processes. The effects of the proposed techniques on model interpretability could be an important area for future investigation.
Overall, the paper presents a promising and practical approach to enhancing the efficiency of LLMs, which could have significant implications for the broader adoption and deployment of these powerful AI systems.
Conclusion
The paper explores innovative training-free methods for dynamic activation in large language models (LLMs). By focusing on the often-overlooked initial activations, the researchers have developed techniques that can improve the efficiency of LLMs without requiring costly retraining.
The proposed methods, which selectively activate relevant neurons and dynamically adjust activation thresholds, demonstrate the potential to significantly enhance the performance and deployment of LLMs. This research opens up new avenues for making these powerful AI systems more accessible and practical for a wider range of applications and users.
While the paper acknowledges some limitations and areas for further exploration, the overall contribution of this work is significant. By leveraging the insights gained from the initial activations, the researchers have taken an important step towards unlocking the full potential of large language models in a more efficient and sustainable manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
First Activations Matter: Training-Free Methods for Dynamic Activation in Large Language Models
Chi Ma, Mincong Huang, Ying Zhang, Chao Wang, Yujie Wang, Lei Yu, Chuan Liu, Wei Lin
Dynamic activation (DA) techniques, such as DejaVu and MoEfication, have demonstrated their potential to significantly enhance the inference efficiency of large language models (LLMs). However, these techniques often rely on ReLU activation functions or require additional parameters and training to maintain performance. This paper introduces a training-free Threshold-based Dynamic Activation(TDA) method that leverage sequence information to exploit the inherent sparsity of models across various architectures. This method is designed to accelerate generation speed by 18-25% without significantly compromising task performance, thereby addressing the limitations of existing DA techniques. Moreover, we delve into the root causes of LLM sparsity and theoretically analyze two of its critical features: history-related activation uncertainty and semantic-irrelevant activation inertia. Our comprehensive analyses not only provide a robust theoretical foundation for DA methods but also offer valuable insights to guide future research in optimizing LLMs for greater efficiency and effectiveness.
Read more8/22/2024
0
Dynamic Activation Pitfalls in LLaMA Models: An Empirical Study
Chi Ma, Mincong Huang, Chao Wang, Yujie Wang, Lei Yu
In this work, we systematically investigate the efficacy of dynamic activation mechanisms within the LLaMA family of language models. Despite the potential of dynamic activation methods to reduce computation and increase speed in models using the ReLU activation function, our empirical findings have uncovered several inherent pitfalls in the current dynamic activation schemes. Through extensive experiments across various dynamic activation strategies, we demonstrate that LLaMA models usually underperform when compared to their ReLU counterparts, particularly in scenarios demanding high sparsity ratio. We attribute these deficiencies to a combination of factors: 1) the inherent complexity of dynamically predicting activation heads and neurons; 2) the inadequate sparsity resulting from activation functions; 3) the insufficient preservation of information resulting from KV cache skipping. Our analysis not only sheds light on the limitations of dynamic activation in the context of large-scale LLaMA models but also proposes roadmaps for enhancing the design of future sparsity schemes.
Read more5/16/2024

0
Training-Free Activation Sparsity in Large Language Models
James Liu, Pragaash Ponnusamy, Tianle Cai, Han Guo, Yoon Kim, Ben Athiwaratkun
Activation sparsity can enable practical inference speedups in large language models (LLMs) by reducing the compute and memory-movement required for matrix multiplications during the forward pass. However, existing methods face limitations that inhibit widespread adoption. Some approaches are tailored towards older models with ReLU-based sparsity, while others require extensive continued pre-training on up to hundreds of billions of tokens. This paper describes TEAL, a simple training-free method that applies magnitude-based activation sparsity to hidden states throughout the entire model. TEAL achieves 40-50% model-wide sparsity with minimal performance degradation across Llama-2, Llama-3, and Mistral families, with sizes varying from 7B to 70B. We improve existing sparse kernels and demonstrate wall-clock decoding speed-ups of up to 1.53$times$ and 1.8$times$ at 40% and 50% model-wide sparsity. TEAL is compatible with weight quantization, enabling further efficiency gains.
Read more8/28/2024
0
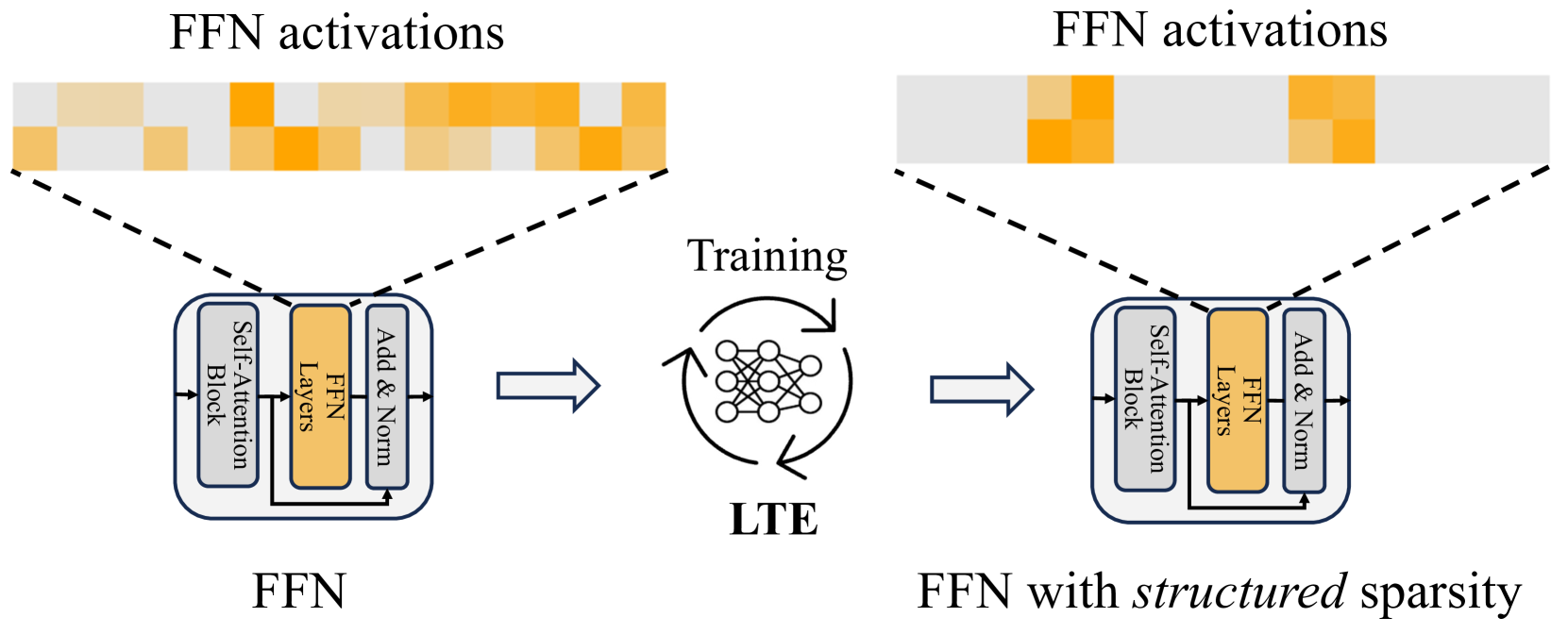
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Haizhong Zheng, Xiaoyan Bai, Xueshen Liu, Z. Morley Mao, Beidi Chen, Fan Lai, Atul Prakash
Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. However, existing methods only focus on utilizing this naturally formed activation sparsity in a post-training setting, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel training algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like LLaMA using non-ReLU activations. Extensive evaluation on language understanding, language generation, and instruction tuning tasks show that LTE consistently outperforms SOTA baselines. Along with our hardware-aware custom kernel implementation, LTE reduces LLaMA2-7B inference latency by 25% at 50% sparsity.
Read more6/5/2024