FormulaReasoning: A Dataset for Formula-Based Numerical Reasoning

0

Sign in to get full access
Overview
- The paper introduces FormulaQA, a new dataset for evaluating a model's ability to perform numerical reasoning based on mathematical formulas.
- The dataset consists of question-answer pairs that require understanding and applying various mathematical concepts and operations.
- The goal is to develop AI systems that can effectively reason about and solve numerical problems expressed in natural language and formulas.
Plain English Explanation
The FormulaQA dataset is designed to test the ability of AI models to understand and solve math-based problems. It contains a collection of questions that require the model to read a problem statement, comprehend the mathematical formulas and concepts involved, and then perform the necessary calculations to arrive at the correct answer.
This is an important challenge for AI systems, as numerical reasoning is a crucial skill for many real-world applications, from financial analysis to scientific problem-solving. By creating a dataset focused specifically on formula-based questions, the researchers aim to push the boundaries of what current AI models can do and encourage the development of more advanced numerical reasoning capabilities.
The dataset covers a wide range of mathematical topics, including algebra, geometry, trigonometry, and statistics. Each question presents a problem statement, along with the relevant formulas and numerical values, and the model must use this information to derive the correct answer. This tests the model's ability to understand the logical relationships between the different elements and apply the appropriate mathematical operations.
Technical Explanation
The FormulaQA dataset was created by curating and annotating a large collection of math-based problems from various online sources, such as educational websites and question banks. The researchers carefully selected and organized the questions to ensure they cover a diverse range of mathematical concepts and difficulty levels.
Each question in the dataset includes the following elements:
- A natural language problem statement
- One or more relevant mathematical formulas
- Numerical values to be used in the calculations
- The correct numerical answer
The dataset is divided into a training set, a validation set, and a test set, allowing researchers to evaluate the performance of their models on both seen and unseen data. The researchers also provide a set of baseline models, including transformer-based language models and specialized numerical reasoning systems, to serve as a starting point for further research and development.
Critical Analysis
The FormulaQA dataset represents an important step forward in the field of numerical reasoning for AI systems. By focusing specifically on formula-based problems, the dataset challenges models to go beyond simple arithmetic and engage with more complex mathematical concepts and reasoning.
However, the paper acknowledges several limitations of the dataset. For example, the questions are predominantly in a structured format, with clear problem statements and formulas provided. In real-world scenarios, numerical reasoning may involve more freeform language and a greater need to extract relevant information from unstructured text. Additionally, the dataset does not address the ability to generate or validate mathematical expressions, which could be an important aspect of advanced numerical reasoning.
Further research is needed to explore the generalization of the models trained on FormulaQA to more open-ended or real-world numerical reasoning tasks. Integrating the dataset with other benchmarks, such as LogicBench or JiuZhang30, could provide a more comprehensive evaluation of a model's numerical reasoning capabilities.
Conclusion
The FormulaQA dataset represents a significant contribution to the field of AI research, as it provides a novel benchmark for evaluating a model's ability to perform numerical reasoning based on mathematical formulas. By challenging models to understand and apply complex mathematical concepts, the dataset pushes the boundaries of what current AI systems can do and paves the way for the development of more advanced numerical reasoning capabilities.
As AI systems continue to play an increasingly important role in a wide range of applications, the ability to effectively reason about and solve numerical problems will become increasingly crucial. The FormulaQA dataset offers a valuable tool for researchers and developers to assess and improve the numerical reasoning skills of their AI models, ultimately leading to more capable and reliable systems that can tackle complex real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FormulaReasoning: A Dataset for Formula-Based Numerical Reasoning
Xiao Li, Bolin Zhu, Sichen Liu, Yin Zhu, Yiwei Liu, Gong Cheng
The application of formulas is a fundamental ability of humans when addressing numerical reasoning problems. However, existing numerical reasoning datasets seldom explicitly indicate the formulas employed during the reasoning steps. To bridge this gap, we construct a dataset for formula-based numerical reasoning called FormulaReasoning, which consists of 5,420 reasoning-based questions. We employ it to conduct evaluations of LLMs with size ranging from 7B to over 100B parameters utilizing zero-shot and few-shot chain-of-thought methods, and we further explore using retrieval-augmented LLMs provided with an external formula database associated with our dataset. We also experiment with supervised methods where we divide the reasoning process into formula generation, parameter extraction, and numerical calculation, and perform data augmentation. Our empirical findings underscore the significant potential for improvement in existing models when applied to our complex, formula-driven FormulaReasoning.
Read more6/13/2024
🌐
0
Case-Based Reasoning Approach for Solving Financial Question Answering
Yikyung Kim, Jay-Yoon Lee
Measuring a machine's understanding of human language often involves assessing its reasoning skills, i.e. logical process of deriving answers to questions. While recent language models have shown remarkable proficiency in text based tasks, their efficacy in complex reasoning problems involving heterogeneous information such as text, tables, and numbers remain uncertain. Addressing this gap, FinQA introduced a numerical reasoning dataset for financial documents and simultaneously proposed a program generation approach . Our investigation reveals that half of the errors (48%) stem from incorrect operations being generated. To address this issue, we propose a novel approach to tackle numerical reasoning problems using case based reasoning (CBR), an artificial intelligence paradigm that provides problem solving guidance by offering similar cases (i.e. similar questions and corresponding logical programs). Our model retrieves relevant cases to address a given question, and then generates an answer based on the retrieved cases and contextual information. Through experiments on the FinQA dataset, we demonstrate competitive performance of our approach and additionally show that by expanding case repository, we can help solving complex multi step programs which FinQA showed weakness of.
Read more5/24/2024
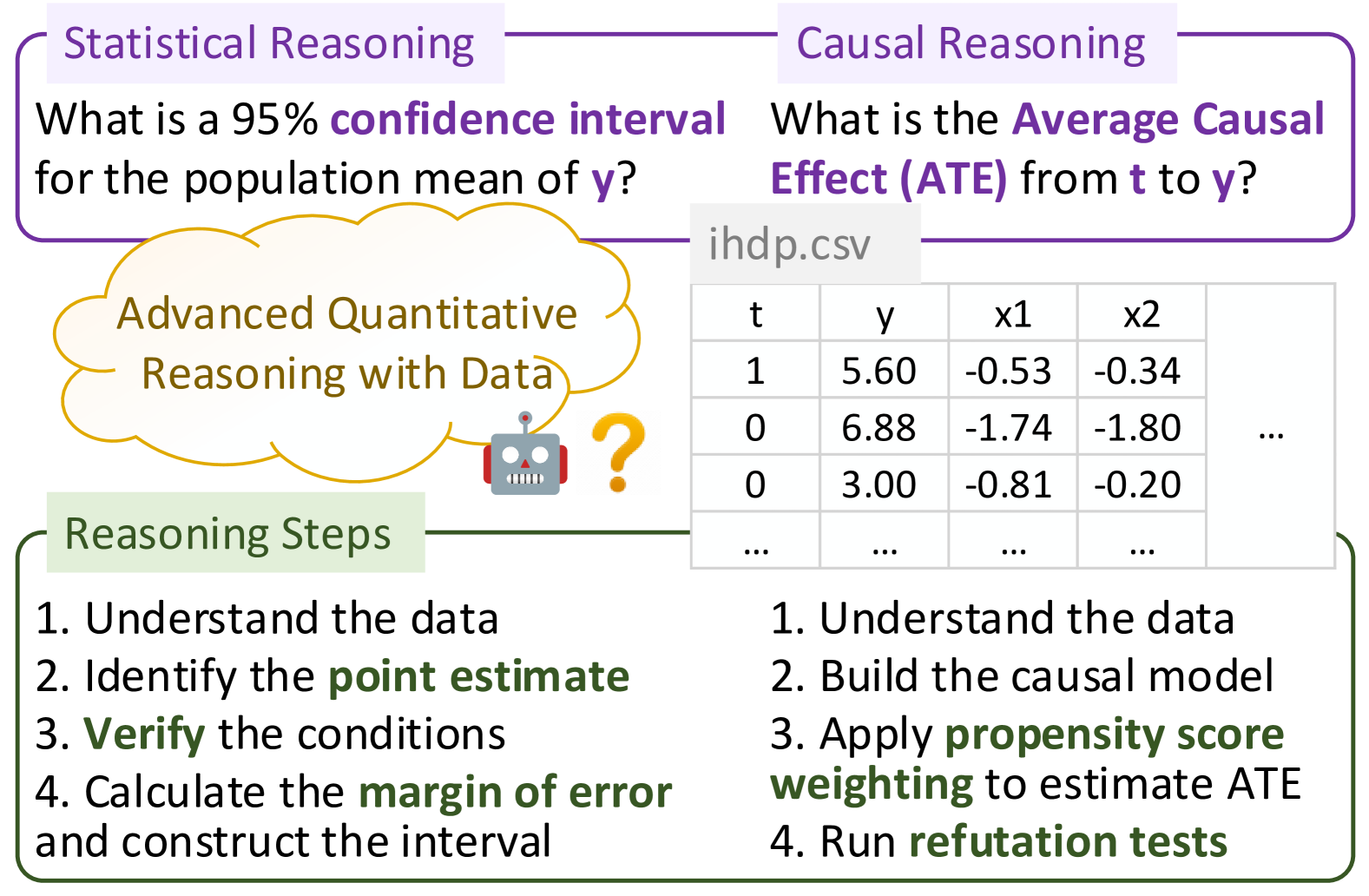
0
Are LLMs Capable of Data-based Statistical and Causal Reasoning? Benchmarking Advanced Quantitative Reasoning with Data
Xiao Liu, Zirui Wu, Xueqing Wu, Pan Lu, Kai-Wei Chang, Yansong Feng
Quantitative reasoning is a critical skill to analyze data, yet the assessment of such ability remains limited. To address this gap, we introduce the Quantitative Reasoning with Data (QRData) benchmark, aiming to evaluate Large Language Models' capability in statistical and causal reasoning with real-world data. The benchmark comprises a carefully constructed dataset of 411 questions accompanied by data sheets from textbooks, online learning materials, and academic papers. To compare models' quantitative reasoning abilities on data and text, we enrich the benchmark with an auxiliary set of 290 text-only questions, namely QRText. We evaluate natural language reasoning, program-based reasoning, and agent reasoning methods including Chain-of-Thought, Program-of-Thoughts, ReAct, and code interpreter assistants on diverse models. The strongest model GPT-4 achieves an accuracy of 58%, which has much room for improvement. Among open-source models, Deepseek-coder-instruct, a code LLM pretrained on 2T tokens, gets the highest accuracy of 37%. Analysis reveals that models encounter difficulties in data analysis and causal reasoning, and struggle in using causal knowledge and provided data simultaneously. Code and data are in https://github.com/xxxiaol/QRData.
Read more6/11/2024
💬
0
Logic Contrastive Reasoning with Lightweight Large Language Model for Math Word Problems
Ding Kai, Ma Zhenguo, Yan Xiaoran
This study focuses on improving the performance of lightweight Large Language Models (LLMs) in mathematical reasoning tasks. We introduce a novel method for measuring mathematical logic similarity and design an automatic screening mechanism to construct a set of reference problems that integrate both semantic and logical similarity. By employing carefully crafted positive and negative example prompts, we guide the model towards adopting sound reasoning logic. To the best of our knowledge, this is the first attempt to utilize retrieval-enhanced generation for mathematical problem-solving. Experimental results demonstrate that our method achieves a 15.8% improvement over the Chain of Thought approach on the SVAMP dataset and a 21.5 % improvement on the GSM8K dataset. Further application of this method to a large-scale model with 175 billion parameters yields performance comparable to the best results on both aforementioned datasets. Finally, we conduct an analysis of errors during the reasoning process, providing valuable insights and directions for future research on reasoning tasks using large language models.
Read more9/4/2024