From Feature Importance to Natural Language Explanations Using LLMs with RAG

0
Sign in to get full access
Overview
- Explores using large language models (LLMs) with Retrieval Augmented Generation (RAG) to generate natural language explanations from feature importance values.
- Aims to bridge the gap between feature importance and human-interpretable explanations.
- Proposes a novel framework for converting feature importance into natural language.
Plain English Explanation
The research paper discusses a new approach to generating natural language explanations from the feature importance values produced by machine learning models. Feature importance is a technique used to understand which input variables (features) have the biggest impact on a model's predictions. However, these numerical feature importance values can be difficult for humans to interpret.
The researchers propose using a combination of large language models (LLMs) and Retrieval Augmented Generation (RAG) to translate the feature importance values into easy-to-understand natural language explanations. This allows the model to explain its reasoning in plain terms, rather than just providing the raw numbers.
By bridging the gap between feature importance and human-interpretable explanations, this approach can make machine learning models more transparent and trustworthy, especially for commonsense reasoning tasks where understanding the model's logic is crucial.
Technical Explanation
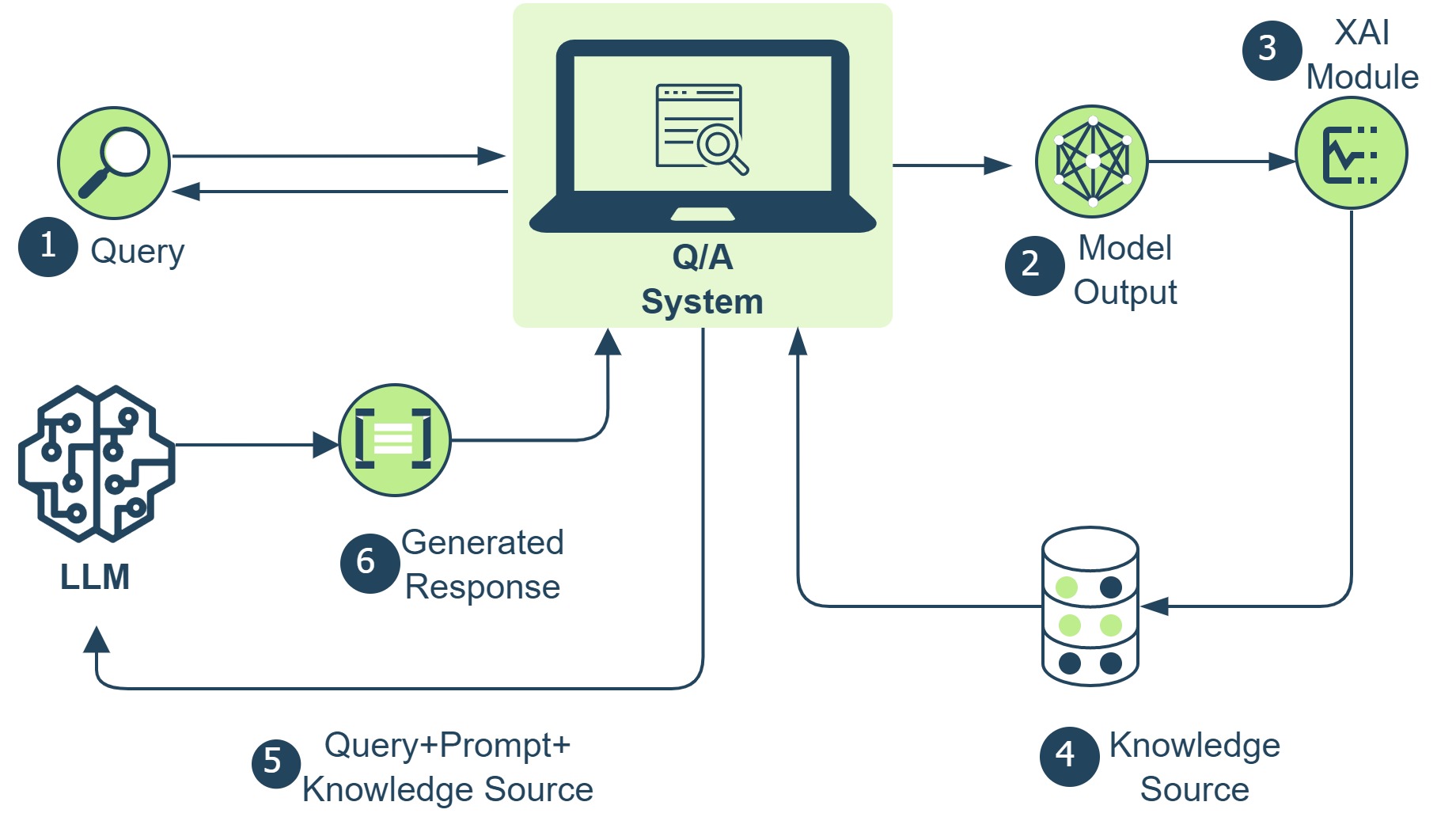
The paper introduces a novel framework for converting feature importance values into natural language explanations using LLMs and RAG. The key steps are:
- Calculating feature importance values for a given machine learning model and input.
- Retrieving relevant background information about the input features from a knowledge base using RAG.
- Generating natural language explanations that combine the feature importance values with the retrieved background information.
The researchers evaluate their approach on several benchmark datasets, showing that the generated explanations are more informative and faithful to the model's reasoning compared to baseline methods. They also explore how the framework can be adapted to different types of machine learning models and tasks.
The paper provides valuable insights into how LLMs work under the hood and demonstrates the potential for using these powerful models to bridge the gap between machine learning and human understanding.
Critical Analysis
The paper presents a promising approach, but there are a few potential limitations and areas for further research:
- The framework relies on the quality and coverage of the knowledge base used for retrieval, which may be a bottleneck in some domains.
- The generated explanations, while more natural than raw feature importance values, may still be difficult for non-technical users to fully understand.
- The paper does not explore how the framework might handle edge cases or unexpected model behavior, where the generated explanations may be misleading or incomplete.
Additionally, while the paper demonstrates the potential of LLMs and RAG for this task, further research is needed to fully understand the strengths and limitations of this approach compared to other explainability methods, such as contrastive explanation or self-explanation techniques.
Conclusion
The research paper presents an innovative framework for generating natural language explanations from feature importance values using LLMs and RAG. This approach has the potential to make machine learning models more transparent and interpretable, which is crucial for building trust and enabling commonsense reasoning in real-world applications.
While the paper highlights some promising results, further research is needed to address the limitations and explore the broader implications of this technique. As AI systems become increasingly complex, developing better methods for explaining their inner workings will be a key priority for the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
From Feature Importance to Natural Language Explanations Using LLMs with RAG
Sule Tekkesinoglu, Lars Kunze
As machine learning becomes increasingly integral to autonomous decision-making processes involving human interaction, the necessity of comprehending the model's outputs through conversational means increases. Most recently, foundation models are being explored for their potential as post hoc explainers, providing a pathway to elucidate the decision-making mechanisms of predictive models. In this work, we introduce traceable question-answering, leveraging an external knowledge repository to inform the responses of Large Language Models (LLMs) to user queries within a scene understanding task. This knowledge repository comprises contextual details regarding the model's output, containing high-level features, feature importance, and alternative probabilities. We employ subtractive counterfactual reasoning to compute feature importance, a method that entails analysing output variations resulting from decomposing semantic features. Furthermore, to maintain a seamless conversational flow, we integrate four key characteristics - social, causal, selective, and contrastive - drawn from social science research on human explanations into a single-shot prompt, guiding the response generation process. Our evaluation demonstrates that explanations generated by the LLMs encompassed these elements, indicating its potential to bridge the gap between complex model outputs and natural language expressions.
Read more7/31/2024

0
LLM-based feature generation from text for interpretable machine learning
Vojtv{e}ch Balek, Luk'av{s} S'ykora, Vil'em Sklen'ak, Tom'av{s} Kliegr
Existing text representations such as embeddings and bag-of-words are not suitable for rule learning due to their high dimensionality and absent or questionable feature-level interpretability. This article explores whether large language models (LLMs) could address this by extracting a small number of interpretable features from text. We demonstrate this process on two datasets (CORD-19 and M17+) containing several thousand scientific articles from multiple disciplines and a target being a proxy for research impact. An evaluation based on testing for the statistically significant correlation with research impact has shown that LLama 2-generated features are semantically meaningful. We consequently used these generated features in text classification to predict the binary target variable representing the citation rate for the CORD-19 dataset and the ordinal 5-class target representing an expert-awarded grade in the M17+ dataset. Machine-learning models trained on the LLM-generated features provided similar predictive performance to the state-of-the-art embedding model SciBERT for scientific text. The LLM used only 62 features compared to 768 features in SciBERT embeddings, and these features were directly interpretable, corresponding to notions such as article methodological rigor, novelty, or grammatical correctness. As the final step, we extract a small number of well-interpretable action rules. Consistently competitive results obtained with the same LLM feature set across both thematically diverse datasets show that this approach generalizes across domains.
Read more9/12/2024

0
LLM-Select: Feature Selection with Large Language Models
Daniel P. Jeong, Zachary C. Lipton, Pradeep Ravikumar
In this paper, we demonstrate a surprising capability of large language models (LLMs): given only input feature names and a description of a prediction task, they are capable of selecting the most predictive features, with performance rivaling the standard tools of data science. Remarkably, these models exhibit this capacity across various query mechanisms. For example, we zero-shot prompt an LLM to output a numerical importance score for a feature (e.g., blood pressure) in predicting an outcome of interest (e.g., heart failure), with no additional context. In particular, we find that the latest models, such as GPT-4, can consistently identify the most predictive features regardless of the query mechanism and across various prompting strategies. We illustrate these findings through extensive experiments on real-world data, where we show that LLM-based feature selection consistently achieves strong performance competitive with data-driven methods such as the LASSO, despite never having looked at the downstream training data. Our findings suggest that LLMs may be useful not only for selecting the best features for training but also for deciding which features to collect in the first place. This could potentially benefit practitioners in domains like healthcare, where collecting high-quality data comes at a high cost.
Read more7/4/2024
0
Evaluating the Reliability of Self-Explanations in Large Language Models
Korbinian Randl, John Pavlopoulos, Aron Henriksson, Tony Lindgren
This paper investigates the reliability of explanations generated by large language models (LLMs) when prompted to explain their previous output. We evaluate two kinds of such self-explanations - extractive and counterfactual - using three state-of-the-art LLMs (2B to 8B parameters) on two different classification tasks (objective and subjective). Our findings reveal, that, while these self-explanations can correlate with human judgement, they do not fully and accurately follow the model's decision process, indicating a gap between perceived and actual model reasoning. We show that this gap can be bridged because prompting LLMs for counterfactual explanations can produce faithful, informative, and easy-to-verify results. These counterfactuals offer a promising alternative to traditional explainability methods (e.g. SHAP, LIME), provided that prompts are tailored to specific tasks and checked for validity.
Read more7/22/2024