Gap Completion in Point Cloud Scene occluded by Vehicles using SGC-Net

0
🚀
Sign in to get full access
Overview
- Advances in mobile mapping systems have enabled efficient acquisition of urban 3D data using LiDAR sensors on vehicles.
- A significant challenge is the occlusion caused by roadside parked vehicles, leading to the loss of scene information on roads, sidewalks, curbs, and building lower sections.
- This study presents a novel approach that uses deep neural networks to fill gaps in urban scenes obscured by vehicle occlusion.
Plain English Explanation
The research paper discusses a new technique for reconstructing urban 3D scenes that have been partially obscured by parked vehicles. Mobile mapping systems, which use laser scanners mounted on vehicles, can capture detailed 3D data of cities. However, the presence of parked cars can create gaps and missing information in the resulting 3D models, especially on roads, sidewalks, and the lower parts of buildings.
To address this problem, the researchers developed a deep learning-based method to fill in these occluded areas. They created synthetic training data by virtually placing model cars along the roads and simulating the occlusion effects. This allowed them to train a neural network, called the Scene Gap Completion Network (SGC-Net), to generate plausible reconstructions of the missing scene elements.
The key innovation is that the SGC-Net can produce well-defined shapes and smooth surfaces within the occluded gaps, restoring the missing 3D information. This is a significant advance over previous methods, which struggled to accurately reconstruct occluded areas. The researchers' experiments show that their approach can fill in gaps with a high degree of accuracy, with 97.66% of the filled points falling within 5 centimeters of the ground truth data.
Technical Explanation
The researchers developed an innovative technique to generate diverse and realistic urban point cloud scenes with and without vehicle occlusion. They placed virtual vehicle models along road boundaries in the gap-free scene and used a ray-casting algorithm to create a new scene with occluded gaps. This approach allowed them to overcome the limitations of real-world training data collection and annotation.
The researchers then introduced the Scene Gap Completion Network (SGC-Net), an end-to-end model that can generate well-defined shape boundaries and smooth surfaces within occluded gaps. The SGC-Net architecture leverages a hierarchical feature fusion strategy to effectively capture both local and global contextual information, enabling the model to reconstruct the missing scene elements.
Experiment results revealed that 97.66% of the filled points fall within a range of 5 centimeters relative to the high-density ground truth point cloud scene. These findings demonstrate the efficacy of the proposed model in gap completion and the reconstruction of urban scenes affected by vehicle occlusions.
Critical Analysis
The researchers acknowledge that their approach is limited to vehicle occlusion and does not address other types of occlusions, such as those caused by trees or buildings. Additionally, the synthetic training data generation method may not fully capture the complexity and nuances of real-world occlusion scenarios.
While the 97.66% accuracy within a 5 cm range is impressive, it is worth considering the potential impact of these small errors on downstream applications, such as autonomous navigation or urban planning. Further research may be needed to explore the practical implications of the remaining inaccuracies.
Additionally, the SGC-Net architecture could potentially be extended or combined with other techniques, such as point cloud scene flow or 3D occupancy prediction, to further enhance its performance and robustness in handling various types of occlusions in urban 3D scene understanding.
Conclusion
This research presents a novel approach to addressing the challenge of vehicle occlusion in urban 3D data acquisition. The researchers' innovative technique for generating synthetic training data and the development of the SGC-Net model demonstrate a significant advancement in the field of scene reconstruction and gap completion. While the approach has limitations, the high accuracy of the filled points suggests that it could have important applications in areas such as autonomous navigation, urban planning, and infrastructure management. Further research to expand the method's capabilities and explore its practical implications would be valuable contributions to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
Gap Completion in Point Cloud Scene occluded by Vehicles using SGC-Net
Yu Feng, Yiming Xu, Yan Xia, Claus Brenner, Monika Sester
Recent advances in mobile mapping systems have greatly enhanced the efficiency and convenience of acquiring urban 3D data. These systems utilize LiDAR sensors mounted on vehicles to capture vast cityscapes. However, a significant challenge arises due to occlusions caused by roadside parked vehicles, leading to the loss of scene information, particularly on the roads, sidewalks, curbs, and the lower sections of buildings. In this study, we present a novel approach that leverages deep neural networks to learn a model capable of filling gaps in urban scenes that are obscured by vehicle occlusion. We have developed an innovative technique where we place virtual vehicle models along road boundaries in the gap-free scene and utilize a ray-casting algorithm to create a new scene with occluded gaps. This allows us to generate diverse and realistic urban point cloud scenes with and without vehicle occlusion, surpassing the limitations of real-world training data collection and annotation. Furthermore, we introduce the Scene Gap Completion Network (SGC-Net), an end-to-end model that can generate well-defined shape boundaries and smooth surfaces within occluded gaps. The experiment results reveal that 97.66% of the filled points fall within a range of 5 centimeters relative to the high-density ground truth point cloud scene. These findings underscore the efficacy of our proposed model in gap completion and reconstructing urban scenes affected by vehicle occlusions.
Read more7/12/2024

0
Street Gaussians: Modeling Dynamic Urban Scenes with Gaussian Splatting
Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, Sida Peng
This paper aims to tackle the problem of modeling dynamic urban streets for autonomous driving scenes. Recent methods extend NeRF by incorporating tracked vehicle poses to animate vehicles, enabling photo-realistic view synthesis of dynamic urban street scenes. However, significant limitations are their slow training and rendering speed. We introduce Street Gaussians, a new explicit scene representation that tackles these limitations. Specifically, the dynamic urban scene is represented as a set of point clouds equipped with semantic logits and 3D Gaussians, each associated with either a foreground vehicle or the background. To model the dynamics of foreground object vehicles, each object point cloud is optimized with optimizable tracked poses, along with a 4D spherical harmonics model for the dynamic appearance. The explicit representation allows easy composition of object vehicles and background, which in turn allows for scene editing operations and rendering at 135 FPS (1066 $times$ 1600 resolution) within half an hour of training. The proposed method is evaluated on multiple challenging benchmarks, including KITTI and Waymo Open datasets. Experiments show that the proposed method consistently outperforms state-of-the-art methods across all datasets. The code will be released to ensure reproducibility.
Read more8/20/2024
0
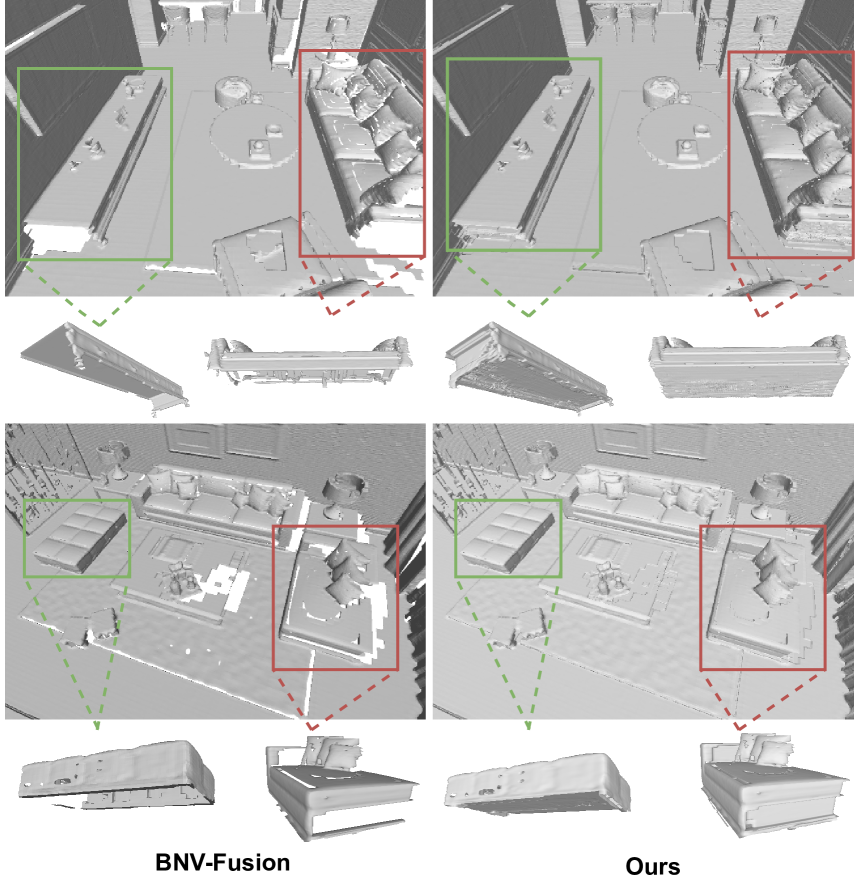
Behind the Veil: Enhanced Indoor 3D Scene Reconstruction with Occluded Surfaces Completion
Su Sun, Cheng Zhao, Yuliang Guo, Ruoyu Wang, Xinyu Huang, Yingjie Victor Chen, Liu Ren
In this paper, we present a novel indoor 3D reconstruction method with occluded surface completion, given a sequence of depth readings. Prior state-of-the-art (SOTA) methods only focus on the reconstruction of the visible areas in a scene, neglecting the invisible areas due to the occlusions, e.g., the contact surface between furniture, occluded wall and floor. Our method tackles the task of completing the occluded scene surfaces, resulting in a complete 3D scene mesh. The core idea of our method is learning 3D geometry prior from various complete scenes to infer the occluded geometry of an unseen scene from solely depth measurements. We design a coarse-fine hierarchical octree representation coupled with a dual-decoder architecture, i.e., Geo-decoder and 3D Inpainter, which jointly reconstructs the complete 3D scene geometry. The Geo-decoder with detailed representation at fine levels is optimized online for each scene to reconstruct visible surfaces. The 3D Inpainter with abstract representation at coarse levels is trained offline using various scenes to complete occluded surfaces. As a result, while the Geo-decoder is specialized for an individual scene, the 3D Inpainter can be generally applied across different scenes. We evaluate the proposed method on the 3D Completed Room Scene (3D-CRS) and iTHOR datasets, significantly outperforming the SOTA methods by a gain of 16.8% and 24.2% in terms of the completeness of 3D reconstruction. 3D-CRS dataset including a complete 3D mesh of each scene is provided at project webpage.
Read more4/5/2024
0
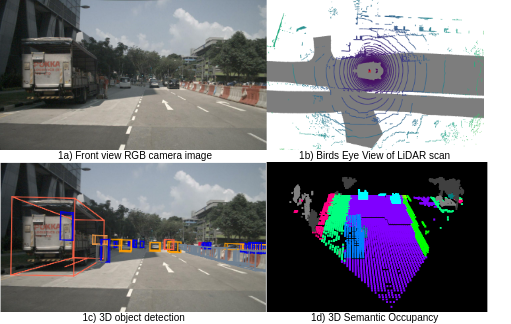
Real-time 3D semantic occupancy prediction for autonomous vehicles using memory-efficient sparse convolution
Samuel Sze, Lars Kunze
In autonomous vehicles, understanding the surrounding 3D environment of the ego vehicle in real-time is essential. A compact way to represent scenes while encoding geometric distances and semantic object information is via 3D semantic occupancy maps. State of the art 3D mapping methods leverage transformers with cross-attention mechanisms to elevate 2D vision-centric camera features into the 3D domain. However, these methods encounter significant challenges in real-time applications due to their high computational demands during inference. This limitation is particularly problematic in autonomous vehicles, where GPU resources must be shared with other tasks such as localization and planning. In this paper, we introduce an approach that extracts features from front-view 2D camera images and LiDAR scans, then employs a sparse convolution network (Minkowski Engine), for 3D semantic occupancy prediction. Given that outdoor scenes in autonomous driving scenarios are inherently sparse, the utilization of sparse convolution is particularly apt. By jointly solving the problems of 3D scene completion of sparse scenes and 3D semantic segmentation, we provide a more efficient learning framework suitable for real-time applications in autonomous vehicles. We also demonstrate competitive accuracy on the nuScenes dataset.
Read more5/21/2024