Fractal Patterns May Illuminate the Success of Next-Token Prediction

3

Sign in to get full access
Overview
- Explores the fractal structure of language and its potential insights for understanding the intelligence behind next-token prediction in large language models (LLMs)
- Investigates the self-similarity, long-range dependence, and scaling laws observed in language data, suggesting it may hold the key to unraveling the inner workings of LLMs
- Proposes that the fractal patterns in language could provide a new lens for probing the mechanisms underlying the impressive performance of LLMs on language tasks
Plain English Explanation
Fractal patterns are intricate shapes that repeat at different scales, like the branching patterns of a tree or the swirls in a seashell. This research paper explores whether language itself might have a fractal-like structure, with patterns that repeat across different levels - from individual words to entire paragraphs and documents.
The idea is that if language does exhibit these fractal characteristics, it could offer valuable insights into how large language models (LLMs) - the powerful AI systems behind technologies like chatbots and language translation - are able to predict the next word in a sequence with such impressive accuracy. Just as fractals reveal deep mathematical patterns in nature, the fractal structure of language may uncover the underlying "intelligence" that allows LLMs to generate coherent and contextually appropriate text.
By analyzing vast troves of text data, the researchers looked for signs of self-similarity, long-range dependencies, and scaling laws - all hallmarks of fractal patterns. Their findings suggest that language does indeed have a fractal-like organization, with statistical properties that remain consistent across different scales. This could mean that the brain-like networks of LLMs are tapping into these same deep patterns when predicting the next word in a sentence.
Ultimately, the researchers propose that studying the fractal nature of language could provide a new and powerful lens for understanding the inner workings of LLMs - how they are able to capture the complexities of human communication and generate such convincingly "intelligent" text. This could lead to breakthroughs in AI technology, as well as shed light on the fundamental nature of human language and cognition.
Technical Explanation
The paper investigates the fractal structure of language and its potential implications for understanding the intelligence behind next-token prediction in large language models (LLMs). The researchers analyzed vast datasets of text to identify signs of self-similarity, long-range dependence, and scaling laws - all hallmarks of fractal patterns.
Their analysis revealed that language does indeed exhibit fractal-like statistical properties that remain consistent across different scales, from individual words to entire documents. This suggests that the complex, hierarchical structure of language may be underpinned by deep mathematical patterns akin to those observed in natural fractals.
The researchers propose that these fractal characteristics of language could provide a new lens for probing the mechanisms underlying the impressive performance of LLMs on language tasks. Just as the fractal nature of natural systems has revealed fundamental insights, the fractal structure of language may hold the key to unraveling the "intelligence" that allows LLMs to predict the next token in a sequence with such accuracy.
The paper also explores potential fingerprints left by the fractal-like organization of language within the internal representations of LLMs, suggesting that these patterns could be used to probe the linguistic structure learned by these models. This could lead to a better understanding of how LLMs capture the complexities of human communication and generate such convincingly "intelligent" text.
Critical Analysis
The paper presents a compelling hypothesis about the fractal structure of language and its potential significance for understanding the inner workings of large language models. The researchers provide a thorough analysis of the statistical properties of language data, demonstrating the presence of self-similarity, long-range dependence, and scaling laws - all hallmarks of fractal patterns.
However, the paper does not delve deeply into the specific mechanisms by which the fractal structure of language might influence or be encoded within the neural networks of LLMs. While the researchers speculate that these patterns could offer a new lens for probing the models' internal representations, the paper lacks a clear, testable framework for how such an analysis might be conducted.
Additionally, the paper does not address potential limitations or caveats of the fractal approach. For instance, it remains to be seen whether the observed fractal patterns in language hold true across different languages, genres, or domains, or whether they are robust to variations in data preprocessing and analysis techniques.
Further research will be needed to fully establish the connections between the fractal structure of language and the inner workings of large language models. This could involve more detailed investigations of the linguistic structure learned by LLMs, as well as experiments that directly test the utility of fractal-based approaches for probing and understanding these models.
Conclusion
This paper presents a compelling hypothesis about the fractal structure of language and its potential implications for understanding the intelligence behind next-token prediction in large language models. The researchers provide evidence that language exhibits statistical properties consistent with fractal patterns, suggesting that the complex, hierarchical structure of human communication may be underpinned by deep mathematical regularities.
If further research supports the researchers' claims, this could open up a new and powerful lens for probing the inner workings of LLMs and shedding light on the fundamental nature of human language and cognition. By uncovering the fractal patterns that may be encoded within these models, we may gain valuable insights into the mechanisms underlying their impressive performance on a wide range of language tasks.
Ultimately, this work underscores the importance of interdisciplinary approaches to understanding the capabilities and limitations of large language models, drawing on insights from fields as diverse as mathematics, cognitive science, and computer science. As AI systems become increasingly sophisticated and ubiquitous, such holistic perspectives will be crucial for ensuring that these technologies are developed and deployed in a responsible and beneficial manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
3
Fractal Patterns May Illuminate the Success of Next-Token Prediction
Ibrahim Alabdulmohsin, Vinh Q. Tran, Mostafa Dehghani
We study the fractal structure of language, aiming to provide a precise formalism for quantifying properties that may have been previously suspected but not formally shown. We establish that language is: (1) self-similar, exhibiting complexities at all levels of granularity, with no particular characteristic context length, and (2) long-range dependent (LRD), with a Hurst parameter of approximately H=0.7. Based on these findings, we argue that short-term patterns/dependencies in language, such as in paragraphs, mirror the patterns/dependencies over larger scopes, like entire documents. This may shed some light on how next-token prediction can capture the structure of text across multiple levels of granularity, from words and clauses to broader contexts and intents. In addition, we carry out an extensive analysis across different domains and architectures, showing that fractal parameters are robust. Finally, we demonstrate that the tiny variations in fractal parameters seen across LLMs improve upon perplexity-based bits-per-byte (BPB) in predicting their downstream performance. We hope these findings offer a fresh perspective on language and the mechanisms underlying the success of LLMs.
Read more5/24/2024

0
Towards a theory of how the structure of language is acquired by deep neural networks
Francesco Cagnetta, Matthieu Wyart
How much data is required to learn the structure of a language via next-token prediction? We study this question for synthetic datasets generated via a Probabilistic Context-Free Grammar (PCFG) -- a tree-like generative model that captures many of the hierarchical structures found in natural languages. We determine token-token correlations analytically in our model and show that they can be used to build a representation of the grammar's hidden variables, the longer the range the deeper the variable. In addition, a finite training set limits the resolution of correlations to an effective range, whose size grows with that of the training set. As a result, a Language Model trained with increasingly many examples can build a deeper representation of the grammar's structure, thus reaching good performance despite the high dimensionality of the problem. We conjecture that the relationship between training set size and effective range of correlations holds beyond our synthetic datasets. In particular, our conjecture predicts how the scaling law for the test loss behaviour with training set size depends on the length of the context window, which we confirm empirically in Shakespeare's plays and Wikipedia articles.
Read more9/4/2024
🔎
65
Auto-Regressive Next-Token Predictors are Universal Learners
Eran Malach
Large language models display remarkable capabilities in logical and mathematical reasoning, allowing them to solve complex tasks. Interestingly, these abilities emerge in networks trained on the simple task of next-token prediction. In this work, we present a theoretical framework for studying auto-regressive next-token predictors. We demonstrate that even simple models such as linear next-token predictors, trained on Chain-of-Thought (CoT) data, can approximate any function efficiently computed by a Turing machine. We introduce a new complexity measure -- length complexity -- which measures the number of intermediate tokens in a CoT sequence required to approximate some target function, and analyze the interplay between length complexity and other notions of complexity. Finally, we show experimentally that simple next-token predictors, such as linear networks and shallow Multi-Layer Perceptrons (MLPs), display non-trivial performance on text generation and arithmetic tasks. Our results demonstrate that the power of today's LLMs can be attributed, to a great extent, to the auto-regressive next-token training scheme, and not necessarily to a particular choice of architecture.
Read more7/31/2024
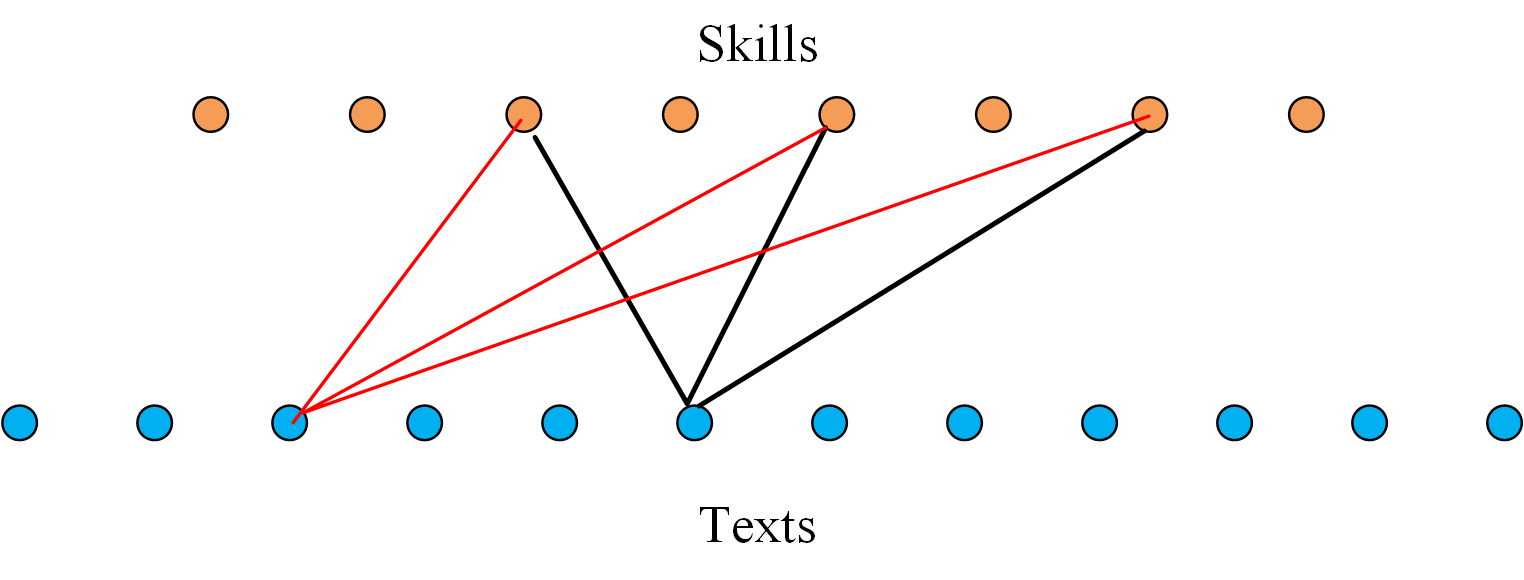
0
A Mathematical Theory for Learning Semantic Languages by Abstract Learners
Kuo-Yu Liao, Cheng-Shang Chang, Y. -W. Peter Hong
Recent advances in Large Language Models (LLMs) have demonstrated the emergence of capabilities (learned skills) when the number of system parameters and the size of training data surpass certain thresholds. The exact mechanisms behind such phenomena are not fully understood and remain a topic of active research. Inspired by the skill-text bipartite graph model proposed by Arora and Goyal for modeling semantic languages, we develop a mathematical theory to explain the emergence of learned skills, taking the learning (or training) process into account. Our approach models the learning process for skills in the skill-text bipartite graph as an iterative decoding process in Low-Density Parity Check (LDPC) codes and Irregular Repetition Slotted ALOHA (IRSA). Using density evolution analysis, we demonstrate the emergence of learned skills when the ratio of the number of training texts to the number of skills exceeds a certain threshold. Our analysis also yields a scaling law for testing errors relative to this ratio. Upon completion of the training, the association of learned skills can also be acquired to form a skill association graph. We use site percolation analysis to derive the conditions for the existence of a giant component in the skill association graph. Our analysis can also be extended to the setting with a hierarchy of skills, where a fine-tuned model is built upon a foundation model. It is also applicable to the setting with multiple classes of skills and texts. As an important application, we propose a method for semantic compression and discuss its connections to semantic communication.
Read more5/17/2024