Dynamic Activation Pitfalls in LLaMA Models: An Empirical Study

0
Sign in to get full access
Overview
- This paper explores the impact of dynamic activation on the performance of LLaMA language models.
- The researchers conduct an empirical study to uncover potential pitfalls and challenges associated with dynamic activation in these models.
- The findings provide valuable insights for developers and researchers working on optimizing large language models like LLaMA for efficient and reliable performance.
Plain English Explanation
This research paper investigates a technique called "dynamic activation" and how it affects the performance of LLaMA, a popular large language model. Dynamic activation is a method that can potentially improve the efficiency of language models by only activating certain parts of the model when they're needed, instead of running the entire model for every input.
The researchers in this study wanted to understand if and how dynamic activation might cause issues or challenges when used with LLaMA. They ran a series of experiments to see how dynamic activation impacts things like the model's accuracy, speed, and overall reliability.
The key findings from this study provide important insights for anyone working on optimizing large language models like LLaMA. The researchers identified some potential "pitfalls" or problems that can arise when using dynamic activation with these types of models. This information can help developers find ways to avoid these issues and get the most out of dynamic activation techniques.
Overall, this research gives us a better understanding of the tradeoffs and considerations involved in using dynamic activation with state-of-the-art language models like LLaMA. The insights can inform future efforts to make these powerful AI systems more efficient and dependable.
Technical Explanation
The paper examines the impact of dynamic activation on the performance of LLaMA models, a family of large language models developed by Meta AI. Dynamic activation is a technique that selectively activates certain parts of a neural network model based on the input, rather than running the entire model for every input.
The researchers designed a series of experiments to empirically study potential "pitfalls" or issues that can arise when using dynamic activation with LLaMA models. They evaluated the models' accuracy, inference speed, and other key metrics under different dynamic activation conditions.
The results revealed several challenges associated with applying dynamic activation to LLaMA models. For example, the researchers found that dynamic activation could lead to inconsistent model outputs, slower inference times, and reduced overall performance in certain cases. The paper discusses these findings in detail and provides insights into the tradeoffs involved in leveraging dynamic activation for large language models.
These insights build on previous research on techniques like efficient inference, model sparsity, and accelerated pre-training for large language models. The findings can inform future efforts to develop more efficient and robust LLaMA models and other similar AI systems.
Critical Analysis
The paper provides a thorough and well-designed empirical study on the implications of using dynamic activation with LLaMA models. The researchers acknowledge several limitations to their work, such as the need to test the findings on a wider range of LLaMA model sizes and configurations.
One potential area for further research would be to investigate how different dynamic activation techniques or hyperparameter settings might mitigate the challenges identified in this study. The paper also does not explore the impact of dynamic activation on other performance metrics, such as training efficiency or model size, which could be valuable to consider.
Additionally, while the paper highlights the pitfalls of dynamic activation with LLaMA, it would be helpful to see a more in-depth discussion of the tradeoffs involved. For example, how do the performance drawbacks compare to the potential benefits of improved efficiency or reduced computational requirements?
Overall, the research presents important insights that can guide future work on optimizing large language models like LLaMA. However, there may be opportunities to build on this study and explore additional facets of the dynamic activation challenge.
Conclusion
This paper provides a detailed empirical investigation into the impact of dynamic activation on the performance of LLaMA language models. The researchers uncovered several potential pitfalls, such as inconsistent outputs, slower inference times, and reduced overall model performance, that can arise when using dynamic activation with these large-scale AI systems.
The findings offer valuable guidance for developers and researchers working to optimize the efficiency and reliability of state-of-the-art language models. By understanding the tradeoffs and challenges associated with dynamic activation, they can make more informed decisions about how to apply these techniques to achieve the best results.
Overall, this study contributes important insights that can inform future efforts to create more efficient, robust, and dependable large language models like LLaMA. The lessons learned can also extend to the development of other types of AI systems that rely on dynamic activation or similar optimization techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dynamic Activation Pitfalls in LLaMA Models: An Empirical Study
Chi Ma, Mincong Huang, Chao Wang, Yujie Wang, Lei Yu
In this work, we systematically investigate the efficacy of dynamic activation mechanisms within the LLaMA family of language models. Despite the potential of dynamic activation methods to reduce computation and increase speed in models using the ReLU activation function, our empirical findings have uncovered several inherent pitfalls in the current dynamic activation schemes. Through extensive experiments across various dynamic activation strategies, we demonstrate that LLaMA models usually underperform when compared to their ReLU counterparts, particularly in scenarios demanding high sparsity ratio. We attribute these deficiencies to a combination of factors: 1) the inherent complexity of dynamically predicting activation heads and neurons; 2) the inadequate sparsity resulting from activation functions; 3) the insufficient preservation of information resulting from KV cache skipping. Our analysis not only sheds light on the limitations of dynamic activation in the context of large-scale LLaMA models but also proposes roadmaps for enhancing the design of future sparsity schemes.
Read more5/16/2024

0
First Activations Matter: Training-Free Methods for Dynamic Activation in Large Language Models
Chi Ma, Mincong Huang, Ying Zhang, Chao Wang, Yujie Wang, Lei Yu, Chuan Liu, Wei Lin
Dynamic activation (DA) techniques, such as DejaVu and MoEfication, have demonstrated their potential to significantly enhance the inference efficiency of large language models (LLMs). However, these techniques often rely on ReLU activation functions or require additional parameters and training to maintain performance. This paper introduces a training-free Threshold-based Dynamic Activation(TDA) method that leverage sequence information to exploit the inherent sparsity of models across various architectures. This method is designed to accelerate generation speed by 18-25% without significantly compromising task performance, thereby addressing the limitations of existing DA techniques. Moreover, we delve into the root causes of LLM sparsity and theoretically analyze two of its critical features: history-related activation uncertainty and semantic-irrelevant activation inertia. Our comprehensive analyses not only provide a robust theoretical foundation for DA methods but also offer valuable insights to guide future research in optimizing LLMs for greater efficiency and effectiveness.
Read more8/22/2024

0
Unraveling Babel: Exploring Multilingual Activation Patterns of LLMs and Their Applications
Weize Liu, Yinlong Xu, Hongxia Xu, Jintai Chen, Xuming Hu, Jian Wu
Recently, large language models (LLMs) have achieved tremendous breakthroughs in the field of NLP, but still lack understanding of their internal activities when processing different languages. We designed a method to convert dense LLMs into fine-grained MoE architectures, and then visually studied the multilingual activation patterns of LLMs through expert activation frequency heatmaps. Through comprehensive experiments on different model families, different model sizes, and different variants, we analyzed the distribution of high-frequency activated experts, multilingual shared experts, whether the activation patterns of different languages are related to language families, and the impact of instruction tuning on activation patterns. We further explored leveraging the discovered differences in expert activation frequencies to guide unstructured pruning in two different ways. Experimental results demonstrated that our method significantly outperformed random expert pruning and even exceeded the performance of the original unpruned models in some languages. Additionally, we found that configuring different pruning rates for different layers based on activation level differences could achieve better results. Our findings reveal the multilingual processing mechanisms within LLMs and utilize these insights to offer new perspectives for applications such as model pruning.
Read more6/19/2024
0
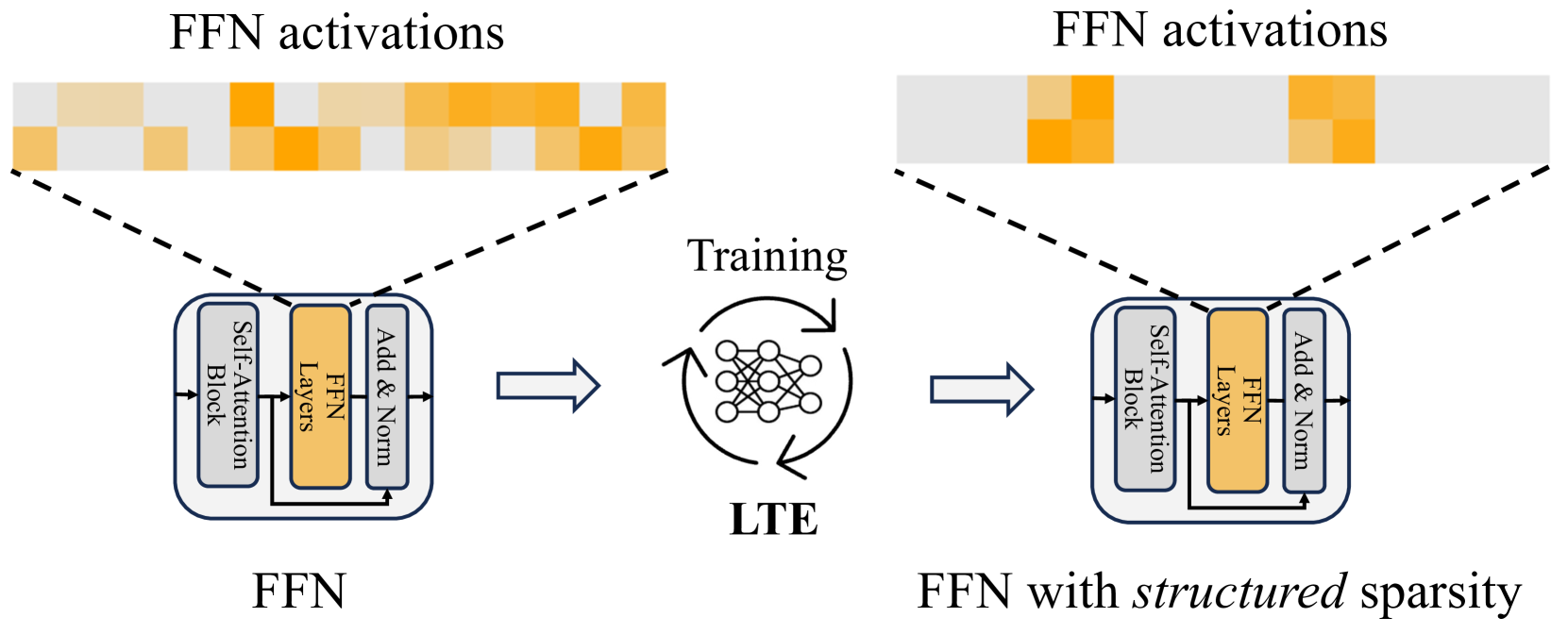
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Haizhong Zheng, Xiaoyan Bai, Xueshen Liu, Z. Morley Mao, Beidi Chen, Fan Lai, Atul Prakash
Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. However, existing methods only focus on utilizing this naturally formed activation sparsity in a post-training setting, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel training algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like LLaMA using non-ReLU activations. Extensive evaluation on language understanding, language generation, and instruction tuning tasks show that LTE consistently outperforms SOTA baselines. Along with our hardware-aware custom kernel implementation, LTE reduces LLaMA2-7B inference latency by 25% at 50% sparsity.
Read more6/5/2024