FREE: The Foundational Semantic Recognition for Modeling Environmental Ecosystems

0
👁️
Sign in to get full access
Overview
- Modeling environmental ecosystems is crucial for sustainability, but highly complex due to numerous interacting physical variables.
- Existing models often use a combination of observable features and local measurements or modeled values, which limits their generalizability.
- The paper introduces a new framework called FREE that maps environmental data to text space and uses Large Language Models (LLMs) to supplement the input features, capturing data semantics and irregularities.
- FREE is evaluated on predicting stream water temperature and annual corn yield, showing superior performance and data/computation efficiency compared to baseline methods.
Plain English Explanation
Protecting the environment is essential for the long-term health of our planet, but understanding the complex interactions between environmental factors is extremely challenging. Existing models often rely on a mix of observable data and local measurements, which can limit their usefulness in other regions or time periods.
The researchers behind this paper have developed a new approach called FREE that aims to address this problem. FREE takes environmental data and converts it into a special text-based format. It then uses advanced language models to analyze the semantics and patterns in this text, supplementing the original data.
This allows FREE to capture more of the nuances and irregularities in environmental data, leading to better predictions. The researchers tested FREE on two real-world applications: forecasting stream water temperature and predicting annual corn yields. FREE outperformed other methods and was also more efficient, requiring less data and computational power.
Overall, the FREE framework represents a promising new approach to modeling complex environmental systems, with the potential to enhance sustainability efforts by providing more accurate and widely applicable predictions.
Technical Explanation
The FREE framework maps available environmental data into a text space, converting the traditional predictive modeling task in environmental science into a semantic recognition problem. This leverages recent advances in Large Language Models (LLMs) to supplement the original input features with natural language descriptions.
By representing the environmental data in text form, FREE can capture the data semantics and irregularities that may be difficult to extract from the raw numeric features alone. The LLM component of FREE is pre-trained on simulated data generated by physics-based models, allowing it to leverage domain knowledge and enhance the model's data and computation efficiency.
The researchers evaluated FREE in two real-world applications: predicting stream water temperature in the Delaware River Basin and forecasting annual corn yield in Illinois and Iowa. FREE demonstrated superior predictive performance compared to multiple baseline methods, highlighting its ability to generalize beyond the specific study regions and time periods.
A key advantage of the FREE framework is its flexibility to incorporate newly collected observations over time. This allows the model to be continually updated, improving its long-term predictive capabilities for environmental phenomena.
Critical Analysis
The FREE framework represents a novel and promising approach to modeling complex environmental systems, addressing some of the limitations of existing methods. However, the paper does not provide a comprehensive analysis of the model's robustness and generalizability.
While the experiments demonstrate the efficacy of FREE on two specific environmental applications, it is unclear how well the framework would perform on a wider range of environmental variables and in more diverse geographical contexts. The authors acknowledge that the pre-training on simulated data may not fully capture the nuances of real-world environmental observations, and further research is needed to understand the model's limitations in this regard.
Additionally, the paper does not delve into the interpretability of the FREE framework. As environmental modeling often requires understanding the underlying drivers of the system, the ability to explain the model's predictions would be a valuable feature for practitioners and policymakers. Future work could explore techniques to improve the transparency and interpretability of the FREE framework.
Conclusion
The FREE framework introduced in this paper represents a significant advancement in the field of environmental modeling, leveraging Large Language Models to capture the complex semantics and irregularities in environmental data. By converting the predictive task into a semantic recognition problem, FREE has demonstrated superior performance in predicting stream water temperature and annual corn yield compared to traditional methods.
The flexibility of the FREE framework to incorporate new observations over time, as well as its data and computation efficiency, suggest that it has the potential to enable more accurate and widely applicable models for environmental sustainability. As the world grapples with the pressing challenges of climate change and resource management, tools like FREE could play a crucial role in informing policymakers and guiding sustainable practices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
FREE: The Foundational Semantic Recognition for Modeling Environmental Ecosystems
Shiyuan Luo, Juntong Ni, Shengyu Chen, Runlong Yu, Yiqun Xie, Licheng Liu, Zhenong Jin, Huaxiu Yao, Xiaowei Jia
Modeling environmental ecosystems is critical for the sustainability of our planet, but is extremely challenging due to the complex underlying processes driven by interactions amongst a large number of physical variables. As many variables are difficult to measure at large scales, existing works often utilize a combination of observable features and locally available measurements or modeled values as input to build models for a specific study region and time period. This raises a fundamental question in advancing the modeling of environmental ecosystems: how to build a general framework for modeling the complex relationships amongst various environmental data over space and time? In this paper, we introduce a new framework, FREE, which maps available environmental data into a text space and then converts the traditional predictive modeling task in environmental science to the semantic recognition problem. The proposed FREE framework leverages recent advances in Large Language Models (LLMs) to supplement the original input features with natural language descriptions. This facilitates capturing the data semantics and also allows harnessing the irregularities of input features. When used for long-term prediction, FREE has the flexibility to incorporate newly collected observations to enhance future prediction. The efficacy of FREE is evaluated in the context of two societally important real-world applications, predicting stream water temperature in the Delaware River Basin and predicting annual corn yield in Illinois and Iowa. Beyond the superior predictive performance over multiple baseline methods, FREE is shown to be more data- and computation-efficient as it can be pre-trained on simulated data generated by physics-based models.
Read more4/23/2024
0
LITE: Modeling Environmental Ecosystems with Multimodal Large Language Models
Haoran Li, Junqi Liu, Zexian Wang, Shiyuan Luo, Xiaowei Jia, Huaxiu Yao
The modeling of environmental ecosystems plays a pivotal role in the sustainable management of our planet. Accurate prediction of key environmental variables over space and time can aid in informed policy and decision-making, thus improving people's livelihood. Recently, deep learning-based methods have shown promise in modeling the spatial-temporal relationships for predicting environmental variables. However, these approaches often fall short in handling incomplete features and distribution shifts, which are commonly observed in environmental data due to the substantial cost of data collection and malfunctions in measuring instruments. To address these issues, we propose LITE -- a multimodal large language model for environmental ecosystems modeling. Specifically, LITE unifies different environmental variables by transforming them into natural language descriptions and line graph images. Then, LITE utilizes unified encoders to capture spatial-temporal dynamics and correlations in different modalities. During this step, the incomplete features are imputed by a sparse Mixture-of-Experts framework, and the distribution shift is handled by incorporating multi-granularity information from past observations. Finally, guided by domain instructions, a language model is employed to fuse the multimodal representations for the prediction. Our experiments demonstrate that LITE significantly enhances performance in environmental spatial-temporal prediction across different domains compared to the best baseline, with a 41.25% reduction in prediction error. This justifies its effectiveness. Our data and code are available at https://github.com/hrlics/LITE.
Read more8/13/2024
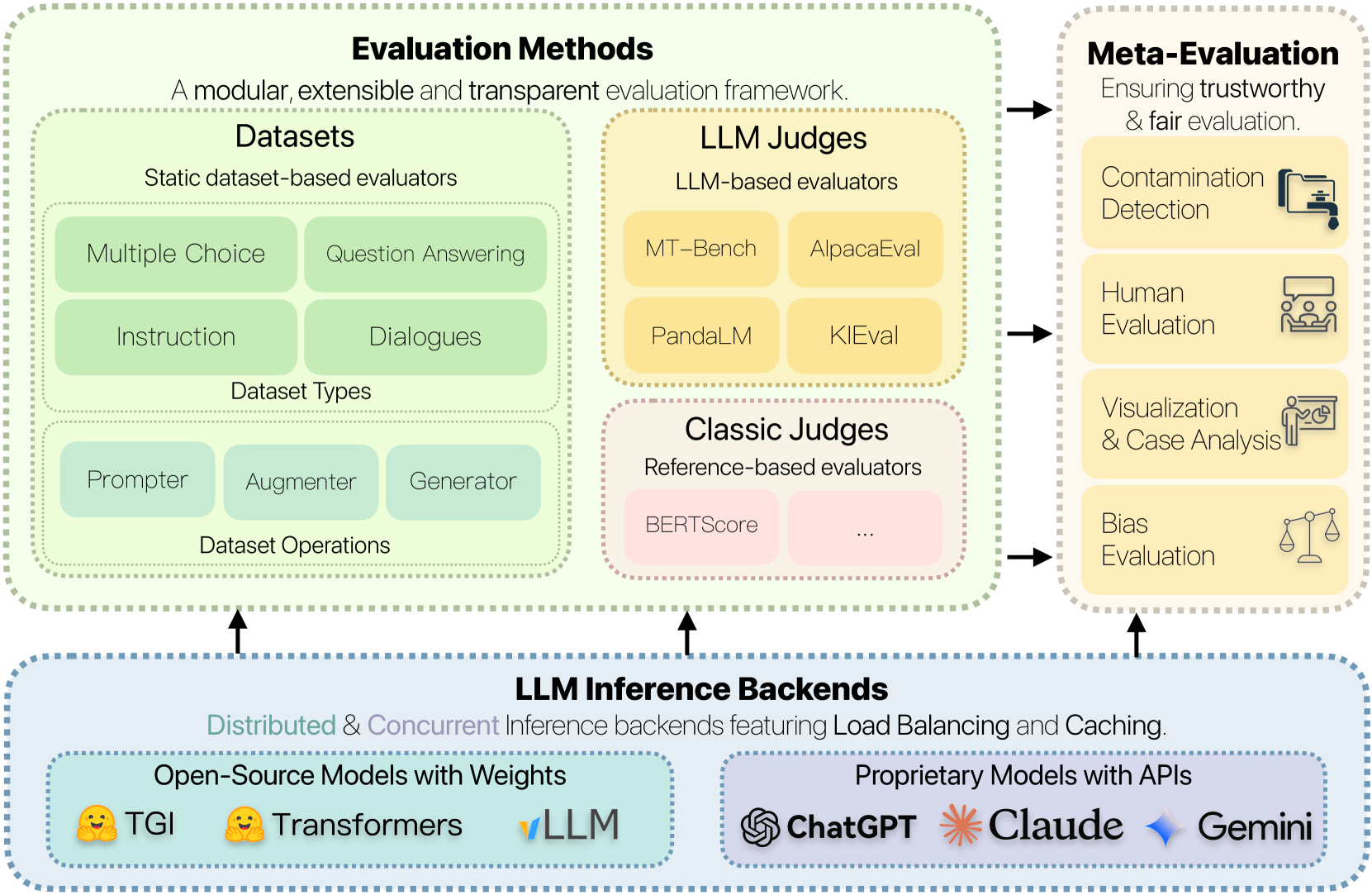
0
FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models
Zhuohao Yu, Chang Gao, Wenjin Yao, Yidong Wang, Zhengran Zeng, Wei Ye, Jindong Wang, Yue Zhang, Shikun Zhang
The rapid development of large language model (LLM) evaluation methodologies and datasets has led to a profound challenge: integrating state-of-the-art evaluation techniques cost-effectively while ensuring reliability, reproducibility, and efficiency. Currently, there is a notable absence of a unified and adaptable framework that seamlessly integrates various evaluation approaches. Moreover, the reliability of evaluation findings is often questionable due to potential data contamination, with the evaluation efficiency commonly overlooked when facing the substantial costs associated with LLM inference. In response to these challenges, we introduce FreeEval, a modular and scalable framework crafted to enable trustworthy and efficient automatic evaluations of LLMs. Firstly, FreeEval's unified abstractions simplify the integration and improve the transparency of diverse evaluation methodologies, encompassing dynamic evaluation that demand sophisticated LLM interactions. Secondly, the framework integrates meta-evaluation techniques like human evaluation and data contamination detection, which, along with dynamic evaluation modules in the platform, enhance the fairness of the evaluation outcomes. Lastly, FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies, enabling extensive evaluations across multi-node, multi-GPU clusters for open-source and proprietary LLMs.
Read more4/10/2024
🔍
0
Foundation Models for Autonomous Robots in Unstructured Environments
Hossein Naderi, Alireza Shojaei, Lifu Huang
Automating activities through robots in unstructured environments, such as construction sites, has been a long-standing desire. However, the high degree of unpredictable events in these settings has resulted in far less adoption compared to more structured settings, such as manufacturing, where robots can be hard-coded or trained on narrowly defined datasets. Recently, pretrained foundation models, such as Large Language Models (LLMs), have demonstrated superior generalization capabilities by providing zero-shot solutions for problems do not present in the training data, proposing them as a potential solution for introducing robots to unstructured environments. To this end, this study investigates potential opportunities and challenges of pretrained foundation models from a multi-dimensional perspective. The study systematically reviews application of foundation models in two field of robotic and unstructured environment and then synthesized them with deliberative acting theory. Findings showed that linguistic capabilities of LLMs have been utilized more than other features for improving perception in human-robot interactions. On the other hand, findings showed that the use of LLMs demonstrated more applications in project management and safety in construction, and natural hazard detection in disaster management. Synthesizing these findings, we located the current state-of-the-art in this field on a five-level scale of automation, placing them at conditional automation. This assessment was then used to envision future scenarios, challenges, and solutions toward autonomous safe unstructured environments. Our study can be seen as a benchmark to track our progress toward that future.
Read more7/23/2024