Foster Adaptivity and Balance in Learning with Noisy Labels

0
Sign in to get full access
Overview
- Addresses the challenge of training machine learning models with noisy labels, where the true labels of the training data may be corrupted or inaccurate
- Proposes a novel approach called "Foster Adaptivity and Balance" (FAB) that aims to adaptively select and re-weight samples during training to improve model performance
- Key aspects include:
- Self-adaptive sample selection and re-weighting to handle noisy labels
- Class-balanced training to address class imbalance
- Demonstrated effectiveness on various benchmark datasets with noisy labels
Plain English Explanation
Training machine learning models often relies on labeled data, where each example has a "label" indicating the correct output or category. However, in many real-world scenarios, these labels can be inaccurate or "noisy," meaning they don't perfectly match the true underlying information. This can happen for various reasons, such as human error during data labeling or inherent ambiguity in the data.
The Foster Adaptivity and Balance (FAB) approach proposed in this paper aims to address the challenge of training effective models even when the training data has noisy labels. The key idea is to adaptively select and re-weight the training samples during the learning process, based on their perceived reliability. This helps the model focus on the more "trustworthy" examples and learn a robust representation, while also maintaining a balanced representation of different classes.
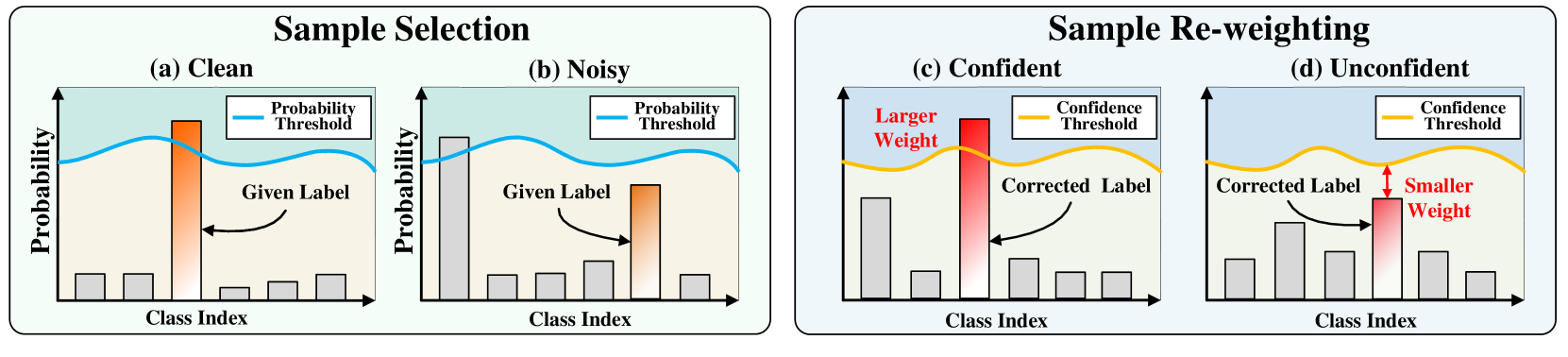
The self-adaptive sample selection and re-weighting mechanism in FAB allows the model to dynamically adjust its attention to different training samples, giving more emphasis to examples that are likely to have correct labels and less emphasis to those that are potentially noisy. This helps the model adapt to the noisy label distribution and learn more effectively.
Additionally, the class-balanced training aspect of FAB ensures that the model learns a well-rounded representation, not just focusing on the majority classes but also paying attention to the minority classes. This is important, as real-world data often exhibits class imbalance, and neglecting the minority classes can lead to suboptimal model performance.
The experimental results presented in the paper demonstrate the effectiveness of the FAB approach on various benchmark datasets with noisy labels. The model is able to achieve better performance compared to other state-of-the-art methods, highlighting the potential of this approach for real-world applications where label noise is a common challenge.
Technical Explanation
The Foster Adaptivity and Balance (FAB) method proposed in this paper addresses the problem of training machine learning models with noisy labels. The key components of the approach are:
-
Self-adaptive Sample Selection and Re-weighting: The model dynamically adjusts the importance, or weight, assigned to each training sample during the learning process. Samples that are more likely to have correct labels are given higher weights, while those with potentially noisy labels are downweighted. This self-adaptive mechanism allows the model to focus on the more reliable examples and learn a robust representation.
-
Class-balanced Training: To address class imbalance, the FAB method incorporates a class-balanced training strategy. This ensures that the model pays attention to all classes, including the minority classes, during the learning process. This class-balanced training helps the model learn a more balanced and comprehensive representation.
The experimental evaluation of the FAB approach is conducted on various benchmark datasets with noisy labels. The results demonstrate that the FAB method outperforms other state-of-the-art approaches in terms of model performance. This highlights the effectiveness of the self-adaptive sample selection and re-weighting, as well as the class-balanced training, in addressing the challenges posed by noisy labels and class imbalance.
Critical Analysis
The FAB approach presented in the paper addresses an important problem in machine learning, namely training models with noisy labels. The proposed method's ability to adaptively select and re-weight training samples, along with its class-balanced training strategy, is a promising approach to improving model performance in the presence of label noise.
One potential limitation of the FAB method is that it may require additional computational resources and training time compared to simpler approaches, as the self-adaptive sample selection and re-weighting mechanisms add complexity to the learning process. Additionally, the effectiveness of the FAB method may depend on the specific characteristics of the dataset and the nature of the label noise, and its performance may vary across different scenarios.
Further research could explore ways to improve the efficiency of the FAB approach or investigate its robustness to different types of label noise. Additionally, it would be valuable to investigate the practical applicability of the FAB method in real-world scenarios, where the label noise characteristics may be more complex and diverse.
Conclusion
The Foster Adaptivity and Balance (FAB) approach proposed in this paper provides a promising solution for training effective machine learning models in the presence of noisy labels. By incorporating self-adaptive sample selection and re-weighting mechanisms, as well as class-balanced training, the FAB method demonstrates the ability to improve model performance on various benchmark datasets with noisy labels.
The experimental results presented in the paper highlight the potential of the FAB approach for real-world applications, where label noise and class imbalance are common challenges. Further research into the efficiency and robustness of the FAB method, as well as its practical applicability, could help advance the field of machine learning and enable the development of more reliable and robust models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Foster Adaptivity and Balance in Learning with Noisy Labels
Mengmeng Sheng, Zeren Sun, Tao Chen, Shuchao Pang, Yucheng Wang, Yazhou Yao
Label noise is ubiquitous in real-world scenarios, posing a practical challenge to supervised models due to its effect in hurting the generalization performance of deep neural networks. Existing methods primarily employ the sample selection paradigm and usually rely on dataset-dependent prior knowledge (eg, a pre-defined threshold) to cope with label noise, inevitably degrading the adaptivity. Moreover, existing methods tend to neglect the class balance in selecting samples, leading to biased model performance. To this end, we propose a simple yet effective approach named textbf{SED} to deal with label noise in a textbf{S}elf-adaptivtextbf{E} and class-balancetextbf{D} manner. Specifically, we first design a novel sample selection strategy to empower self-adaptivity and class balance when identifying clean and noisy data. A mean-teacher model is then employed to correct labels of noisy samples. Subsequently, we propose a self-adaptive and class-balanced sample re-weighting mechanism to assign different weights to detected noisy samples. Finally, we additionally employ consistency regularization on selected clean samples to improve model generalization performance. Extensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method. The source code has been made available at https://github.com/NUST-Machine-Intelligence-Laboratory/SED.
Read more7/4/2024

0
Distribution-Aware Robust Learning from Long-Tailed Data with Noisy Labels
Jae Soon Baik, In Young Yoon, Kun Hoon Kim, Jun Won Choi
Deep neural networks have demonstrated remarkable advancements in various fields using large, well-annotated datasets. However, real-world data often exhibit long-tailed distributions and label noise, significantly degrading generalization performance. Recent studies addressing these issues have focused on noisy sample selection methods that estimate the centroid of each class based on high-confidence samples within each target class. The performance of these methods is limited because they use only the training samples within each class for class centroid estimation, making the quality of centroids susceptible to long-tailed distributions and noisy labels. In this study, we present a robust training framework called Distribution-aware Sample Selection and Contrastive Learning (DaSC). Specifically, DaSC introduces a Distribution-aware Class Centroid Estimation (DaCC) to generate enhanced class centroids. DaCC performs weighted averaging of the features from all samples, with weights determined based on model predictions. Additionally, we propose a confidence-aware contrastive learning strategy to obtain balanced and robust representations. The training samples are categorized into high-confidence and low-confidence samples. Our method then applies Semi-supervised Balanced Contrastive Loss (SBCL) using high-confidence samples, leveraging reliable label information to mitigate class bias. For the low-confidence samples, our method computes Mixup-enhanced Instance Discrimination Loss (MIDL) to improve their representations in a self-supervised manner. Our experimental results on CIFAR and real-world noisy-label datasets demonstrate the superior performance of the proposed DaSC compared to previous approaches.
Read more7/25/2024

0
Extracting Clean and Balanced Subset for Noisy Long-tailed Classification
Zhuo Li, He Zhao, Zhen Li, Tongliang Liu, Dandan Guo, Xiang Wan
Real-world datasets usually are class-imbalanced and corrupted by label noise. To solve the joint issue of long-tailed distribution and label noise, most previous works usually aim to design a noise detector to distinguish the noisy and clean samples. Despite their effectiveness, they may be limited in handling the joint issue effectively in a unified way. In this work, we develop a novel pseudo labeling method using class prototypes from the perspective of distribution matching, which can be solved with optimal transport (OT). By setting a manually-specific probability measure and using a learned transport plan to pseudo-label the training samples, the proposed method can reduce the side-effects of noisy and long-tailed data simultaneously. Then we introduce a simple yet effective filter criteria by combining the observed labels and pseudo labels to obtain a more balanced and less noisy subset for a robust model training. Extensive experiments demonstrate that our method can extract this class-balanced subset with clean labels, which brings effective performance gains for long-tailed classification with label noise.
Read more4/11/2024

0
Active Label Refinement for Robust Training of Imbalanced Medical Image Classification Tasks in the Presence of High Label Noise
Bidur Khanal, Tianhong Dai, Binod Bhattarai, Cristian Linte
The robustness of supervised deep learning-based medical image classification is significantly undermined by label noise. Although several methods have been proposed to enhance classification performance in the presence of noisy labels, they face some challenges: 1) a struggle with class-imbalanced datasets, leading to the frequent overlooking of minority classes as noisy samples; 2) a singular focus on maximizing performance using noisy datasets, without incorporating experts-in-the-loop for actively cleaning the noisy labels. To mitigate these challenges, we propose a two-phase approach that combines Learning with Noisy Labels (LNL) and active learning. This approach not only improves the robustness of medical image classification in the presence of noisy labels, but also iteratively improves the quality of the dataset by relabeling the important incorrect labels, under a limited annotation budget. Furthermore, we introduce a novel Variance of Gradients approach in LNL phase, which complements the loss-based sample selection by also sampling under-represented samples. Using two imbalanced noisy medical classification datasets, we demonstrate that that our proposed technique is superior to its predecessors at handling class imbalance by not misidentifying clean samples from minority classes as mostly noisy samples.
Read more7/9/2024