Foundation Models for Autonomous Robots in Unstructured Environments

0
🔍
Sign in to get full access
Overview
- This study investigates the potential opportunities and challenges of using pretrained foundation models, such as Large Language Models (LLMs), to introduce robots into unstructured environments like construction sites.
- Robots have been widely adopted in structured settings like manufacturing, but their use in unstructured environments has been limited due to the unpredictable nature of these environments.
- The study reviews the application of foundation models in robotics and unstructured environments, and then synthesizes these findings with deliberative acting theory.
Plain English Explanation
The paper explores how pretrained foundation models could help bring robots into more unpredictable settings, like construction sites, where they've struggled to be widely adopted. Robots have been very successful in structured environments, like manufacturing, where their actions can be carefully programmed or trained on specific datasets. But in messy, unpredictable environments, robots often can't handle all the unexpected situations that come up.
The researchers looked at how foundation models, which are AI systems trained on huge amounts of data to be very versatile, could help robots better navigate these unstructured settings. They reviewed examples of foundation models being used in robotics and unstructured environments, like for improved perception in human-robot interactions or for project management and safety in construction.
Overall, the researchers found that foundation models show promise for helping robots operate in messy, unpredictable environments, but there are still significant challenges to overcome before we see widespread adoption. Their analysis suggests robots using foundation models are currently at a "conditional automation" level, meaning they can handle some unexpected situations but still need significant human oversight. The researchers outline a vision for how to keep pushing towards truly autonomous, safe robots in unstructured settings.
Technical Explanation
The paper systematically reviews the application of pretrained foundation models, such as Large Language Models (LLMs), in the fields of robotics and unstructured environments. It then synthesizes these findings with deliberative acting theory to assess the current state-of-the-art and envision future scenarios.
The review found that the linguistic capabilities of LLMs have been leveraged more than other features for improving perception in human-robot interactions. On the other hand, the use of LLMs has demonstrated more applications in project management and safety in construction, as well as natural hazard detection in disaster management.
By synthesizing these findings, the researchers locate the current state-of-the-art on a five-level scale of automation, placing foundation model-enabled robots at the "conditional automation" level. This means they can handle some unpredictable events, but still require significant human oversight. The paper then uses this assessment to envision future scenarios, challenges, and solutions toward achieving truly autonomous, safe operation in unstructured environments.
Critical Analysis
The paper provides a comprehensive review of the current applications of pretrained foundation models in robotics and unstructured environments. However, it also acknowledges the significant challenges that remain before we see widespread adoption of these technologies.
One key limitation noted is the gap between the linguistic capabilities of LLMs and the need for robust physical interaction and manipulation in unstructured settings. While foundation models excel at tasks like natural language processing, transferring that versatility to complex real-world robot behaviors is an ongoing challenge.
The paper also highlights the need for further research into areas like safety, reliability, and generalization before foundation model-powered robots can be truly autonomous in unstructured environments. Addressing these issues will be crucial for realizing the researchers' vision of safe, reliable robots operating in unpredictable settings.
Conclusion
This study provides a comprehensive assessment of the potential for pretrained foundation models to enable robots to operate in unstructured environments. While the findings suggest these models show promise, significant challenges remain before we see widespread adoption.
The researchers' analysis places current foundation model-powered robots at a "conditional automation" level, able to handle some unpredictable events but still requiring substantial human oversight. Achieving the researchers' vision of truly autonomous, safe robots in messy, real-world settings will require further advancements in areas like physical interaction, safety, and generalization.
Overall, this paper serves as an important benchmark for tracking progress towards that future, highlighting both the exciting potential and the considerable work still to be done in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Foundation Models for Autonomous Robots in Unstructured Environments
Hossein Naderi, Alireza Shojaei, Lifu Huang
Automating activities through robots in unstructured environments, such as construction sites, has been a long-standing desire. However, the high degree of unpredictable events in these settings has resulted in far less adoption compared to more structured settings, such as manufacturing, where robots can be hard-coded or trained on narrowly defined datasets. Recently, pretrained foundation models, such as Large Language Models (LLMs), have demonstrated superior generalization capabilities by providing zero-shot solutions for problems do not present in the training data, proposing them as a potential solution for introducing robots to unstructured environments. To this end, this study investigates potential opportunities and challenges of pretrained foundation models from a multi-dimensional perspective. The study systematically reviews application of foundation models in two field of robotic and unstructured environment and then synthesized them with deliberative acting theory. Findings showed that linguistic capabilities of LLMs have been utilized more than other features for improving perception in human-robot interactions. On the other hand, findings showed that the use of LLMs demonstrated more applications in project management and safety in construction, and natural hazard detection in disaster management. Synthesizing these findings, we located the current state-of-the-art in this field on a five-level scale of automation, placing them at conditional automation. This assessment was then used to envision future scenarios, challenges, and solutions toward autonomous safe unstructured environments. Our study can be seen as a benchmark to track our progress toward that future.
Read more7/23/2024
0
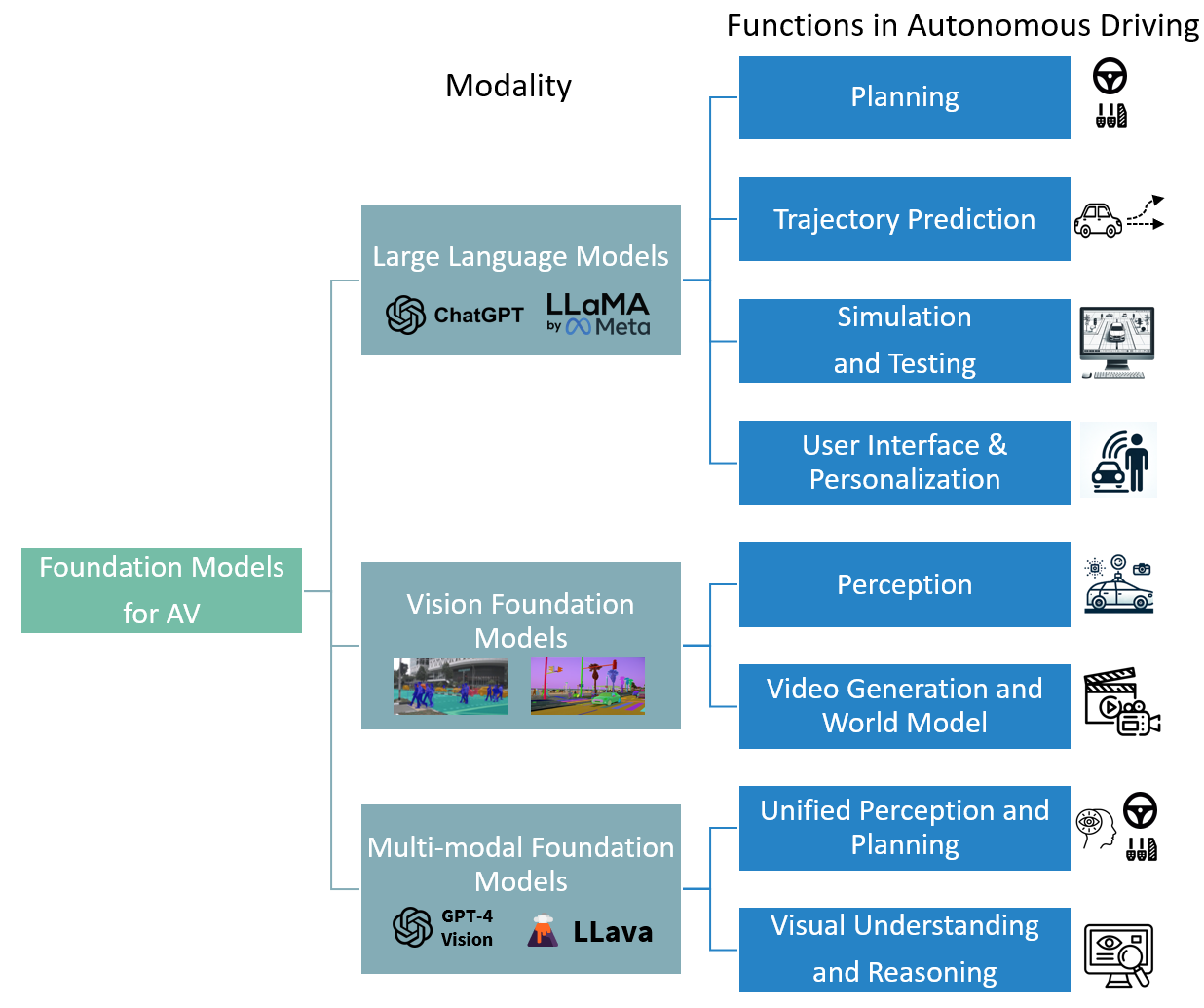
A Survey for Foundation Models in Autonomous Driving
Haoxiang Gao, Zhongruo Wang, Yaqian Li, Kaiwen Long, Ming Yang, Yiqing Shen
The advent of foundation models has revolutionized the fields of natural language processing and computer vision, paving the way for their application in autonomous driving (AD). This survey presents a comprehensive review of more than 40 research papers, demonstrating the role of foundation models in enhancing AD. Large language models contribute to planning and simulation in AD, particularly through their proficiency in reasoning, code generation and translation. In parallel, vision foundation models are increasingly adapted for critical tasks such as 3D object detection and tracking, as well as creating realistic driving scenarios for simulation and testing. Multi-modal foundation models, integrating diverse inputs, exhibit exceptional visual understanding and spatial reasoning, crucial for end-to-end AD. This survey not only provides a structured taxonomy, categorizing foundation models based on their modalities and functionalities within the AD domain but also delves into the methods employed in current research. It identifies the gaps between existing foundation models and cutting-edge AD approaches, thereby charting future research directions and proposing a roadmap for bridging these gaps.
Read more9/6/2024
🌿
0
What Foundation Models can Bring for Robot Learning in Manipulation : A Survey
Dingzhe Li, Yixiang Jin, Yong A, Hongze Yu, Jun Shi, Xiaoshuai Hao, Peng Hao, Huaping Liu, Fuchun Sun, Jianwei Zhang, Bin Fang
The realization of universal robots is an ultimate goal of researchers. However, a key hurdle in achieving this goal lies in the robots' ability to manipulate objects in their unstructured surrounding environments according to different tasks. The learning-based approach is considered an effective way to address generalization. The impressive performance of foundation models in the fields of computer vision and natural language suggests the potential of embedding foundation models into manipulation tasks as a viable path toward achieving general manipulation capability. However, we believe achieving general manipulation capability requires an overarching framework akin to auto driving. This framework should encompass multiple functional modules, with different foundation models assuming distinct roles in facilitating general manipulation capability. This survey focuses on the contributions of foundation models to robot learning for manipulation. We propose a comprehensive framework and detail how foundation models can address challenges in each module of the framework. What's more, we examine current approaches, outline challenges, suggest future research directions, and identify potential risks associated with integrating foundation models into this domain.
Read more8/12/2024
0
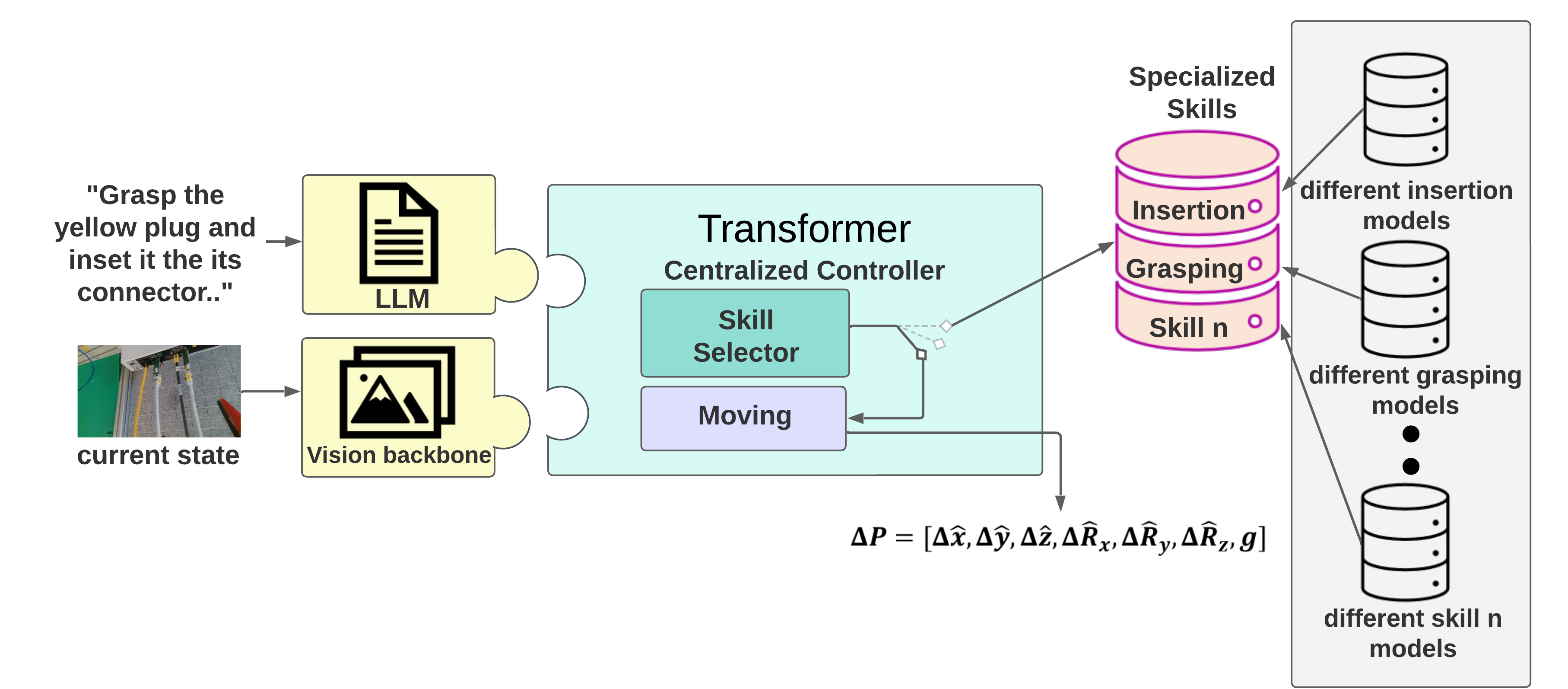
Towards Natural Language-Driven Assembly Using Foundation Models
Omkar Joglekar, Tal Lancewicki, Shir Kozlovsky, Vladimir Tchuiev, Zohar Feldman, Dotan Di Castro
Large Language Models (LLMs) and strong vision models have enabled rapid research and development in the field of Vision-Language-Action models that enable robotic control. The main objective of these methods is to develop a generalist policy that can control robots with various embodiments. However, in industrial robotic applications such as automated assembly and disassembly, some tasks, such as insertion, demand greater accuracy and involve intricate factors like contact engagement, friction handling, and refined motor skills. Implementing these skills using a generalist policy is challenging because these policies might integrate further sensory data, including force or torque measurements, for enhanced precision. In our method, we present a global control policy based on LLMs that can transfer the control policy to a finite set of skills that are specifically trained to perform high-precision tasks through dynamic context switching. The integration of LLMs into this framework underscores their significance in not only interpreting and processing language inputs but also in enriching the control mechanisms for diverse and intricate robotic operations.
Read more6/26/2024