FlowIBR: Leveraging Pre-Training for Efficient Neural Image-Based Rendering of Dynamic Scenes

0
🧠
Sign in to get full access
Overview
- FlowIBR is a new approach for efficient monocular novel view synthesis of dynamic scenes.
- Existing techniques produce high-quality renderings, but require long optimization times per scene without leveraging prior knowledge.
- FlowIBR integrates a pre-trained neural image-based rendering method with a per-scene optimized scene flow field to counteract scene dynamics.
- This reduces per-scene optimization time by an order of magnitude while achieving comparable rendering quality, all on a single consumer-grade GPU.
Plain English Explanation
FlowIBR is a new technology that can create realistic 3D video from a single camera. Existing methods can produce impressive results, but they take a long time to optimize for each new scene. FlowIBR gets around this by combining a pre-trained neural network, which has learned from many different static scenes, with a custom flow field that adapts to the dynamics of the current scene.
This flow field bends the camera rays to make the dynamic scene appear static to the neural rendering network. As a result, FlowIBR can create high-quality 3D videos much faster than previous approaches, only needing a single consumer-grade graphics card to do so. It's like having a neural network that's an expert at capturing static scenes, and then using some extra tricks to make it work well for dynamic scenes too.
Technical Explanation
FlowIBR leverages Semantic Flow Learning for Dynamic Scenes and Incremental Joint Learning of Depth, Pose, and Implicit Scene Representation to optimize a per-scene scene flow field. This flow field is then used to bend the camera rays, counteracting the scene dynamics and presenting the dynamic content as if it were static to a pre-trained neural image-based rendering network.
The use of the pre-trained rendering network, combined with the per-scene flow field optimization, reduces the overall optimization time by an order of magnitude compared to existing approaches, as shown in Knowledge-NeRF: Few-Shot Novel View Synthesis. This allows FlowIBR to achieve comparable rendering quality to state-of-the-art methods, but with significantly faster per-scene processing times, all on a single consumer-grade GPU.
Critical Analysis
The paper acknowledges that FlowIBR relies on the availability of a large corpus of static scene data to pre-train the rendering network. This may limit its applicability to domains where such data is scarce. Additionally, the per-scene flow field optimization, while more efficient than prior approaches, still requires some computational overhead, which could be a concern for real-time applications.
Furthermore, the paper does not provide a detailed analysis of failure cases or limitations of the FlowIBR approach. It would be valuable to understand the types of dynamic scenes or camera motions that the method struggles with, as well as any potential biases or artifacts introduced by the flow field estimation or neural rendering components.
Conclusion
FlowIBR represents a promising advance in the field of monocular novel view synthesis for dynamic scenes. By leveraging a pre-trained neural rendering network and a per-scene optimized flow field, the method can produce high-quality 3D video reconstructions much more efficiently than previous approaches. This could have significant implications for applications such as robust visual-inertial navigation, where the ability to quickly generate novel views from a single camera is crucial. While the method has some limitations, the core idea of combining static scene knowledge with dynamic scene-specific adjustments is a compelling direction for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
FlowIBR: Leveraging Pre-Training for Efficient Neural Image-Based Rendering of Dynamic Scenes
Marcel Busching, Josef Bengtson, David Nilsson, M{aa}rten Bjorkman
We introduce FlowIBR, a novel approach for efficient monocular novel view synthesis of dynamic scenes. Existing techniques already show impressive rendering quality but tend to focus on optimization within a single scene without leveraging prior knowledge, resulting in long optimization times per scene. FlowIBR circumvents this limitation by integrating a neural image-based rendering method, pre-trained on a large corpus of widely available static scenes, with a per-scene optimized scene flow field. Utilizing this flow field, we bend the camera rays to counteract the scene dynamics, thereby presenting the dynamic scene as if it were static to the rendering network. The proposed method reduces per-scene optimization time by an order of magnitude, achieving comparable rendering quality to existing methods -- all on a single consumer-grade GPU.
Read more4/16/2024
0
Semantic Flow: Learning Semantic Field of Dynamic Scenes from Monocular Videos
Fengrui Tian, Yueqi Duan, Angtian Wang, Jianfei Guo, Shaoyi Du
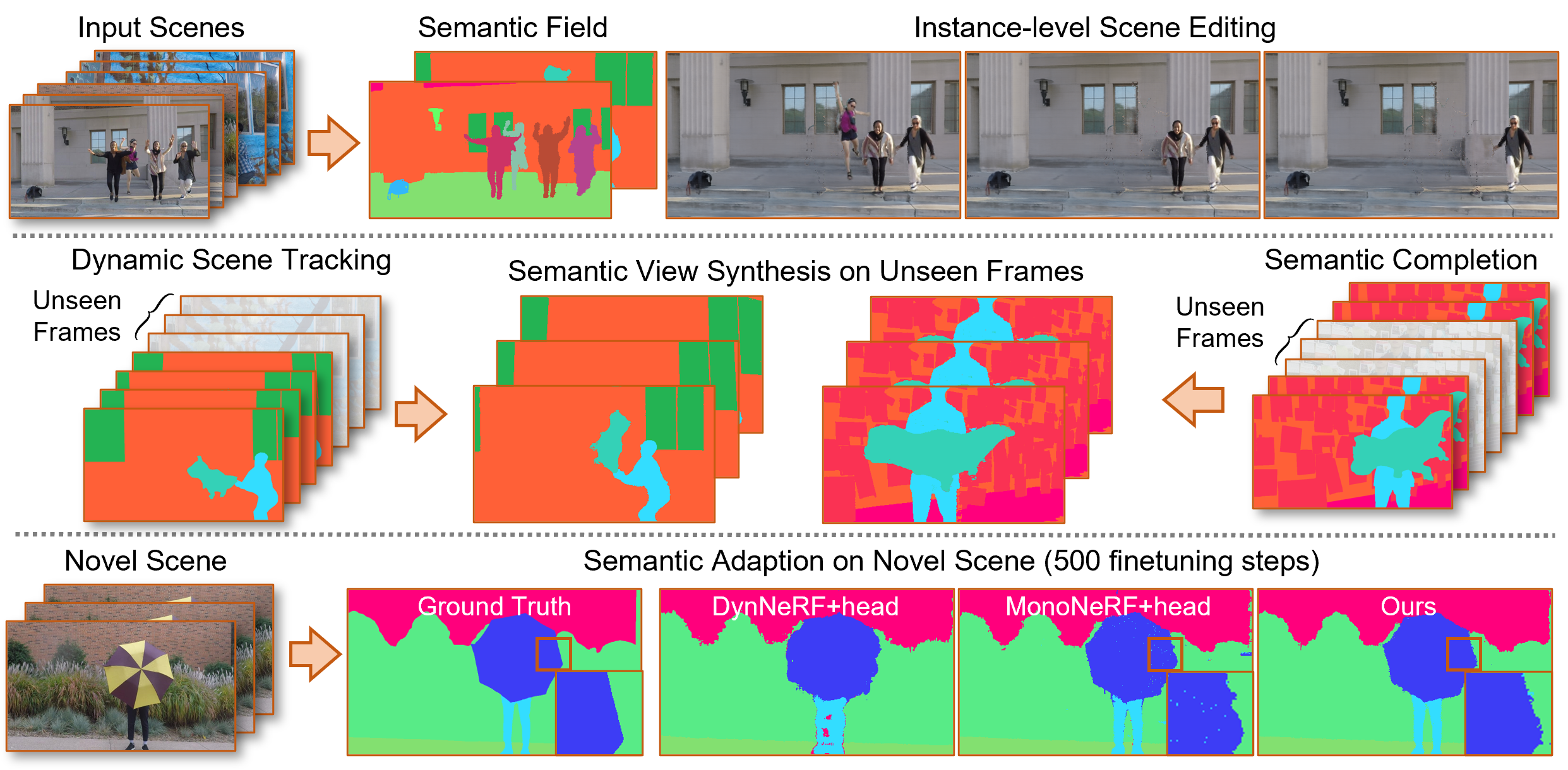
In this work, we pioneer Semantic Flow, a neural semantic representation of dynamic scenes from monocular videos. In contrast to previous NeRF methods that reconstruct dynamic scenes from the colors and volume densities of individual points, Semantic Flow learns semantics from continuous flows that contain rich 3D motion information. As there is 2D-to-3D ambiguity problem in the viewing direction when extracting 3D flow features from 2D video frames, we consider the volume densities as opacity priors that describe the contributions of flow features to the semantics on the frames. More specifically, we first learn a flow network to predict flows in the dynamic scene, and propose a flow feature aggregation module to extract flow features from video frames. Then, we propose a flow attention module to extract motion information from flow features, which is followed by a semantic network to output semantic logits of flows. We integrate the logits with volume densities in the viewing direction to supervise the flow features with semantic labels on video frames. Experimental results show that our model is able to learn from multiple dynamic scenes and supports a series of new tasks such as instance-level scene editing, semantic completions, dynamic scene tracking and semantic adaption on novel scenes. Codes are available at https://github.com/tianfr/Semantic-Flow/.
Read more4/9/2024
👀
0
Fast View Synthesis of Casual Videos with Soup-of-Planes
Yao-Chih Lee, Zhoutong Zhang, Kevin Blackburn-Matzen, Simon Niklaus, Jianming Zhang, Jia-Bin Huang, Feng Liu
Novel view synthesis from an in-the-wild video is difficult due to challenges like scene dynamics and lack of parallax. While existing methods have shown promising results with implicit neural radiance fields, they are slow to train and render. This paper revisits explicit video representations to synthesize high-quality novel views from a monocular video efficiently. We treat static and dynamic video content separately. Specifically, we build a global static scene model using an extended plane-based scene representation to synthesize temporally coherent novel video. Our plane-based scene representation is augmented with spherical harmonics and displacement maps to capture view-dependent effects and model non-planar complex surface geometry. We opt to represent the dynamic content as per-frame point clouds for efficiency. While such representations are inconsistency-prone, minor temporal inconsistencies are perceptually masked due to motion. We develop a method to quickly estimate such a hybrid video representation and render novel views in real time. Our experiments show that our method can render high-quality novel views from an in-the-wild video with comparable quality to state-of-the-art methods while being 100x faster in training and enabling real-time rendering.
Read more7/22/2024

0
Boosting Flow-based Generative Super-Resolution Models via Learned Prior
Li-Yuan Tsao, Yi-Chen Lo, Chia-Che Chang, Hao-Wei Chen, Roy Tseng, Chien Feng, Chun-Yi Lee
Flow-based super-resolution (SR) models have demonstrated astonishing capabilities in generating high-quality images. However, these methods encounter several challenges during image generation, such as grid artifacts, exploding inverses, and suboptimal results due to a fixed sampling temperature. To overcome these issues, this work introduces a conditional learned prior to the inference phase of a flow-based SR model. This prior is a latent code predicted by our proposed latent module conditioned on the low-resolution image, which is then transformed by the flow model into an SR image. Our framework is designed to seamlessly integrate with any contemporary flow-based SR model without modifying its architecture or pre-trained weights. We evaluate the effectiveness of our proposed framework through extensive experiments and ablation analyses. The proposed framework successfully addresses all the inherent issues in flow-based SR models and enhances their performance in various SR scenarios. Our code is available at: https://github.com/liyuantsao/BFSR
Read more5/30/2024