Revisiting Image Captioning Training Paradigm via Direct CLIP-based Optimization

0

Sign in to get full access
Overview
- This paper explores a new training paradigm for image captioning models that directly optimizes the model's output to match CLIP's understanding of the image-caption relationship.
- The authors propose a CLIP-based optimization approach that improves the quality and consistency of generated captions compared to conventional language modeling-based techniques.
- The key idea is to leverage the powerful image-text alignment capabilities of CLIP to guide the training of image captioning models.
Plain English Explanation
The paper presents a new way to train image captioning models, which are AI systems that can generate descriptive text for images. Traditionally, these models have been trained using language modeling techniques that focus on generating fluent captions. However, the authors argue that this approach doesn't fully capture the deeper semantic relationship between the image and the caption.
To address this, the researchers propose a CLIP-based optimization approach. CLIP is a powerful AI model that can understand the connection between images and text very well. The key idea is to use CLIP to guide the training of the image captioning model, so that the generated captions not only sound natural, but also truly reflect the meaning of the image.
This CLIP-based training can result in captions that are more consistent with the image and better capture the semantics, compared to conventional language modeling approaches. The authors demonstrate that their method can improve the quality and coherence of the generated captions.
Technical Explanation
The paper proposes a CLIP-based optimization approach for training image captioning models. Traditionally, these models have been trained using a language modeling objective, which focuses on generating fluent captions but doesn't necessarily capture the deeper semantic relationship between the image and the caption.
The key idea is to leverage the powerful image-text alignment capabilities of CLIP to guide the training of the captioning model. Specifically, the authors introduce a new loss function that directly optimizes the model's output to match CLIP's understanding of the image-caption relationship. This CLIP-based optimization enables the captioning model to generate captions that are not only grammatically correct, but also consistently aligned with the visual semantics of the image.
The authors evaluate their approach on standard image captioning benchmarks and demonstrate that it can outperform conventional language modeling-based techniques in terms of both caption quality and consistency with the input image.
Critical Analysis
The paper presents a compelling approach to improving image captioning by directly incorporating the capabilities of CLIP, a powerful vision-language model. The proposed CLIP-based optimization technique is a novel and promising direction for the field.
One potential limitation is that the method relies heavily on the quality and robustness of the underlying CLIP model. If CLIP has any biases or limitations in its image-text understanding, these could potentially be reflected in the generated captions. Additionally, the authors do not explore the generalization of their approach to other vision-language tasks beyond captioning.
Further research could investigate ways to make the CLIP-based optimization more robust and adaptive, potentially by incorporating techniques like CLIP distillation or ranking-consistent pretraining. Exploring the application of this approach to other vision-language problems could also yield valuable insights.
Overall, the paper presents a compelling and well-executed study that advances the state of the art in image captioning by leveraging the strengths of CLIP. The CLIP-based optimization technique is a promising direction that warrants further exploration and refinement.
Conclusion
This paper introduces a novel CLIP-based optimization approach for training image captioning models. By directly aligning the model's outputs with CLIP's understanding of the image-caption relationship, the authors are able to generate captions that are not only fluent, but also semantically consistent with the input image.
The key contribution of this work is the demonstration that leveraging powerful vision-language models like CLIP can significantly improve the quality and coherence of image captioning, beyond what is possible with traditional language modeling techniques. This approach has the potential to drive further advancements in vision-language integration and enable more intelligent and reliable image understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revisiting Image Captioning Training Paradigm via Direct CLIP-based Optimization
Nicholas Moratelli, Davide Caffagni, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
The conventional training approach for image captioning involves pre-training a network using teacher forcing and subsequent fine-tuning with Self-Critical Sequence Training to maximize hand-crafted captioning metrics. However, when attempting to optimize modern and higher-quality metrics like CLIP-Score and PAC-Score, this training method often encounters instability and fails to acquire the genuine descriptive capabilities needed to produce fluent and informative captions. In this paper, we propose a new training paradigm termed Direct CLIP-Based Optimization (DiCO). Our approach jointly learns and optimizes a reward model that is distilled from a learnable captioning evaluator with high human correlation. This is done by solving a weighted classification problem directly inside the captioner. At the same time, DiCO prevents divergence from the original model, ensuring that fluency is maintained. DiCO not only exhibits improved stability and enhanced quality in the generated captions but also aligns more closely with human preferences compared to existing methods, especially in modern metrics. Additionally, it maintains competitive performance in traditional metrics. Our source code and trained models are publicly available at https://github.com/aimagelab/DiCO.
Read more8/28/2024
0
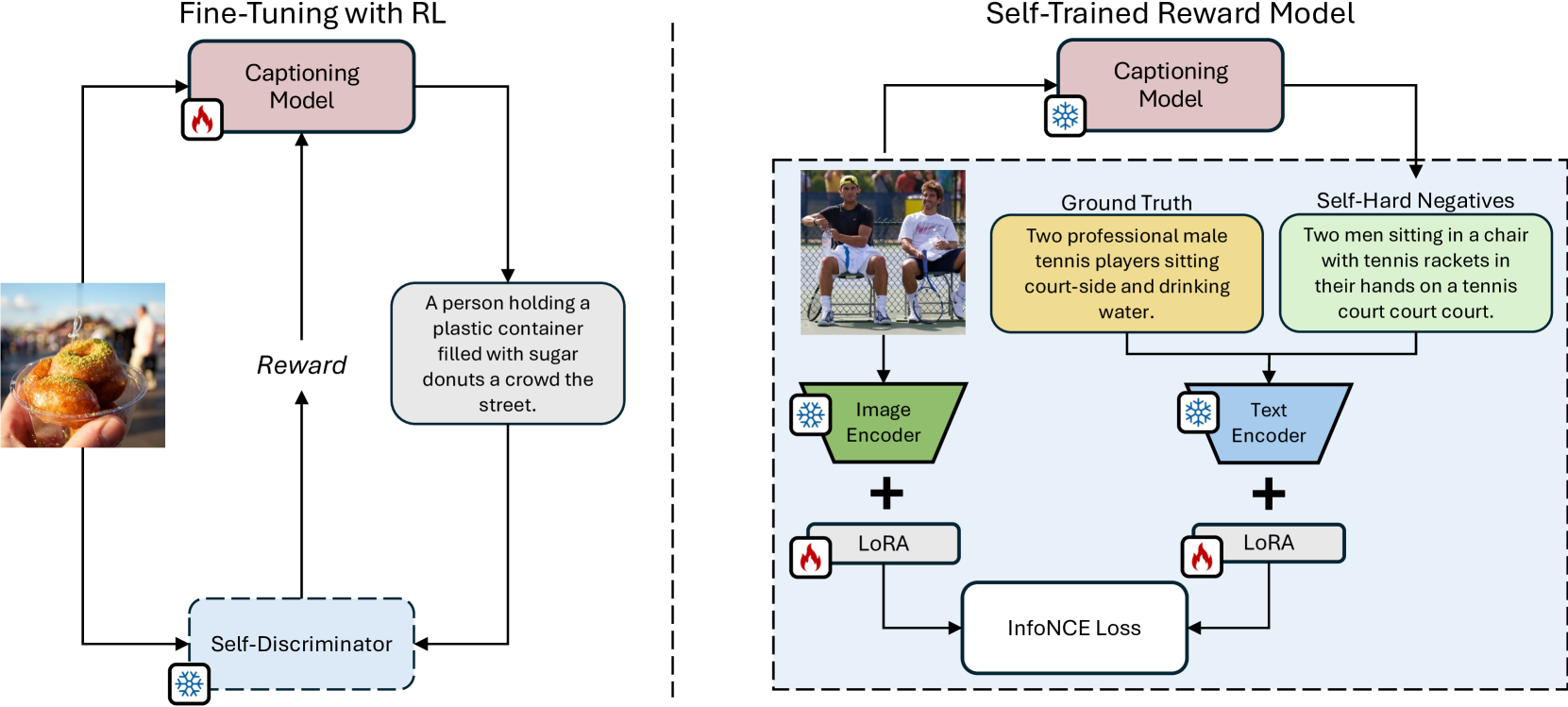
Fluent and Accurate Image Captioning with a Self-Trained Reward Model
Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
Fine-tuning image captioning models with hand-crafted rewards like the CIDEr metric has been a classical strategy for promoting caption quality at the sequence level. This approach, however, is known to limit descriptiveness and semantic richness and tends to drive the model towards the style of ground-truth sentences, thus losing detail and specificity. On the contrary, recent attempts to employ image-text models like CLIP as reward have led to grammatically incorrect and repetitive captions. In this paper, we propose Self-Cap, a captioning approach that relies on a learnable reward model based on self-generated negatives that can discriminate captions based on their consistency with the image. Specifically, our discriminator is a fine-tuned contrastive image-text model trained to promote caption correctness while avoiding the aberrations that typically happen when training with a CLIP-based reward. To this end, our discriminator directly incorporates negative samples from a frozen captioner, which significantly improves the quality and richness of the generated captions but also reduces the fine-tuning time in comparison to using the CIDEr score as the sole metric for optimization. Experimental results demonstrate the effectiveness of our training strategy on both standard and zero-shot image captioning datasets.
Read more9/2/2024

0
Updating CLIP to Prefer Descriptions Over Captions
Amir Zur, Elisa Kreiss, Karel D'Oosterlinck, Christopher Potts, Atticus Geiger
Although CLIPScore is a powerful generic metric that captures the similarity between a text and an image, it fails to distinguish between a caption that is meant to complement the information in an image and a description that is meant to replace an image entirely, e.g., for accessibility. We address this shortcoming by updating the CLIP model with the Concadia dataset to assign higher scores to descriptions than captions using parameter efficient fine-tuning and a loss objective derived from work on causal interpretability. This model correlates with the judgements of blind and low-vision people while preserving transfer capabilities and has interpretable structure that sheds light on the caption--description distinction.
Read more6/17/2024

0
CLIP with Quality Captions: A Strong Pretraining for Vision Tasks
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Oncel Tuzel
CLIP models perform remarkably well on zero-shot classification and retrieval tasks. But recent studies have shown that learnt representations in CLIP are not well suited for dense prediction tasks like object detection, semantic segmentation or depth estimation. More recently, multi-stage training methods for CLIP models was introduced to mitigate the weak performance of CLIP on downstream tasks. In this work, we find that simply improving the quality of captions in image-text datasets improves the quality of CLIP's visual representations, resulting in significant improvement on downstream dense prediction vision tasks. In fact, we find that CLIP pretraining with good quality captions can surpass recent supervised, self-supervised and weakly supervised pretraining methods. We show that when CLIP model with ViT-B/16 as image encoder is trained on well aligned image-text pairs it obtains 12.1% higher mIoU and 11.5% lower RMSE on semantic segmentation and depth estimation tasks over recent state-of-the-art Masked Image Modeling (MIM) pretraining methods like Masked Autoencoder (MAE). We find that mobile architectures also benefit significantly from CLIP pretraining. A recent mobile vision architecture, MCi2, with CLIP pretraining obtains similar performance as Swin-L, pretrained on ImageNet-22k for semantic segmentation task while being 6.1$times$ smaller. Moreover, we show that improving caption quality results in $10times$ data efficiency when finetuning for dense prediction tasks.
Read more5/16/2024