Generalization Beyond Data Imbalance: A Controlled Study on CLIP for Transferable Insights

0

Sign in to get full access
Overview
- The paper explores how the popular CLIP model, which is trained on large, imbalanced datasets, can generalize to diverse datasets and tasks beyond its original training.
- The researchers conducted a controlled study to understand the factors that contribute to CLIP's impressive generalization capabilities.
- The findings offer insights into the design and development of more robust and transferable AI models.
Plain English Explanation
The paper looks at a powerful AI model called CLIP, which has been trained on a massive amount of online data. CLIP is really good at understanding the connection between images and text, and it can be used for all sorts of tasks like image classification, captioning, and visual question answering.
One interesting thing about CLIP is that it seems to work well even on datasets that are very different from the ones it was trained on. The researchers wanted to understand why this is the case. They did a careful study to look at different factors that might be contributing to CLIP's impressive ability to generalize, or adapt, to new situations.
The insights from this study could help guide the development of future AI models that are more robust and able to work well across a wide range of applications, even when the training data is biased or imbalanced. This is an important goal, as we want AI systems that can be reliably used in the real world, where data is often messy and uneven.
Technical Explanation
The paper presents a controlled study on the CLIP model, which is a state-of-the-art vision-language model trained on a large, diverse, but imbalanced dataset. The researchers aimed to understand the factors that contribute to CLIP's strong generalization performance across various datasets and tasks, beyond the original distribution of its training data.
Through a series of experiments, the authors examined the impact of different components of the CLIP architecture and training process, such as data scaling, contrastive learning, and the use of medical imaging data. The results provide valuable insights into the design choices and training strategies that enable CLIP to learn efficient and transferable representations.
Critical Analysis
The paper offers a thoughtful and rigorous analysis of CLIP's generalization capabilities, highlighting both the strengths and limitations of the model. The controlled experiments provide a clear understanding of the factors that contribute to CLIP's performance, which is valuable for guiding the development of future vision-language models.
However, the paper also acknowledges that CLIP's generalization is not universal, and that there are still areas where the model struggles, such as with long-tailed or domain-specific datasets. Additionally, the researchers note that CLIP's training process is computationally intensive and may not be feasible for all applications.
Further research is needed to explore alternative training strategies and architectural choices that could make CLIP-like models more widely applicable and accessible. Continued investigation into the fundamental principles underlying CLIP's strong generalization will also be important for advancing the field of transferable AI.
Conclusion
The paper provides a valuable contribution to our understanding of the CLIP model and the factors that enable its impressive generalization capabilities. The insights gained from this controlled study can inform the design and development of more robust and transferable AI models, which is crucial for the widespread adoption and reliable deployment of these technologies.
By unraveling the complexities of CLIP's performance, the researchers have laid the groundwork for future advancements in vision-language modeling and cross-domain learning. As AI systems become more integral to our daily lives, this type of rigorous and thoughtful analysis will be essential for ensuring their reliability and trustworthiness.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generalization Beyond Data Imbalance: A Controlled Study on CLIP for Transferable Insights
Xin Wen, Bingchen Zhao, Yilun Chen, Jiangmiao Pang, Xiaojuan Qi
Severe data imbalance naturally exists among web-scale vision-language datasets. Despite this, we find CLIP pre-trained thereupon exhibits notable robustness to the data imbalance compared to supervised learning, and demonstrates significant effectiveness in learning generalizable representations. With an aim to investigate the reasons behind this finding, we conduct controlled experiments to study various underlying factors, and reveal that CLIP's pretext task forms a dynamic classification problem wherein only a subset of classes is present in training. This isolates the bias from dominant classes and implicitly balances the learning signal. Furthermore, the robustness and discriminability of CLIP improve with more descriptive language supervision, larger data scale, and broader open-world concepts, which are inaccessible to supervised learning. Our study not only uncovers the mechanisms behind CLIP's generalizability beyond data imbalance but also provides transferable insights for the research community. The findings are validated in both supervised and self-supervised learning, enabling models trained on imbalanced data to achieve CLIP-level performance on diverse recognition tasks. Code and data are available at: https://github.com/CVMI-Lab/clip-beyond-tail.
Read more6/17/2024

0
Rethinking Domain Adaptation and Generalization in the Era of CLIP
Ruoyu Feng, Tao Yu, Xin Jin, Xiaoyuan Yu, Lei Xiao, Zhibo Chen
In recent studies on domain adaptation, significant emphasis has been placed on the advancement of learning shared knowledge from a source domain to a target domain. Recently, the large vision-language pre-trained model, i.e., CLIP has shown strong ability on zero-shot recognition, and parameter efficient tuning can further improve its performance on specific tasks. This work demonstrates that a simple domain prior boosts CLIP's zero-shot recognition in a specific domain. Besides, CLIP's adaptation relies less on source domain data due to its diverse pre-training dataset. Furthermore, we create a benchmark for zero-shot adaptation and pseudo-labeling based self-training with CLIP. Last but not least, we propose to improve the task generalization ability of CLIP from multiple unlabeled domains, which is a more practical and unique scenario. We believe our findings motivate a rethinking of domain adaptation benchmarks and the associated role of related algorithms in the era of CLIP.
Read more7/23/2024
📊
3
Demystifying CLIP Data
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, Christoph Feichtenhofer
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.
Read more4/9/2024
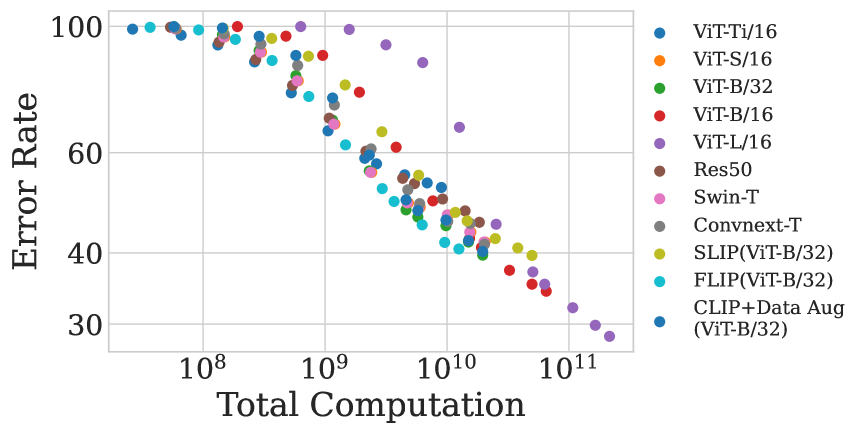
3
Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
Zichao Li, Cihang Xie, Ekin Dogus Cubuk
This paper investigates the performance of the Contrastive Language-Image Pre-training (CLIP) when scaled down to limited computation budgets. We explore CLIP along three dimensions: data, architecture, and training strategies. With regards to data, we demonstrate the significance of high-quality training data and show that a smaller dataset of high-quality data can outperform a larger dataset with lower quality. We also examine how model performance varies with different dataset sizes, suggesting that smaller ViT models are better suited for smaller datasets, while larger models perform better on larger datasets with fixed compute. Additionally, we provide guidance on when to choose a CNN-based architecture or a ViT-based architecture for CLIP training. We compare four CLIP training strategies - SLIP, FLIP, CLIP, and CLIP+Data Augmentation - and show that the choice of training strategy depends on the available compute resource. Our analysis reveals that CLIP+Data Augmentation can achieve comparable performance to CLIP using only half of the training data. This work provides practical insights into how to effectively train and deploy CLIP models, making them more accessible and affordable for practical use in various applications.
Read more4/17/2024